Introduction
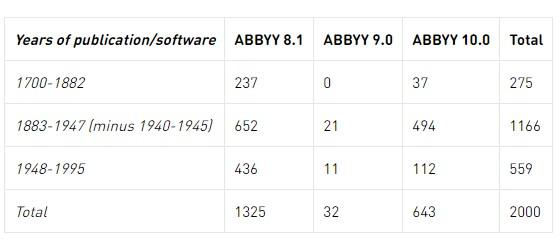
For a research project about the OCR of our historical newspapers, we produced 2000 pages of ground-truth. This dataset is available for research purposes and structured as follows;
| Years of publication/software | ABBYY 8.1 | ABBYY 9.0 | ABBYY 10.0 | Total |
| 1700-1882 | 237 | 0 | 37 | 275 |
| 1883-1947 (minus 1940-1945) | 652 | 21 | 494 | 1166 |
| 1948-1995 | 436 | 11 | 112 | 559 |
| Total | 1325 | 32 | 643 | 2000 |
Selection and correction
For each category a randomised selection was made using newspaper issue identifiers, after which either the first or the second page of the issue was selected for the dataset. The pages were manually corrected to either 99,95% correct characters (digitised from paper) or 99,5% correct characters (digitised from microfilm). After each batch delivery a random paragraph of each page was checked by the KB.
All pages were sent to a service provider and were rekeyed using the software package Aletheia, developed by the PRImA Research Lab during the IMPACT project. The instructions they received were the following:
- The text should be 99,95% correct, leaving the segmentation in the pages as they are.
- Change ligatures to separate characters: æ à ae - ij à ij, etc.
- Change fractures to separate characters: ¼ à 1/4, etc.
- Type what you see including capitals and printing mistakes if there are any.
- Any layout information, such as bullet points or indentations, or style, such as bold or italics, can be ignored.
- Leave the long s (ʃ) and guilder (ƒ) as a special character.
- Only type logos and other textual lines in more visual parts of the newspapers such as advertisements if they are clearly legible.
- Initials are part of the first line.
- Ignore spaces in words that are there for layout reasons.
- Normalise special characters to ASCII (except long s and guilder).
Data
This set consists of;
- 2000 Images in JP2 format
- 2000 Original OCR files in ALTO format
- 2000 Manually corrected OCR ground-truth files in ALTO format
For more information, please see the available metadata file:
- DocumentHistorical_newspaper_OCR_groundtruth.xlsx (100.64 KB)
When using this data set we ask you to cite it as follows;
Wilms, L., Nijssen, R., Koster, T. (2020), Historical newspaper OCR ground-truth data set. KB Lab: The Hague.
Access
To obtain this dataset, please send an email with your request to [email protected], including the following information:
- Your name
- Affiliation/institution
- Why you would like access to the dataset
- How long you would like access
A representative of the KB will contact you and can provide access to the dataset for scientific or scholarly purposes after a contract has been signed. Please note this process can take a couple of working days before access can formally be granted.