Segmentation
Where the creation of HTR-models can be regarded as an overall success story, attempts to segment the texts turned out to be a real quest. Naive as I was when I entered the field of Digital Humanities, I had assumed that if a human can easily spot a big white space and then a much larger font often bold and in italics a computer could immediately recognise this as a title.
This. Is. Not. The. Case. It is just not that simple. The computer is very stupid in this respect.
So how can you have the computer segment a text? If you can crack that question and create a solid technique in the next few months, you are likely to land yourself a job within a company of choice. For now, it is a case of trial and error and certainly not fail proof.
We have tested several potential techniques, and I would like to explain – and show – the results of that. Mind you, this is the as-is situation of October 2019 so we may expect lots to happen in the next months and years.
1. Page to Page Lay-out Analysis (very early test phase)
Transkribus is currently developing a tool in cooperation with the Universitat Politècnica de València (UPV) (department: Pattern Recognition and Human Language Technology (PRHLT)) called Page to Page Lay-out Analysis or P2PaLA in short. The idea(l) is to train several pages by labelling them and telling the computer what is so special about the fields.
So, initially I tagged about around 40 pages in total, from various books. It quickly turned out that the lay-out model would need to be created per type of book (some publishers printed several books, so they look really alike). For example, if the lay-out looks similar (size, font, sheet mirror) a model would function on a book that looks alike; however, when a book is not printed in columns but the text is full page, this requires a different model. When the first model returned, I was quite disappointed for it looked all but right. It even did not return the correct information on a page that I had fully trained.
I was advised to contact the people in Valencia to at least get some more information and I talked to the Dutch National Archive where they were working with the tool as well. It soon turned out that the tool could work reasonably well, if – at this point in time – there were not too many element types tagged (max. 5) and about 200 pages per book(-type) were trained.
I did give it a shot with two books - which could be applied to several others. The returned results were rather mixed. On one of the books it worked rather well – this was a book that had lines covering the entire page; the other book, with columns did a much poorer job. For even though I drew squares and boxes, the results that returned with the model were hardly ever squares, but most of the time free shapes. This may well work with handwriting, I am fully aware of that, but it’s quite difficult with print.
*P2PaLA is be integrated and tested late 2019 (alpha-users); to be expanded to other users later on in 2020.
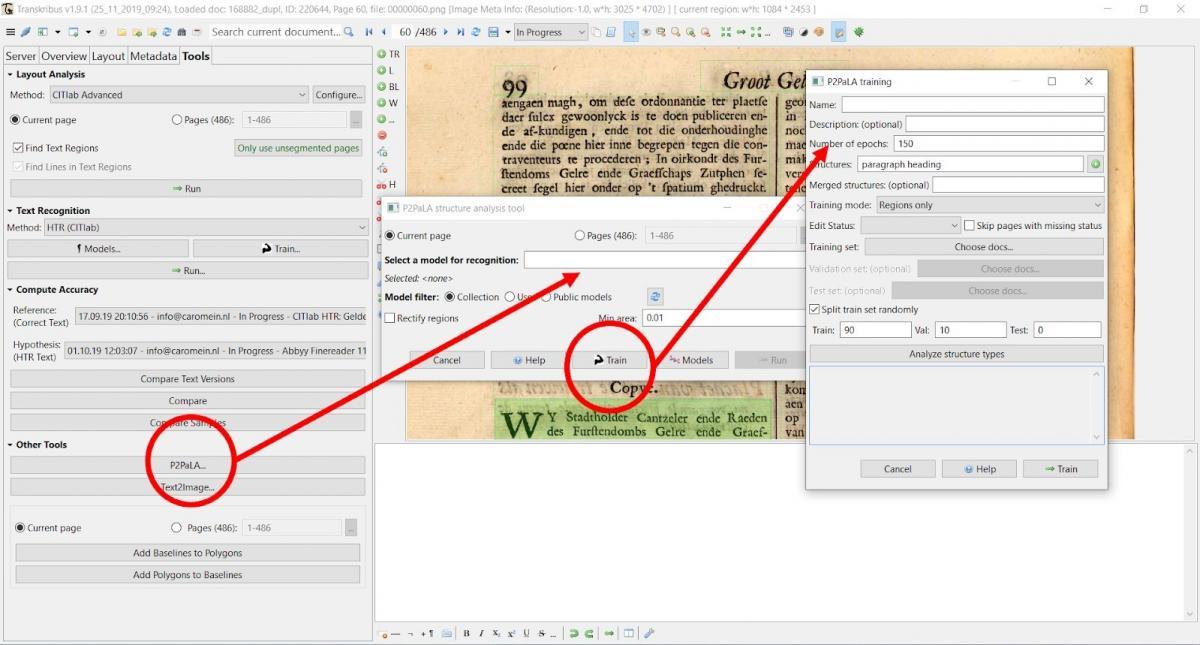
Screenshot of Transkribus (v. 1.9.1) - showing the trainings-screen for P2PaLA. In the right pop-up screen, several ‘structures’ (fourth field) can be selected to train a LA-model.
2. NLE Document Understanding (Naverlab Europe)
Having seen a snapshot of our material, Transkribus’ suggested that we talk to their Naverlab partners who could offer solutions. And indeed they can train a model that is trained based upon the Lay-out analysis and its tags. It makes use of the HTR-transcribed text as well.
This tool is fully under development and so far their recognition of individual parts is at approx. 85% accuracy. Another part of this tool is aimed at working with tables!
What I found very useful, is that since I trained squared-boxes around the text (because it is print) NLE Document Understanding returns boxes and squares - which works well with me as it gives me a bit of an overview that matches my expectations (due to the type of document). We will soon hear a lot more about this tool - as it is supposed to be integrated into Transkribus sometime soon.
*NLE Document Understanding is expected to be integrated into Transkribus somewhere in 2020.
3. ABBYY and Sara
In the meanwhile, Sara has been looking at the ABBYY FineReader results that had been part of our output in Transkribus. ABBYY recognises columns much better than Transkribus LA can, at the moment. ABBYYdoes recognise large fonts and special prints (bold, italics) so she created a script that focussed solely on these properties to trace these throughout one of the files we are now using as our Proof of Concept-book (which is only one out of the set). It is much easier to make a tailored, rule-based approach for a specific book than to create a tool that can handle various use-cases.
Sara could cross-reference these with a list I created on that very same book, so she knows whether the computer is correct. This script performed really well, with an accuracy of at least 95% - in fact, it performed so well, it found three texts that I had initially overlooked. It did mean that all books needed to be checked whether the ABBYY information had been added to the underlying data – and in many cases the HTR-models had to be rerun as well. Hence, through Sara’s tool it was possible to segment the text of a book from the province of Gelderland to see if we could move towards a Proof of Concept.
Sara’s tool can be found in the GitHub-Repository:

Previous blog:
- https://www.kb.nl/blogs/digitale-geesteswetenschappen/plakkaten-classif… (NL)
- https://lab.kb.nl/about-us/blog/digital-humanities-and-legal-history-can-computer-read-and-classify-ordinances (Eng)
Dutch spoken webinar (basic):
- 10.5281/zenodo.3555092
- https://www.youtube.com/watch?v=o6BRXq1S-b8
Powerpoint Dutch webinar (basic):
- 10.5281/zenodo.3558860
Dutch spoken webinar (advanced):
- 10.5281/zenodo.3555097
- https://www.youtube.com/watch?v=I_KUIrwphJw
Powerpoint Dutch webinar (advanced):
- 10.5281/zenodo.3558864
Dataset #EntangledHistories: