Introduction
This special web collection Entangled Histories: Ordinances of the Low Countries is made up of 108 books of ordinances published in the Early Modern Era in the Low Countries (Habsburg Netherlands and the Dutch Republic). All texts included in this dataset were already digitised through the Google Books Project, or through individual digitisation-projects of several libraries. The readability of these digitised books was improved by using Transkribus’ Automatic Text Recognition (OCR – Abbyy FineReader v.11; HTR-models). These HTR-models were manually trained with GroundTruth data, consequently creating fitting models for Dutch Gothic print, Dutch Roman print and French Roman print.
Due to acclaimed copyright on the digitised images, this dataset only shows you the transcriptions. These transcriptions have been saved in the formats: Alto, Page, XML, docx and txt. The Alto and Page files have been compressed in .zip files, as these consists of individual files per page.
This project consisted of three phases, which have resulted in explanatory, in-depth blogposts:
2. segmenting the books of ordinances into individual legal texts;
3. machine-learned categorisation – based upon a pre-trained set.
Acknowledgement
This dataset was created while Annemieke Romein worked as Researcher-in-Residence at the KB National Library of the Netherlands (KB) on the Entangled Histories project. During the creation process of this dataset, she was assisted by Sara Veldhoen and Michel de Gruijter of the Research Department of the KB.
The authors wish to thank Lotte Wilms, Steven Claeyssens, Martijn Kleppe, Jeroen Vandommele and Ronald Nijssen of the KB for their assistance in the creation of this dataset and making it available to the research community. Furthermore, we wish to thank Ghent University Library, Bodleian Library and Utrecht University Library for providing us with the scans of additional books.
Articles about Entangled Histories
- C.A. Romein (2019), Digital Humanities and Legal History. Can the computer read and classify ordinances? http://esclh.blogspot.com/2019/08/project-presentation-digital-humanities.html and https://lab.kb.nl/about-us/blog/digital-humanities-and-legal-history-can-computer-read-and-classify-ordinances
- C.A. Romein (2019), Digital Humanities and Legal History. Can the computer read and classify ordinances? http://esclh.blogspot.com/2019/08/project-presentation-digital-humanities.html; https://lab.kb.nl/about-us/blog/digital-humanities-and-legal-history-can-computer-read-andclassify-ordinances; 10.5281/zenodo.3551920
- C.A. Romein, S. Veldhoen, M. de Gruijter (2020), The Datafication of Early Modern Ordinances. DH Benelux Journal, 2. http://journal.dhbenelux.org/journal/issues/002/article-23-romein/article-23-romein.pdf
Presentations were given in: Brussels, Liège, Joensuu (Finland), Amsterdam, Ghent; posters in Brussels (AYLH), Oxford (DHOxSS2019), Ghent (LW-Faculty Day), Liège (DHBenelux), Utrecht (DH2019) and Frankfurt (DLH-Conference).
When using this dataset we request you to cite it as follows:
Romein, Christel Annemieke, Veldhoen, Sara, & de Gruijter, Michel. (2020). Entangled Histories: Ordinances of the Low Countries [Data set]. KB Lab: The Hague. https://lab.kb.nl/dataset/entangled-histories-ordinances-low-countries
Access
Dataset: transcriptions
The dataset consists of Alto, Page, XML, docx and txt for each book that was included in the dataset. We originally used the digitised books in PNG-format, these are not included due to copyright. Nonetheless, the Alto and Page include the coordinates to the original pages and all files have a reference to the original documents we used online.
Transcription conventions:
- The abbreviations have been written out into full words (as much as possible).
- The hyphens at the end of a line have been kept (when there).
- Text has been transcribed as is, no textual alterations have been made.
Access: transcriptions
This dataset (transcriptions) is available on Zenodo.org.
For an overview of all titles and publication dates, with links to the original scans and transcriptions on Zenodo: please see the metadata-list here.
Dataset: underlying scans
To obtain the original PNG-scans of this dataset (close to 1TB), please send an email with your request to [email protected], including the following information:
- Your name
- Affiliation/institution
- Why you would like access to the dataset
- How long you would like access
A representative of the KB will contact you and can provide access to the dataset for scientific or scholarly purposes after a contract has been signed. Please note this process can take a couple of working days before access can formally be granted.
Examples
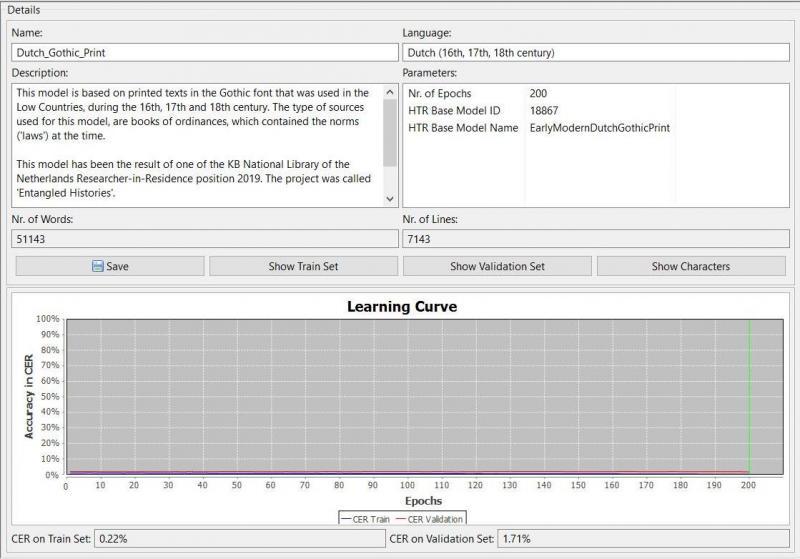
Transkribus Public Model Dutch_Gothic_Print
The HTR-model ‘Dutch_Gothic_Print’ has been based upon 51143 words Ground Truth, spread over 7143 lines. In order to create this model, another – self created – Gothic model called ‘Early Modern Dutch Gothic Print’ was used, resulting in this model with a CER of 0.22% on the test set and 1.71% on the validation set. It has been based on the sources of the ‘Entangled Histories’-project, thus: books of ordinances (legal-political texts) from the 16th, 17th and 18th century.
A sample of pages from the Gothic printed books of ordinances can be found here in the pdf-file below.
- Document
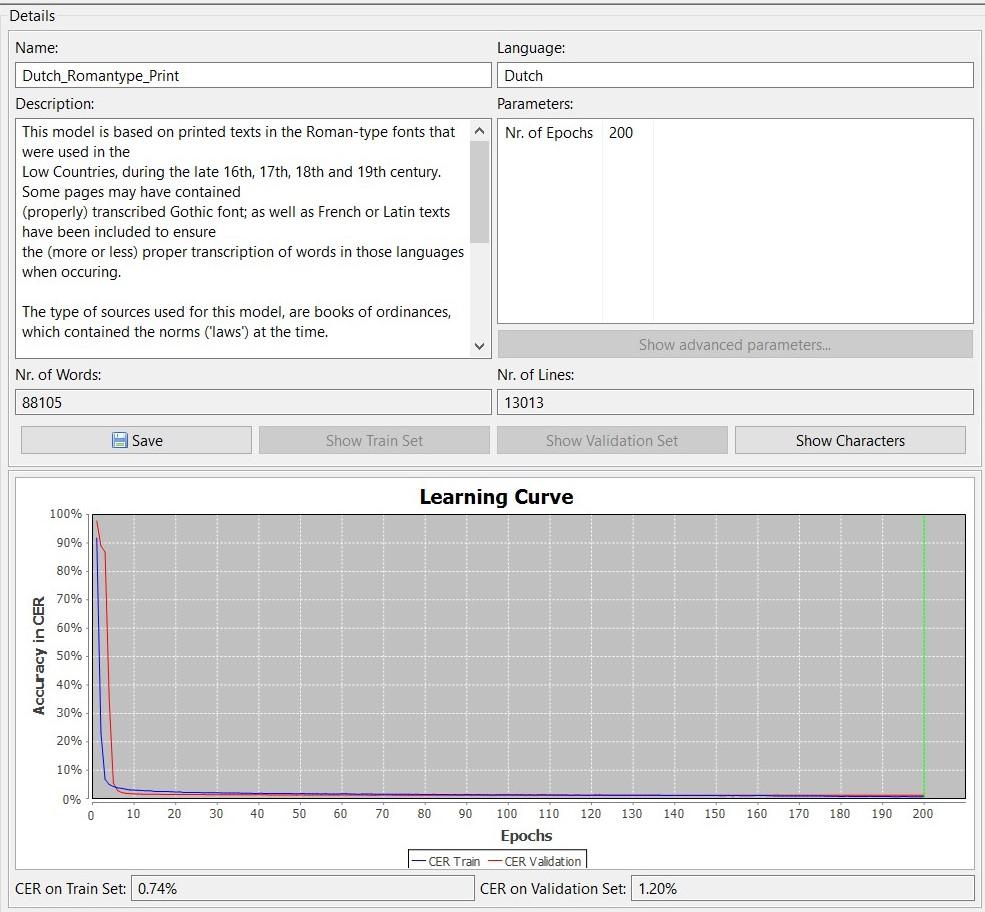
Transkribus Public Model ‘Dutch_Romantype_Print’
The HTR-model ‘Dutch_Romantype_Print’ has been based upon 88105 words Ground Truth, spread over 13013 lines. This model has a CER of 0.74% on the test set and 1.20% on the validation set. It has been based on the sources of the ‘Entangled Histories’-project, thus: books of ordinances (legal-political texts) from the 16th, 17th and 18th century.
