The more modern books get, the easier Optical Character Recognition (OCR) can be applied. This has much to do with the resemblance with a standard font, finite number of characters, less noise on pages. However, the older the books are the more problematic OCR gets – especially when printed in gothic script. Even the Roman font is a challenge with the long s (ſ) where the s resembled the f to a great extent. Searching a text, when the characters are not properly recognised is a challenge, often leading researchers to return to the originals as the computer did a poor job. I do not want to claim that the texts that have been transcribed within Entangled Histories are flawless, for we did encounter several challenges (that I will discuss here and in other blogs). However, we believe that the corpus improved tremendously and can be used to search the texts in a more advanced way.
Having organised a couple of workshops on Transkribus, I learned that this Handwriting Text Recognition (HTR) could as easily be applied to printed texts because we can consider them to be very regular handwriting. Keeping that in mind, we chose to test Transkribus within this project to see if it could indeed reach a quality that has a Character Error Rate (CER) of less than 5%. Transkribus does require training – first a computer can only see pixels and would not know where to find text (for now) unless a human points it out. Thus, after having all the books of ordinances (108) uploaded into Transkribus we could start (1) the automatic lay-out analysis and then (2) start transcribing them – partially - in order to have enough GroundTruth to create models which would automatically transcribe the rest of the texts.
Using ABBYY or Transkribus, or both?
Transkribus has a built in OCR-engine, called ABBYY FineReader (v.11). With printed texts, one can first run these through ABBYY to have them recognised as much as possible. As said, this has some disadvantages:
- ABBYY is aimed at modern texts (finite amount of characters, not too much noise on the page) which is not really the case for early modern texts.
- You can select ‘Gothic’ or ‘mixed’ (being Roman and Gothic) – but it does not really work well for older texts. Even if you apply the Gothic, it assumes one deals with German Gothic (Fraktur) which is different from the Dutch Gothic print.
It also has several advantages:
- It embeds information on the size of the fonts, italics and bold (not flawless).
- It recognises quite a bit of text (not flawless).
But, at least part of the text has already been recognised and that means that it becomes easier to transcribe other parts (correcting takes less of an effort than transcribing from scratch). Furthermore, when you have transcribed several pages (at least 10 to 15) it becomes interesting to create a model for the pages that you already transcribed. Creating ground truth becomes an iterative process where the automatic transcriptions get increasingly better - thus requiring less corrections. Transkribus has the option of checking whether all characters have already been included in your set. If, let’s say the numbers are not yet complete, you at least know this when you run the model over the next couple of pages. You will already know where the shortcomings of the model are and what needs to be improved. Other characters, which you already included into the earlier pages are likely to be correct now, so the correcting takes even less of an effort than before.
Why I would opt for HTR instead of OCR?
That is indeed a fair question that has crossed my mind many times. So here is a little table of information:
|
OCR (ABBYY/ TESSERACT/ KRAKEN) |
HTR (Transkribus) |
| Focus on single characters, so no context is used | Focus on both single characters ánd context (sentence-based with an n-gram) |
| Preferably clear background | Preferably clear background, but focus on the text-regions (difficulties on blank pages) |
| Sudden language/ character changes can cause trouble | Sudden language/ character changes can cause trouble |
| Trained – fixed – tool | You create a ground truth and can create a model fitting for your text |
As you are responsible for creating ground truth for Transkribus, or you apply a model that (nearly) fits your needs; you are more certain about the output quality.
Training models, HTR vs HTR+
To be able to train models, is a feature one needs to request the Transkribus team in Innsbruck directly. It is a matter of days before – all of a sudden – a button in your screen appears that allows you to train models. If you want, you can immediately request the feature HTR+. What’s that? When you want to train models, you get access to HTR, which allows you to train a model with the help of 40 epochs. If you request the option of training in HTR+, the number of epochs rises to a 200 epochs - in the equal amount of time; and one can even opt for manually changing the number of epochs to over 1000. Epochs are the times that the High Performance Computer (HPC) in Innsbruck is taking a look at your texts before it determines the end-result of the model.
Remember that you need to train several pages before the computer supposedly recognise a hand or a font? The baselines - lines drawn under the characters in your text - in your images guide the computer to where it has to look; then your transcripts ‘show’ what the computer is supposed to understand from the blobs on the page. As you assign training pages and test pages while you have the computer work on a model, the computer is going over all of these pages. For both training- and test-pages, you have transcriptions in the transcription field.
