Can we train a computer to annotate early modern legislation with uniform search terms (topics)?
This was one of the questions that historian Annemieke Romein tried to answer during her 6-month Researcher-in-residence project in our lab. I am Sara Veldhoen and I was involved in the project as research software engineer. At the KB, we had recently been experimenting with automated subject indexing, as reported in a whitepaper by Kleppe et al. The explorations mainly concerned Annif, a tool developed at the Finnish National Library by Suominen. We were very curious to see how this same tool would behave in such a different context: with short, early-modern legislative texts and a much more structured (hierarchical) subject vocabulary. In this blog, I reflect on our findings.
Annif
Annif is a toolkit for automated subject indexing (find a tutorial here). From existing metadata with subject headings from a controlled vocabulary, it can learn how to assign those headings to new, unseen data. The tool comes with a variety of backends, ranging from lexical methods such as TF-IDF and Maui, to vector-space models such as fasttext. It also offers ensemble learning, allowing you to combine the strengths of trained models from different set-ups.
Data
The research considered books of ordinances (in Dutch: ‘plakkaatboeken’), published in the Low Countries between 1531 and 1789. Since modern OCR-software cannot deal with early-modern printed material, we used Transkribus, a tool that was originally designed for handwritten text recognition (HTR), to make transcriptions.
For the next phase of the research, we focused on one of these books to provide a proof of concept: Groot Gelders placaet-boeck, Volume 2. The transcripted text from this book was segmented into separate laws with a rule-based approach, the code of which can be found on Github. It used information on font size from ABBYY whenever available, together with keywords matching to common title words reaching over 95% accuracy for the segmentation.
Annemieke had manually created annotations for this book, indicating the appropriate topic(s) for the 470 individual laws, from a controlled subject vocabulary that I describe in the next section.
Processing these historical data comes with a few challenges:
- The transcription process is not flawless. Contrary to digital-born texts, character errors exist that stem from the digitisation. These may prevent unification of equivalent words, even after morphological processing such as stemming or lemmatisation. And character errors may also negatively impact the performance of morphological tools.
- Even if the transcripts are (nearly) perfect, early modern texts tend to contain a lot of spelling variation and dialects, as there was no ‘standard spelling’ in place.
- One other challenge with this particular dataset is the fact that other languages occur besides Dutch, such as French, German and Latin.
Note that we did not address these issues at this stage, nor did we apply a dedicated stemming algorithm for early modern Dutch.
Subject Vocabulary
The laws were labeled with subjects from a categorisation created by the German Max-Planck-Institute for European Legal History (MPIeR). The same categories have been applied internationally, in over 15 early modern European states. It is a four level deep hierarchical categorisation considering police legislation, with the five top categories ranging from Social Order and Religion, to Public Safety and Justice, Schooling, Economic Affairs and Infrastructure. The topics are quite distinguishable until at least level three. International laws were tagged with a separate topic outside of police legislation.
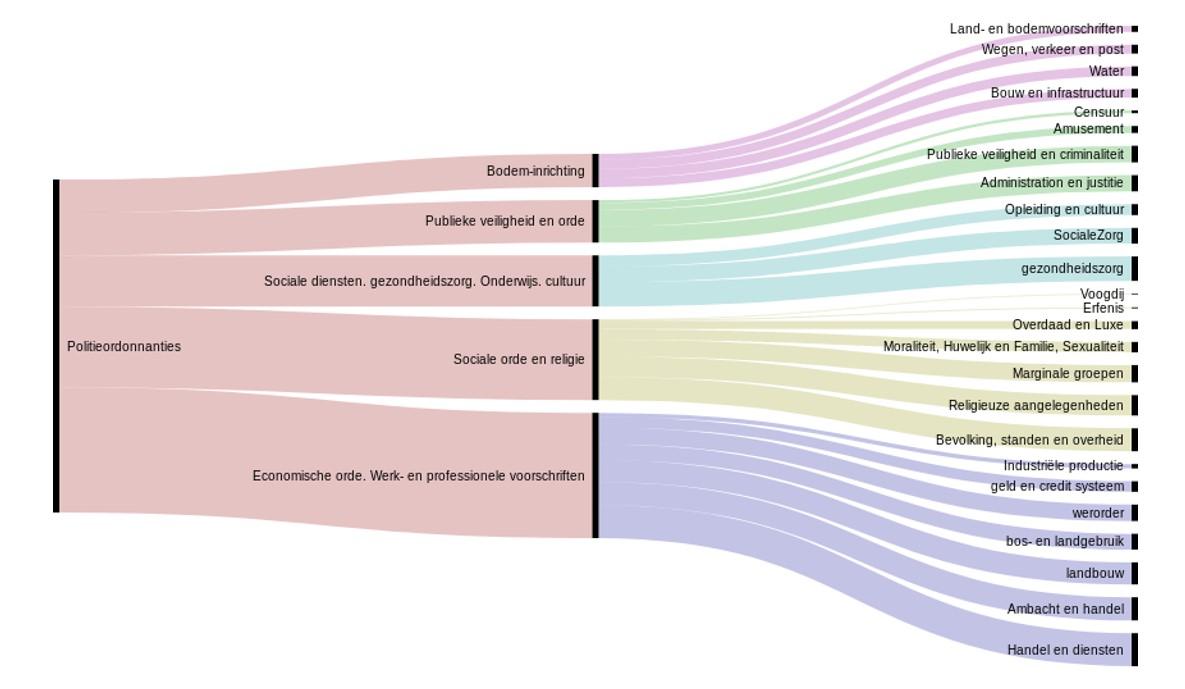
Figure 1: The first levels for the top category 'Police legislation' (in Dutch). Bar width indicates the number of texts in this category.
Since it is legislation we are dealing with, the texts are rather unambiguous. Still, a single text can concern several (up to 10) topics at once. On average, 3.3 topics have been assigned to each law.
The hierarchical nature of the categories might be informative for the automatic categorisation. However, most back-ends in Annif are currently unaware of hierarchy in the subject vocabulary, except for the Maui Server backend. To this end, we transformed the vocabulary into a skos (simple knowledge organisation system) format. The provisional skos file will be published on Zenodo shortly (DOI: 10.5281/zenodo.3564586).
Set-up and Results
We were particularly interested in the performance of subject indexing at different levels (depths) of the subject vocabulary. Therefore, we created five versions of the dataset: one for each level, where the document would link to the ancestor(s) of its assigned topic(s). In the subsequent analysis, level 1 indicates the distinction between international law vs. police legislation (i.e. public law), and the subsequent levels in the hierarchy of the MPIeR categories. For each level, we determined the majority baseline, as indicated in Figure 2.
Because of the limited amount of data, only 470 laws, we ran all the experiments using a 10-fold cross-validation with a 90/10 train/test split. Due to time constraints, the only back-end we have been able to experiment with so far was TF-IDF. We determined the optimal results on all levels were obtained with a limit of 4 terms to be predicted using a threshold of 0.4.
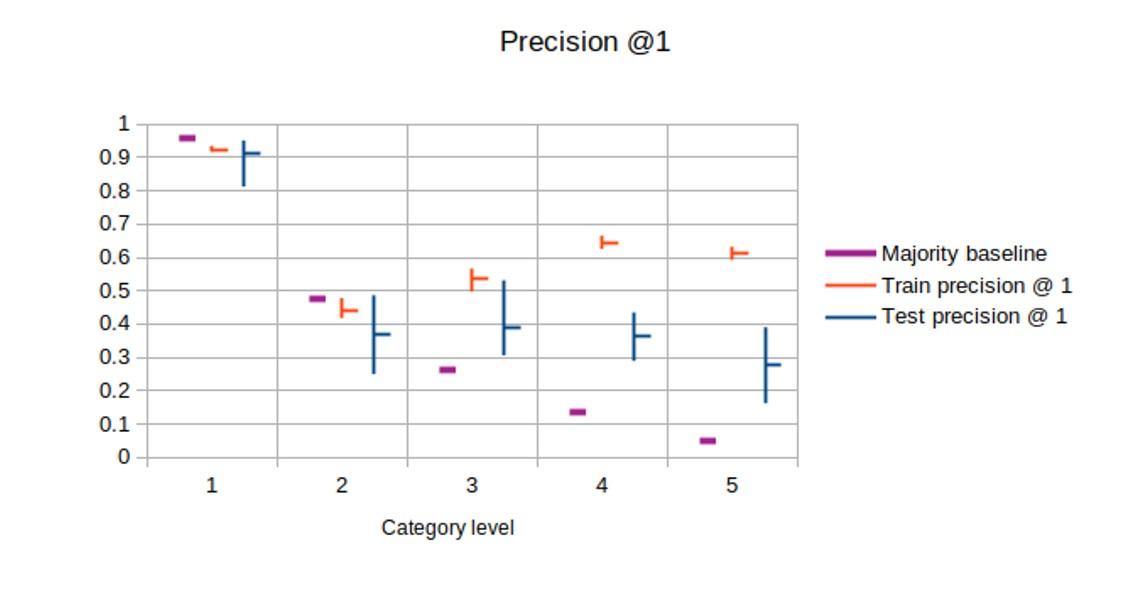
Figure 2: The horizontal axis indicates the hierarchical level of the subject indexing. The figure indicates majority baselines (purple), and precision@1 on the train (red) and test (blue) set. The horizontal bar indicates the average over 10 folds of the data, the vertical bar indicates spread.
In Figure 2, we present precision@1 to compare the performance to the majority baseline. The test precision shows a lot of variance, which can be explained to the limited amount of data (10% of 470 documents) the scores were based upon. Train precision is typically higher than test precision, which indicates a lack of generalisation due to the limited amount of data. For levels 1 and 2, the majority baseline was not reached by the model, perhaps because the data is not very balanced: there are hardly any examples to get informed about non-dominant categories. In the higher levels (deeper in the hierarchy), the distribution over topics is more even and the model is more successful at predicting relevant topics.
More indicative of the actual performance of the model are recall and precision measured over all suggestions. Precision indicates whether the terms suggested by the model are correct according to the manual annotation. Recall measures to what extent manually assigned terms are also suggested by the model.
What counts as good performance depends also on the application. If you would use the assigned terms in an information retrieval set-up, high recall means that few relevant documents will be missed, whereas high precision will prevent irrelevant documents from showing up.
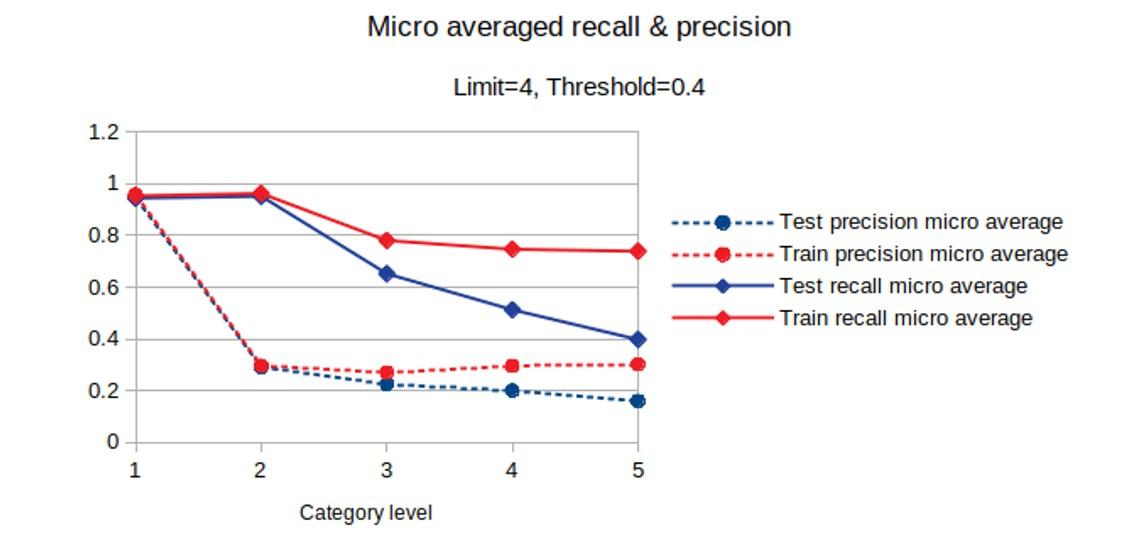
Figure 3: The horizontal axis indicates the hierarchical level of the subject indexing. The figure indicates average precision (dotted) and recall (solid) for the train (red) and test (blue) set.
Recall and precision are visualized in Figure 3. We present micro-averaged metrics, because those are more robust against imbalanced data. The model is already able to suggest 40% of the relevant detailed terms (level 5) on the test set, which is quite impressive for this task with such a limited amount of data. Again, we see that performance on the train set exceeds that on the test set. This indicates that adding more training data will probably boost performance. Moreover, addressing the issues that come with early-modern material mentioned earlier, would arguably help as well.
Discussion
Through a proof-of-concept, we have shown that using Annif would be a promising approach to improve the searchability of this collection through automatic categorisation. It requires further work to extend the dataset (mostly segmentation). Moreover, it would be helpful to apply or develop tools that can deal with spelling variation and early modern morphology. For lexical backends such as Maui Server, adding alternative labels with historical synonyms to the vocabulary may help too.
At the same time, this dataset could serve as a case in the development of Annif towards awareness of vocabulary structure. Once the entire dataset has been labeled properly, together with the SKOS version of the hierarchical vocabulary it could serve as training data to experiment with different approaches to structure awareness.