A sample of pages from the Roman printed books of ordinances can be found here in the pdf-file below.
- DocumentTESTSET_Romein_17+18th_print.pdf (9.37 MB)
This model has been created by C. Annemieke Romein, Ronald Nijssen and Michel de Gruijter.
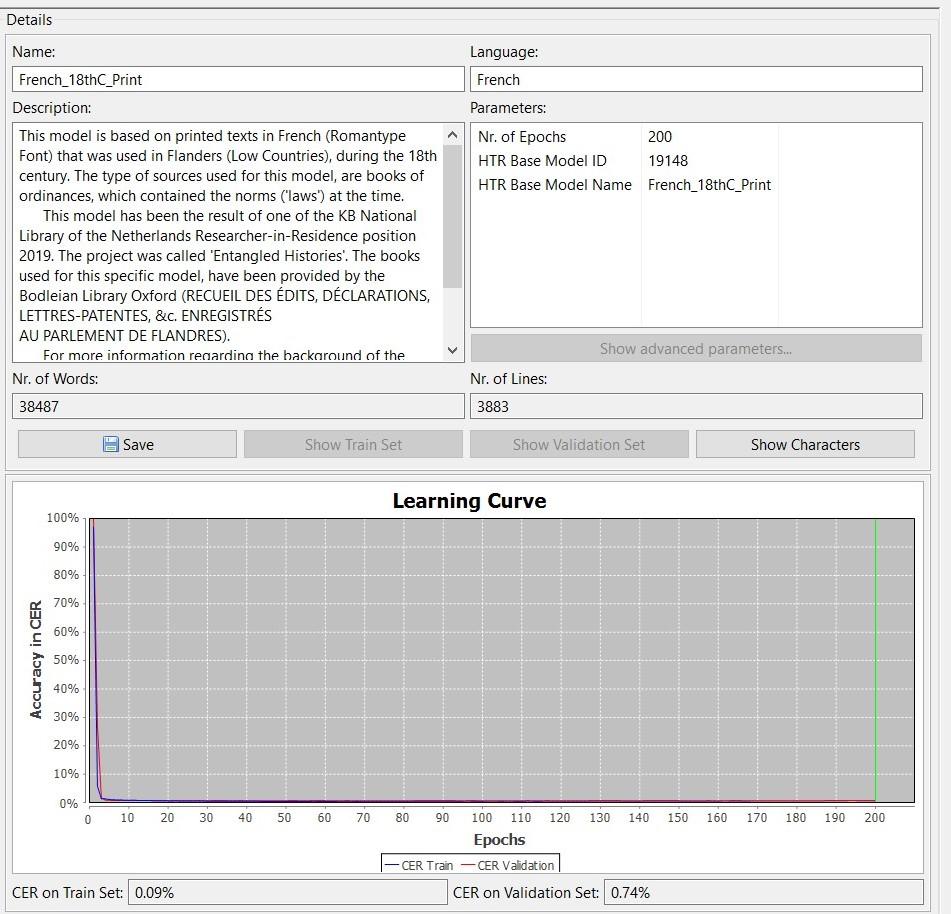
Transkribus Public Model ‘French_18thC_Print’
The HTR-model ‘French_18thC_Print’ has been based upon 38487 words Ground Truth, spread over 3883 lines. This model has a CER of 0.09% on the test set and 0.74% on the validation set. It has been based on the sources of the ‘Entangled Histories’-project, thus: books of ordinances (legal-political texts) from the 17th and mainly 18th century.
A sample of pages from the French-Roman printed books of ordinances can be found here in the pdf file below.
- DocumentTESTSET_French_18thC_printed.pdf (2.23 MB)
This model has been created by C. Annemieke Romein and Michel de Gruijter.