Skip to main content
Layer 1
Logo KB Lab
Hoofdnavigatie
Datasets
Tools
Tutorials
News and events
Blogs
About us
Affiliated researchers
Team
Contact
Secondary menu
NL
Open Menu
zoeken
Dataset
Accessible e-books and audiobooks
We asked specialists to convert several public domain publications into accessible versions.
Ot & Sien dataset
Data for the development of the automatic visual object recognition tools in children’s books.
Web collection NL-blogosfeer
Metadata-datasets and collection description regarding the NL-blogosfeer: collection of Dutch weblogs.
Historical newspapers OCR ground-truth
A dataset consisting of 2000 pages historical newspaper groundtruth, OCR and images.
Entangled Histories: Ordinances of the Low Countries
This special collection is made up of 108 books of ordinances published in the Early Modern Era.
DBNL OCR Data set
This data set consists of 220 texts digitised by the DBNL in TEI and txt (OCR).
Web Collection Chinese Netherlands
This web collection contains archived websites from the Chinese community in the Netherlands.
Web collection internet archaeology Euronet-Internet (1994-2017)
This web collection is made up of archived websites hosted by internet provider Euronet.
CHRONIC
The CHRONIC dataset consists of metadata for 313K classified newspaper images using computer vision.
SIAMESET
The SIAMESET dataset consists of images and metadata of advertisements from two Dutch newspapers.
Newspaper ngram collection
This dataset contains yearly counts for word ngrams from the KB newspaper collection.
KBK-1M
The KBK-1M Dataset is a collection of 1,603,396 images and accompanying captions from 1922 – 1994
Europeana Newspapers NER
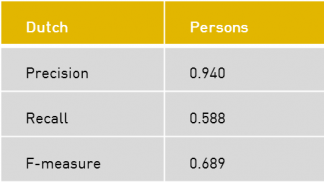
Data set for evaluation and training of NER software in Dutch, French, Austrian and German.
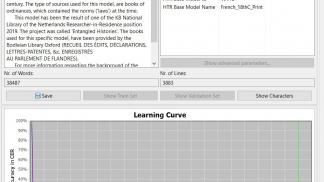
Ground-truth IMPACT project
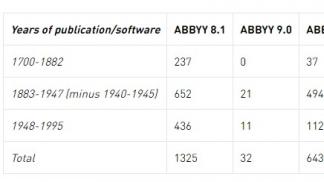
Collection of 99,95% correct OCR of books, newspapers, parliamentary papers and radio bulletins.
Example set
This collection consists of a small selection of our digitised publications from the years 1870-1871.