Introduction
Introduction
The goal of this dataset is to provide training and evaluation data for the development of the automatic visual object recognition tools in children’s book illustrations. This could be of great interest as a search tool for librarians and for humanity researchers who study the topic of imagery content in children’s books. In turn, this dataset exposes new challenges for computer vision researchers on the object recognition task, as it provides a novel type of visual data which is quite distant from the common photo-based benchmarks for object recognition such as COCO dataset. The dataset consists of illustrations of historical children’s books from public domain images published before 1880 together with the information about objects that appear in the illustrations.
Dataset Information
- The dataset is a subset of 1283 books with a total of 33k images.
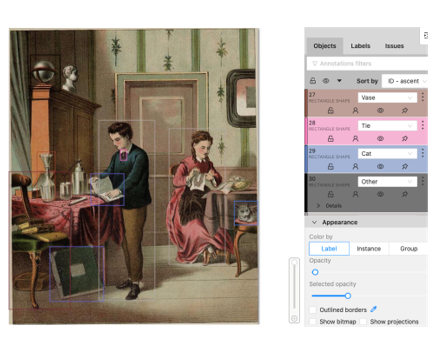
- 1512 images with 7210 objects (4.8 per image) are annotated including object class and bounding boxes.
- We used web-based CVAT (Computer Vision Annotation Tool) for the annotation of the dataset.
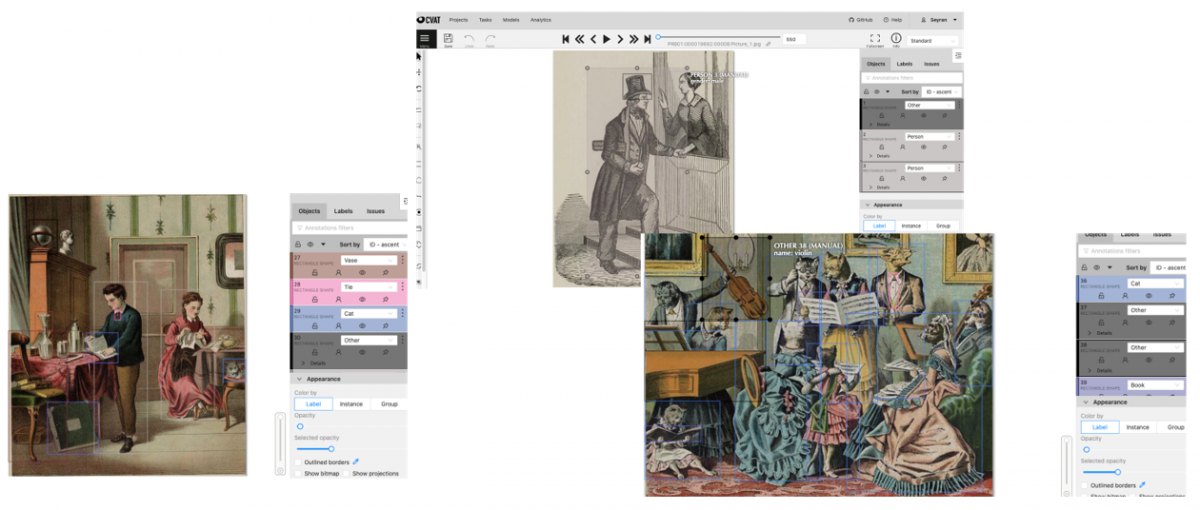
- We used the latest automatic object detection model YOLO: Real Time Object Detection for initialization of the tagging and we asked annotators to fix and add to the automatic tags.
- We had assistance from 18 taggers
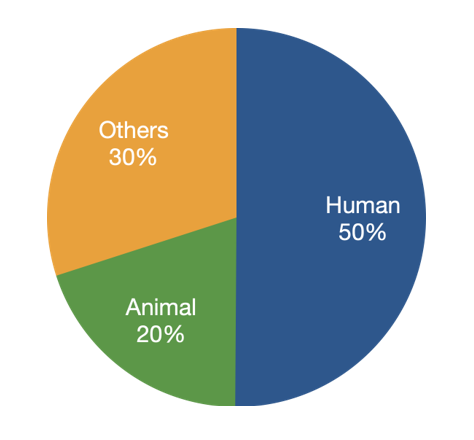
- Rough statistics:
Annotation Challenges
- Lack of standard ontology for the visual objects appearing in the children’s book which in turn lead to many instances of disagreement between annotators in the naming of the objects.
- Extremely unbalanced datasets that makes it difficult for the machine-learning model to learn from for the underrepresented classes.

Results
- A novel Machine-learning/Computer Vision benchmark dataset for object detection task that poses new challenges to the computer vision community.
- Introducing a new tool for humanity researchers for quantitative/data-supportive study of children’s book.
Acknowledgement
The authors wish to thank Antoinette Brummelink, Mirjam Cuper, Inge Bouts, Renske Koster, Karin Lodder , Trudie Stoutjesdijk, Rosemarie van der Veen-Oei, Roosmarijn de Groot, Fedor Wiedenhof, Lo van der Naaten, Renate van der Flier, Ron Hol, Madeleine van den Berg, Sharon van de Hoek, Martijn Kleppe, Heleen van Manen, Sara Veldhoen, Lotte Wilms for their assistance in the tagging of this dataset and making it available to the research community.
When using this data set we ask you to cite it as follows;
Khademi, S., Veldhoen, S., Wilms, L. (2021), Ot & Sien dataset. KB Lab: The Hague.
Access
Here is the link to the web-viewer of the dataset: https://kbresearch.nl/depth/?filter=&page=1
For complete access to the dataset please send an email to [email protected].