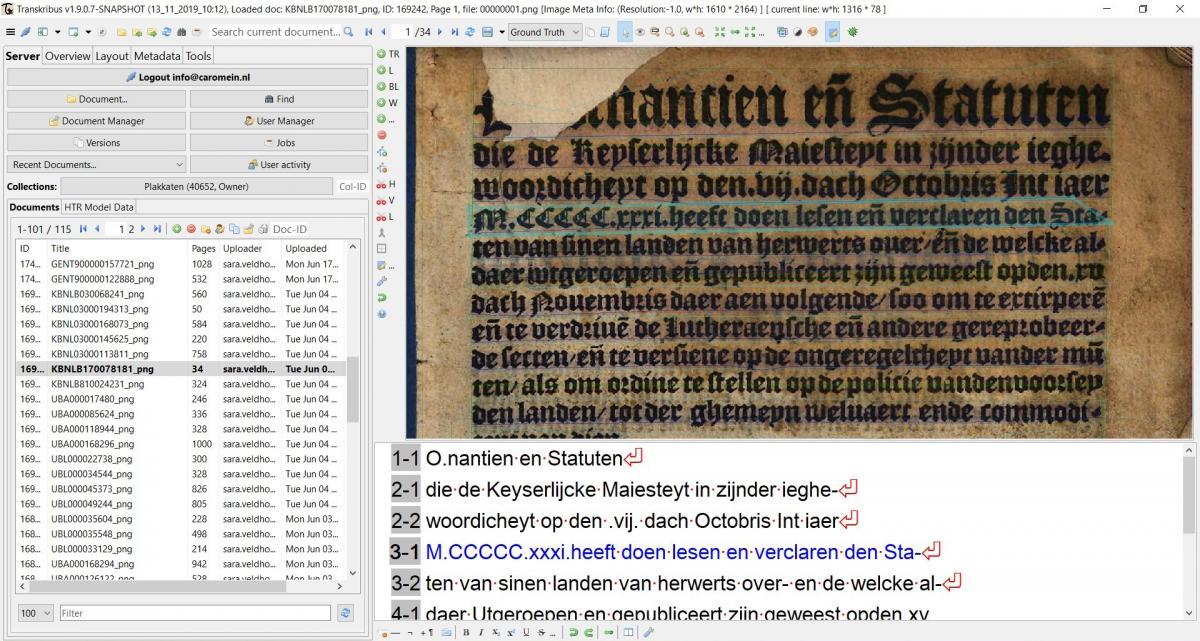
Source: Screenshot of Transkribus (v. 1.9.0.7) - showing a 16th century Gothic ordinance and the transcription.
So, the computer is first looking at the training pages learning what blobs look like and what you – as a trainer – want it to see in words. It will then look at the test-pages and sees whether it can transcribe it on its own account, with the verification of the transcripts that were provided. It keeps going back and forth, becoming smarter in the process. That’s why the graph shows quite problematic results at the beginning, improving towards the end because it has seen the text, learned from miniscule elements in the ‘blobs’ and learns whether something is e.g. an ‘l’ or a ‘1’. The more it gets trained – i.e. the more training material there is – the better it will perform. Keep in mind that you will need about 10% of your transcriptions to be placed in the test-group.
Overfitting and ideal size of the corpus
Recently, Gundram Leifert (University of Rostock) answered this frequently asked question upon the facebook forum “Transkribus Users”: how many training samples do I need to train good data? Gundram is one of the developers of the HTR-component of Transkribus. His reply to this question was that one needs: ‘[...] at least 1000 lines of text - but the more, the better.’ (10-Sept-2019).
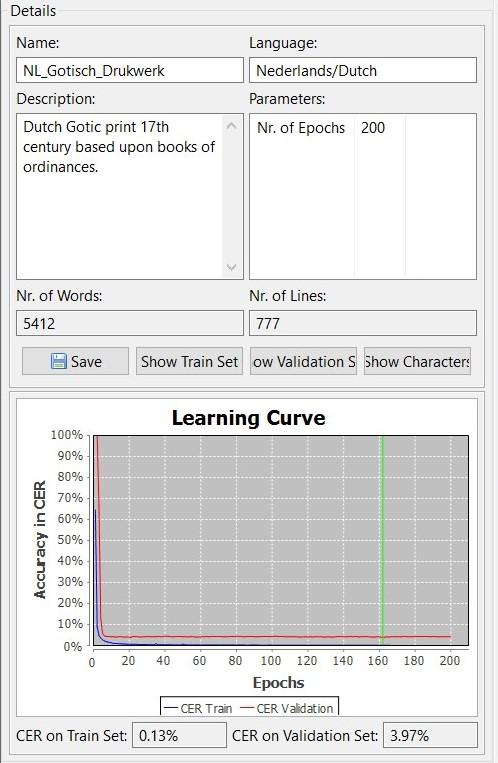
Source: graph trained on (only!) 777 lines, 5415 words. It shows overfitting as the train set is very low, but the validation set is not coming close.
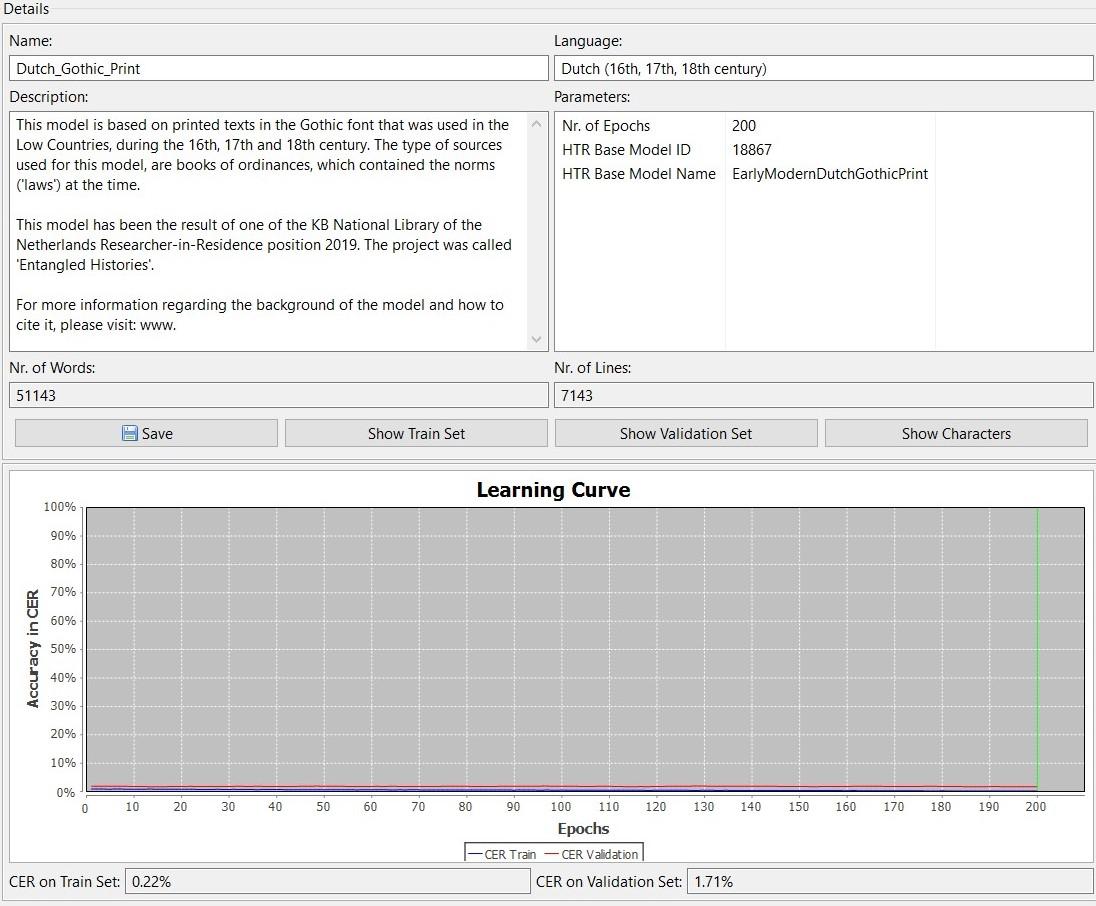
Source: graph trained on nearly 7142 lines, 51143words.
Why is this important? If Transkribus has seen too few training samples, the HTR has only learned from working with the Ground Truth (GT) that has been presented and will perform less on unseen material. This is called ‘overfitting’. The HTR has to learn the general rules of the text and characters. How do you know whether there is a case of ‘overfitting’? Transkribus produces graphs that go alongside models. It is always important to have a look at these, as they provide you general information on the data that was used to create a model and on how well it performs. If the training error continues to diminish, while the test error remains constant there is a case of overfitting and one should add additional training material. In other words, the HTR has not yet learned the general rules to transcribe the text and needs additional training material. If, however, the curves of both the training and test remain at the same distance from each other for a very long time, but showing that it does learn, one should add additional epochs for training the model.
Training a corpus that cannot - or can hardly - be read through OCR, with the aid of HTR(+) is very helpful as the automatic recognition of the text is manually trained first on several pages the results are much better than we had expected at first.

Previous blog:
- https://www.kb.nl/blogs/digitale-geesteswetenschappen/plakkaten-classif… (NL)
- https://lab.kb.nl/about-us/blog/digital-humanities-and-legal-history-can-computer-read-and-classify-ordinances (Eng)
Dutch spoken webinar (basic):
- 10.5281/zenodo.3555092
- https://www.youtube.com/watch?v=o6BRXq1S-b8
Powerpoint Dutch webinar (basic):
- 10.5281/zenodo.3558860
Dutch spoken webinar (advanced):
- 10.5281/zenodo.3555097
- https://www.youtube.com/watch?v=I_KUIrwphJw
Powerpoint Dutch webinar (advanced):
- 10.5281/zenodo.3558864
Dataset #EntangledHistories:
More information:
- Günter Mühlberger et al., ‘Transforming Scholarship in the Archives through Handwritten Text Recognition’, Journal of Documentation 75, no. 5 (2019): 954–76. https://www.emerald.com/insight/content/doi/10.1108/JD-07-2018-0114/ful…;