In a past blog we wrote about research on the quality of the OCR of our digitised newspapers. Since then we’ve developed 2000 pages of ground-truth (GT) and have used those to examine if and how we can improve the recognised text of one of our biggest digital collections. This post describes the development of the GT and the research we have done to better understand the OCR quality of our digitised newspapers.
Development of GT
Once we established that we could in fact use the access images for our research (instead of the hard to access master images) we selected 2000 pages from the collection. These 2000 pages only represent a mere 0,17% of our entire historical newspaper collection (at the time), but budget restraints meant this was what we could produce. We subdivided the to be selected files into the following categories:
| Years of publication/software | ABBYY 8.1 | ABBYY 9.0 | ABBYY 10.0 | Total |
| 1700-1882 | 237 | 0 | 37 | 275 |
| 1883-1947 (minus 1940-1945) | 652 | 21 | 494 | 1166 |
| 1948-1995 | 436 | 11 | 112 | 559 |
| Total | 1325 | 32 | 643 | 2000 |
A random selection of digitisation identifiers was made for each of the categories after which alternatingly the first or second page of that issue was selected. Given that we were looking for pages with as much text as possible we opted for the first two pages of each issue where we would mostly see text and could hopefully avoid full pages of advertisements. Due to the varying typefaces and print quality during the Second World War we chose to exclude those years from the selection, as it is not representative for the whole collection.
Instructions
All pages were sent to a service provider and were rekeyed using the software package Aletheia, developed by the PRImA Research Lab during the IMPACT project. The instructions they received were the following:
- The text should be 99,95% correct, leaving the segmentation in the pages as they are.
- Change ligatures to separate characters: æ à ae - ij à ij, etc.
- Change fractures to separate characters: ¼ à 1/4, etc.
- Type what you see including capitals and printing mistakes if there are any.
- Any layout information, such as bullet points or indentations, or style, such as bold or italics, can be ignored.
- Leave the long s (ʃ) and guilder (ƒ) as a special character.
- Only type logos and other textual lines in more visual parts of the newspapers such as advertisements if they are clearly legible.
- Initials are part of the first line.
- Ignore spaces in words that are there for layout reasons.
- Normalise special characters to ASCII (except long s and guilder).
For each batch a random paragraph was manually checked for each image and the batch was then either approved (with a 99,95% accuracy) or returned to the service provider for further correction.
As is often the case in the development of GT, it took some weeks for the process to run smoothly. As we didn’t want to touch the segmentation of the articles the people rekeying had to work from existing OCR and we quickly found that the scans that were made from microfilms were of such a bad quality that it was very difficult to reach the 99,95% accuracy. The decision was made to extract those images and process them separately with a lower accuracy of 99,5%. In the end we spent an extra 4 months on the development of the GT than originally planned.
Post-correction with machine learning: Ochre
We worked together with research software engineer dr. Janneke van der Zwaan who developed a machine learning application that can correct existing OCR. Due to the delays in the GT production Janneke had less time than we originally planned and could therefore only use a portion of the files to train her engine. We chose to select the 1325 pages digitised with ABBYY 8 as we expected the best results in post-correction there. Out of these, 80% was used for training, 10% for validation and 10% for evaluation. A more elaborate description of the application, its development process and the results, please see this more elaborate post about Ochre by Janneke.
The application is available on Github: https://github.com/KBNLresearch/ochre.
Re-OCRing with ABBYY 11
All pages were re-OCRed using ABBYY11, the latest version of the software we have been using since starting our digitisation processes. As we have manually corrected headings for all our articles our original plan was to not process these headings. However, due to the way our metadata is designed, the ALTO did not contain information about what a heading is conclusively, as this is stored in either a MPEG21 file or a METS file. Creating a pipeline in which both these files could be taken into account when re-OCRing was unfortunately too costly for this research project. We also tried to extract all headings in the evaluation, but the results were not certain enough to work with. We therefore chose to evaluate the existing version with corrected headings and the re-OCRed version which could have introduce more mistakes than we currently offer. This risk is of course always present when presenting new OCR results that have been automatically processed, but should be taken into account when examining the results.
Evaluation by IMPACT Centre of Competence
Once we had all results from the service provider we asked the IMPACT Centre of Competence to evaluate all data. For this they used the ocrevalUAtion tool which presents three measures; the character error rate, word error rate and the word error rate (order independent). Since we were evaluating the data for our mass digitisation platform Delpher we chose to work with the word error rate (order independent) in our final results. The word error rate is calculated as follows, where the order of the words is not taken into account for the order independent option:

Fig 1. Description of calculation of word error rate by Carrasco, Text Digitisation
Results
Since we subdivided the selection into time periods and OCR software the results can be displayed for various subsets. In figure 1 the results are displayed for the entire set, subdivided into all scans (Total), microfilm scans and scans from paper. All three columns are also subdivided into the three software packages used in digitisation (ABBYY 8.1, ABBYY 9 and ABBYY 10). The blue bars (left) represent the average word error rate for the original OCR files which we currently offer on Delpher. The orange bars (middle) represent the average word error rate for the reprocessed scans with ABBYY FineReader 11. And finally, where possible, the grey bars (right) represent the average word error rate for post-corrected OCR using Ochre.
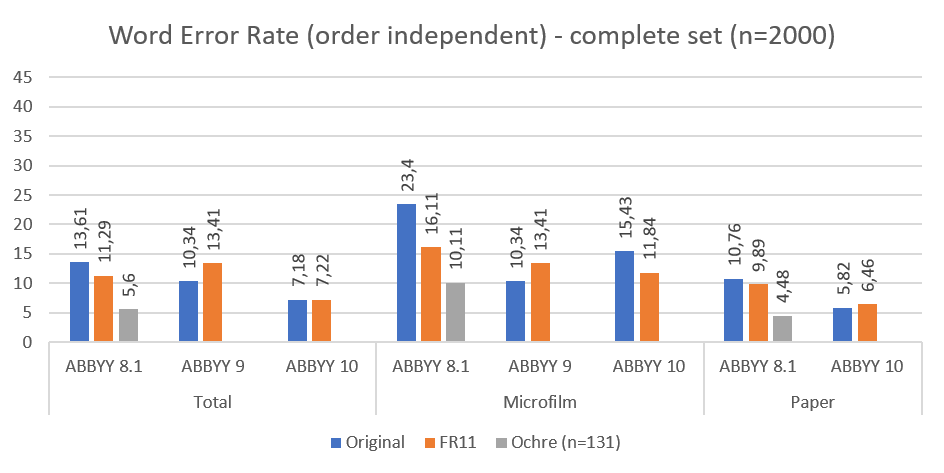
Fig. 2: Complete set compared on word error rate (order independent)
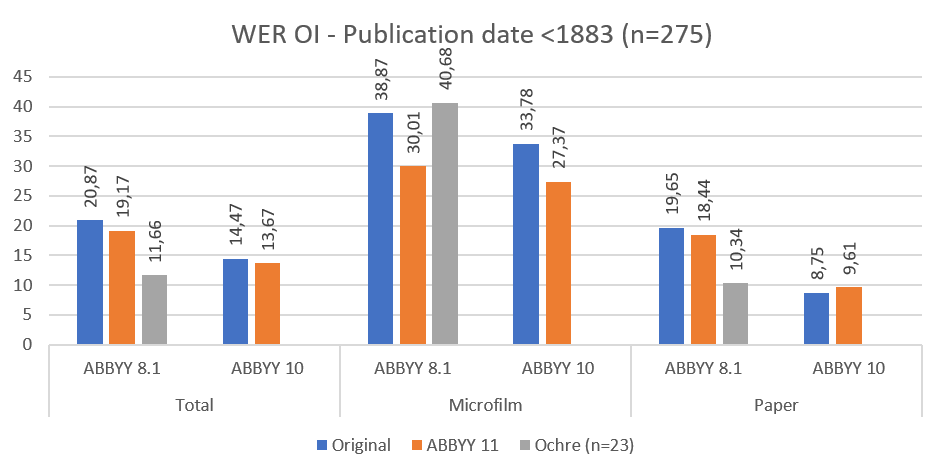
Fig. 3: Pages published before 1883 compared on word error rate (order independent)
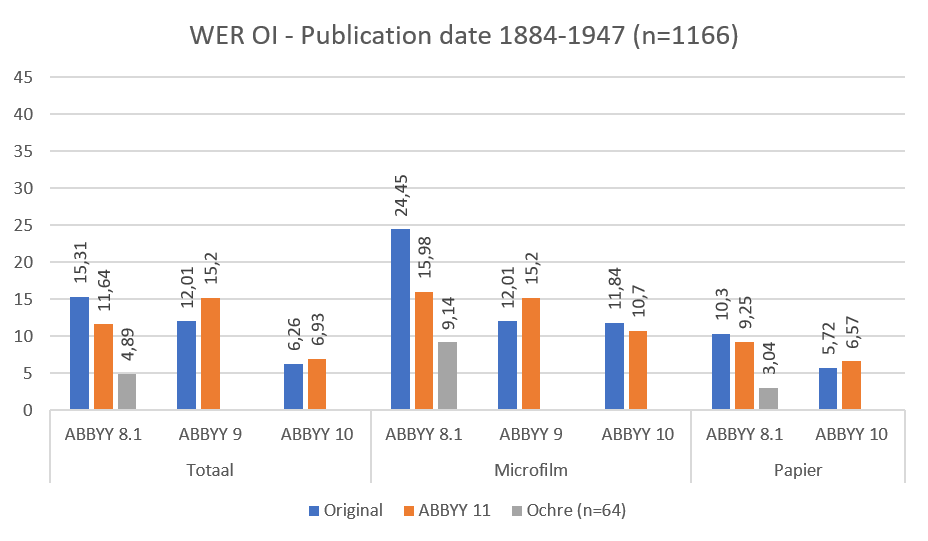
Fig. 4: Pages published between 1883 and 1947 compared on word error rate (order independent)
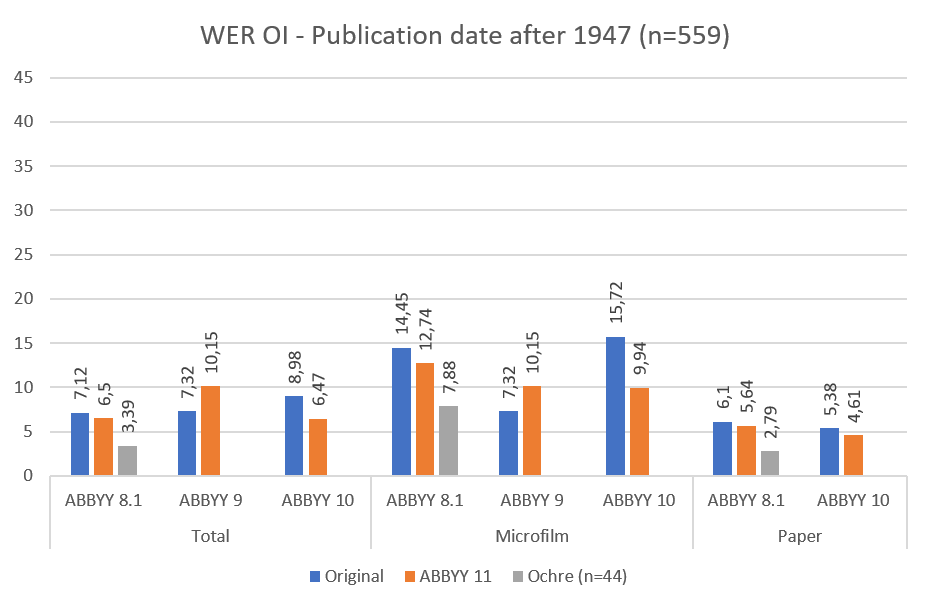
Fig. 5: Pages published after 1947 compared on word error rate (order independent)
Conclusions
After examining the results above, we concluded that for us at this moment it is not cost-effective to re-OCR legacy digitisation projects. The changes needed in our infrastructure are too disruptive to merit the little improvement reprocessing the pages brings. For ABBYY 9 pages (which were all from a single newspaper title) even more errors are introduced when reOCRing. For us, it is better to use the available resources to digitise more items. However, we do see potential in using post-correction tools such as Ochre for the material which is digitised from microfilms and processed with ABBYY 8.1. The recognition rate for those pages is so low that any improvement can be helpful to our users and further developing the tool in-house is worthwhile, also in understanding more about the quality of our digitisation outputs and about machine learning applications in a library.
Lessons learned
One of the major lessons we learned during this project is that ground-truth production is always more complicated and takes more time than what you plan for. Next to that, working with a digital collection that was not designed to publish new OCR versions presents issues which can be difficult to implement in a mass digitisation workflow. We saw this in for example the corrected headings, but also the lack of a version management process in our digital library system. This is something that we don’t have an easy solution for currently, but should and will be taking into account in future projects.
Next steps
After this project we will continue to work on the topic of OCR quality within the KB and KB Lab. We currently have Kimberly Stoutjesdijk working with us as an intern on evaluation of an open-source OCR engine, and have an internal working group consisting of colleagues from the Research, Collections, Digitisation, Information policy and DBNL departments tasked with researching the quality and possible correction of our digital collections. We hope to further develop Ochre for post-correction on microfilm scans and plan to use the ground-truth developed in this project for more evaluation projects.

The dataset of 2000 ground-truth files from our digitised newspaper collection is available for research purposes. Please contact [email protected] to access the dataset.
If you are interested in an internship using our digital collection, ground-truth datasets or OCR quality, please send us a message to discuss possible topics and options.