In my first blog (NL/EN) I described what ordinances are and why they are a very interesting topic to study. As Researcher-in-Residence at the KB, the national library of the Netherlands, I wanted to answer the following hypothesis with the Entangled Histories-project:
Early Modern European states struggled for survival, making it impossible to ‘reinvent the wheel’ each time a problem arose. Hence, it was of tremendous importance to copy, adapt and implement normative rules (aka legislation) that were already proven successful elsewhere.
In order to do so, I formulated three technical goals:
2. segmenting the books of ordinances into individual legal texts;
3. machine-learned categorisation – based upon a pre-trained set.
In this post, I want to describe the journey that ‘Entangled Histories’ – with Michel de Gruijter (project advisor), Sara Veldhoen (scientific programmer) and myself – took. The more technical details of each of these techniques are discussed in several individual blogs, which you can find by clicking on the abovementioned links. I will finish with some ideas on future steps and recommendations for future related-projects and thesis-topics.
Initial selection
Crucial to this project has been the selection of the sources. Although the books of ordinances (in Dutch: ‘plakkaatboeken’) were carefully assembled in the early modern period (±1500-1800), it is unknown how many were published, when, and where. This may seem odd for a modern-day reader and researcher, but due to many spelling varieties it is a challenge to find the books in a library-catalogue. Understandably, making a catalogue is bound by rules of precision, but it is exactly this accuracy that was in my way. This means I had to deal with the creativity of the publishers. And this creativity did not know any boundaries: in the title of the books they used placaet-boek, placcaet-boek; placcaat-boek, placaet-boeck, plakkaat-boeck, placcaet-boeck, or the word showed up without a dash or with a space instead of a dash. And they also used the word landrecht. When you have found one of the books published in a certain province, it could well be that the other volumes were published under a different spelling.
Where my initial search resulted in 54 books; we ended up working with 108 books within Entangled Histories. Of these 108 we have graciously received nine digitised books from Oxford University, and ten from Ghent University and two from the University of Utrecht. I am fully aware that this is not a complete list of books, as some books may not have been digitised until this very date. If you are curious about the list we did work with, please have a look here. (You are most welcome to suggest additional books, as I am certainly looking to complete the list. Contact me by e-mail.
Upload in Transkribus
Having a lot of documents, we needed to find a way of upload these in Transkribus to process them in an easy way. (For information on Transkribus: see my previous blog.) Uploading them one by one, would not be time-efficient and it also turned out that the version we received was a JP2000. JP2000 might be very convenient for the internet – as it is a format that offers a big compression rate without loss (so-called lossless compression).https://jpeg.org/jpeg2000/ so it allows efficient storage and transfer. Transkribus does not support JP2 files though, which is why we converted all images to PNG. Transkribus also offers the possibility to upload through FTP. That is a sort of server-modus, which is very convenient if you have larger files. It is good to realise upfront that one needs to name the documents. As a newbie in library-standards, my first idea would have been to use the book titles. However, these are very lengthy and – as said before – unstandardized. Hence, we opted for using the catalogue-numbers to ensure that we would have an easy way of referring to books. That is not to say that things are easy, because referring to numbered books can still be challenging, moreover, Transkribus adds its own identification-number which is something to keep in mind to when referring to documents.
Trial and error
Having all books in Transkribus, I started the initial Handwriting Text-Recognition-process. That meant, creating models (transcriptions in Ground Truth) for the books and test these on other pages – and other books. Initial tests were very successful and were really great. Soon CER of less than 5% were reached – which means less than 5 in 100 characters were wrongly recognised. As our percentage dropped to about 2%, it is about as good as humans would do when they would re-type the text. That does not mean that these models would perform well on all pages and documents – there could still be a case of overfitting – but at least we were able to apply these to the texts already. (More about overfitting can be found in the blogpost on HTR).
Where I had assumed that lay-out (LA) analysis and the tagging of the LA – that is, telling whether something is a title, a paragraph, page number, header or footer – would be additional information that could be supplemented; it turned out that this was something we should have started out with. That was a bit of a bummer, as it meant that documents where we had already prepared pages of Ground Truth for, were depleted of their information as I had to draw boxes and label these prior to the HTR. Moreover, I had the hope that – since I can clearly see that the title is bold, underlined, italic or well-spaced – the computer could see this too. It did not. We have tried several tools – including the Page to Page Lay-out Analysis tool (P2PaLA) that Transkribus incorporates, the analysis that their Naverlab-partners can create, and an analysis-tool that Sara created.
Where both the P2PaLA-tool and Naverlab-training require the involvement of external people, who do their utmost to create fantastic tools – it is a factor of dependency. Though in the future these tools will be incorporated. Naverlab’s training showed an initial 85% accuracy, which is really awesome if one could expand that over a whole corpus of 108 books. The P2PaLA tool was far less accurate and required over 200 pages of training per type of print. Thus, if a series looked alike, one model would do – otherwise multiple models were required.
Sara used the data that ABBYY FineReader adds to a document. Within Transkribus, there is a built-in option to use ABBYY as an OCR-engine. When you do, ABBYY adds information about the size of fonts and whether something is bold or in italics. This is not flawless, but as I had a list of titles of norms available for a few books she wrote a script that was to match keywords of the titles to where the ABBYY indicated that a different font had been used. This script performed really well, with an accuracy of at least 95%. In fact, it performed so well, it found three texts that I had initially overlooked. It did mean that all books needed to be checked whether the ABBYY information had been added to the underlying data – and in many cases the HTR-models had to be rerun as well. With Sara’s tool we were able to segment the texts of one book that I had already made a list of including all the titles in order to move towards a proof of concept.
Moving to a proof of concept
Annif is a tool created by the Library of Finland. It is basically a way of doing ‘reversed topic-modelling’. If you already have labels assigned to a text - which I did for a couple of books - you can have the computer learns from that data. It has to read through the text and discover why certain labels were applied to the text. It will then be able to apply this to new texts it is confronted with. This is just one of the methods that can be used within Annif, another possibility is to apply a ‘SKOS’ which stands for Simple Knowledge Organisation System. In a SKOS one can describe all sorts of relations (hierarchies) and include URIs (Uniform Resource Identifiers) – which can be useful when you want to add to the semantic web/ Linked(Open)Data. The provisional SKOS that we created within this project is available upon request - it is archived at Zenodo 10.5281/zenodo.3564586.
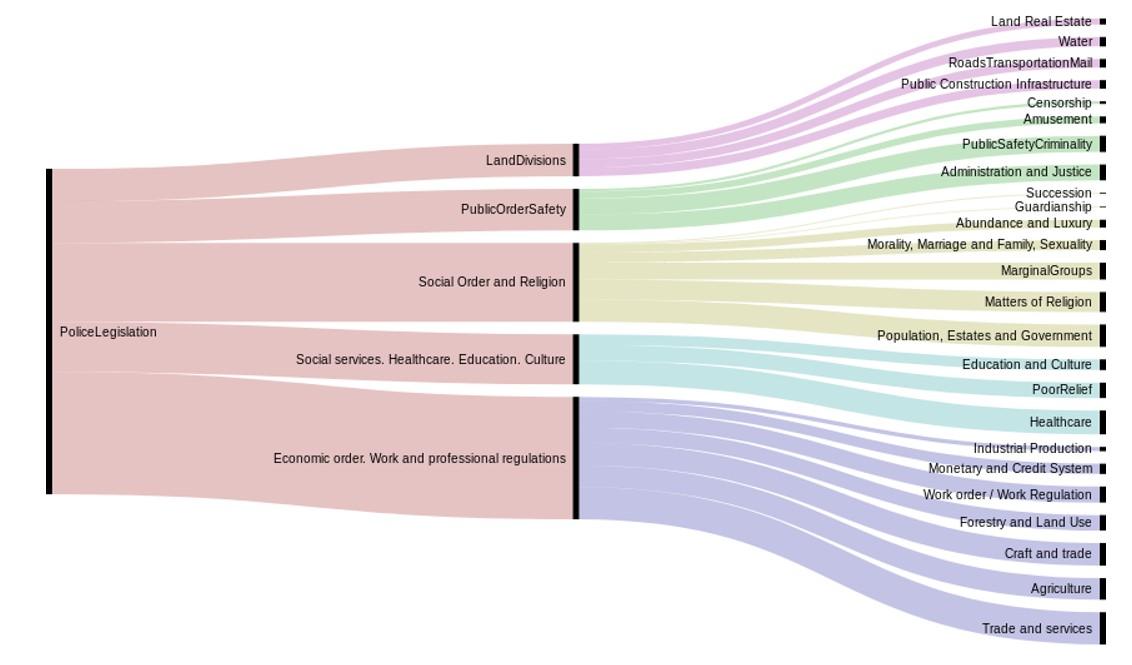
Figure 1. The first levels for the top category 'Police legislation'. Bar width indicates the number of texts in this category. Through: Alluvial Diagram - https://app.rawgraphs.io/
Can we now say that legislation was copied?
As we could only work on a fairly limited set of sources, this question is still rather difficult to answer. However, there are a few leads here. First we need to acknowledge that the transferability of a rule depends on its contents. Secondly, the socio-political but certainly also the ecological environment are a factor in understanding the potential contents of the rules. Thus, a rule on dykes (infrastructural), cannot be implemented into an area without such a geographical environment. Similarly, economic issues and issues dealing with security (public or societal) are more prone to being copied.
Hence, one of the exemplary topics that can be found is a rule (issued in - among others - Groningen and Gelderland) on the acceptance of the standardisation of the wagon axle-width in accordance with the Holland-standard. This is quite obviously meant to ease trade and meant to give merchant a better chance of trading.
Another topic, that of beggars and vagrants, proves to be present in each and every area of the Low Countries. Though the type of marginal groups may depend on whether it was a rural or urban area; the way they claimed to deal with them was to have them leave the area or turn themselves in. Other inhabitants are kept from helping the vagrants, and could be heavily fined if went against this. There is - at this moment - no way of telling in what direction (potential) influence went; but surely the type of rules were the same.
With 1800 categories, it is impossible to check for them all in this phase of research. However, it does show that it is an interesting route to pursue.
Future-steps – recommendations
This project has come to an end, but it is not the end. I will continue to pursue this study through various angles and I have gained many insights from working with the KB. It has been an adventurous journey that taught me much about Digital Humanities/History and the world behind lending books/ or looking them up online. There is much more that can be done with this source-material, things we did not have time to do (they could be assignments for students, and probably even thesis-projects).
- One first, general remark, early modern source material is very rich; it may have challenges such as readability, but newly developed tools should certainly be tested on these sources! They will form a brilliant test-case for (scientific) programmers, especially through their challenges. So please, do not neglect early modern sources for they too tell an important (hi)story!
- We did not work on the morphology and spelling variety of words within the text, hence, Annif may have had a tricky time figuring out which word was similar to another word in another text. Had we set the step of checking out morphological similarities this might have helped with the results).
- At this moment, advanced lay-out analysis (thus the recognition of pages and their elements) is something that needs to be done as one of the earliest phases of working with sources. However, the understanding of a LA grows the more one works with a document; hence it would be great if this advanced LA would be ‘enrichment’ rather than the first step on needs to take.
- The texts could have been tagged with Named Entity Recognition (NERs) for e.g. places, names, dates throughout the whole set.
- Visualisations: having the NERs (previous step) it would become possible to plot them on a map. If you have them for multiple provinces, it becomes possible to create a timeline – enabling one to really see if topics moved (or actually, if the norms followed the problems that they addressed).
- It would be great, if it would become possible to have transcripts and original Google Books-scans to be jointly presented in a screen through an IIIF-viewer. With the option to search for specific words.

Previous blog:
- https://www.kb.nl/blogs/digitale-geesteswetenschappen/plakkaten-classif… (NL)
- https://lab.kb.nl/about-us/blog/digital-humanities-and-legal-history-can-computer-read-and-classify-ordinances (Eng)
Dutch spoken webinar (basic):
- 10.5281/zenodo.3555092
- https://www.youtube.com/watch?v=o6BRXq1S-b8
Powerpoint Dutch webinar (basic):
- 10.5281/zenodo.3558860
Dutch spoken webinar (advanced):
- 10.5281/zenodo.3555097
- https://www.youtube.com/watch?v=I_KUIrwphJw
Powerpoint Dutch webinar (advanced):
- 10.5281/zenodo.3558864
Dataset #EntangledHistories: