Introduction
Update 2 October 2025: the live demo is no longer supported by the KB Lab and has been removed.
Description
The Canonizer is a demonstration to show how well canonicity can be classified based on the text of a novel. This tool takes the text of a novel and classifies it as either canonical or non-canonical, based on its word frequencies. The classifier obtains an accuracy score of 72% on a validation set. This tool serves to illustrate what happens when the association between writing style and canonicity is extrapolated to new texts.
Data and model
The data we use to train the model come from a dataset of word counts of DBNL novels. This dataset is available here: https://lab.kb.nl/dataset/dutch-novels-1800-2000. The classifier is a Logistic Regression model that uses the 100k most frequent word bigram counts extracted from the corpus. The classifier is trained to predict a proxy for canonicity: a text with one or more secondary references is considered canonical, while a text without such references is considered non-canonical.
Citation
When using this tool we request you cite it as follows:
Andreas van Cranenburgh (2021). The Canonizer. KB Lab: The Hague.
Instructions
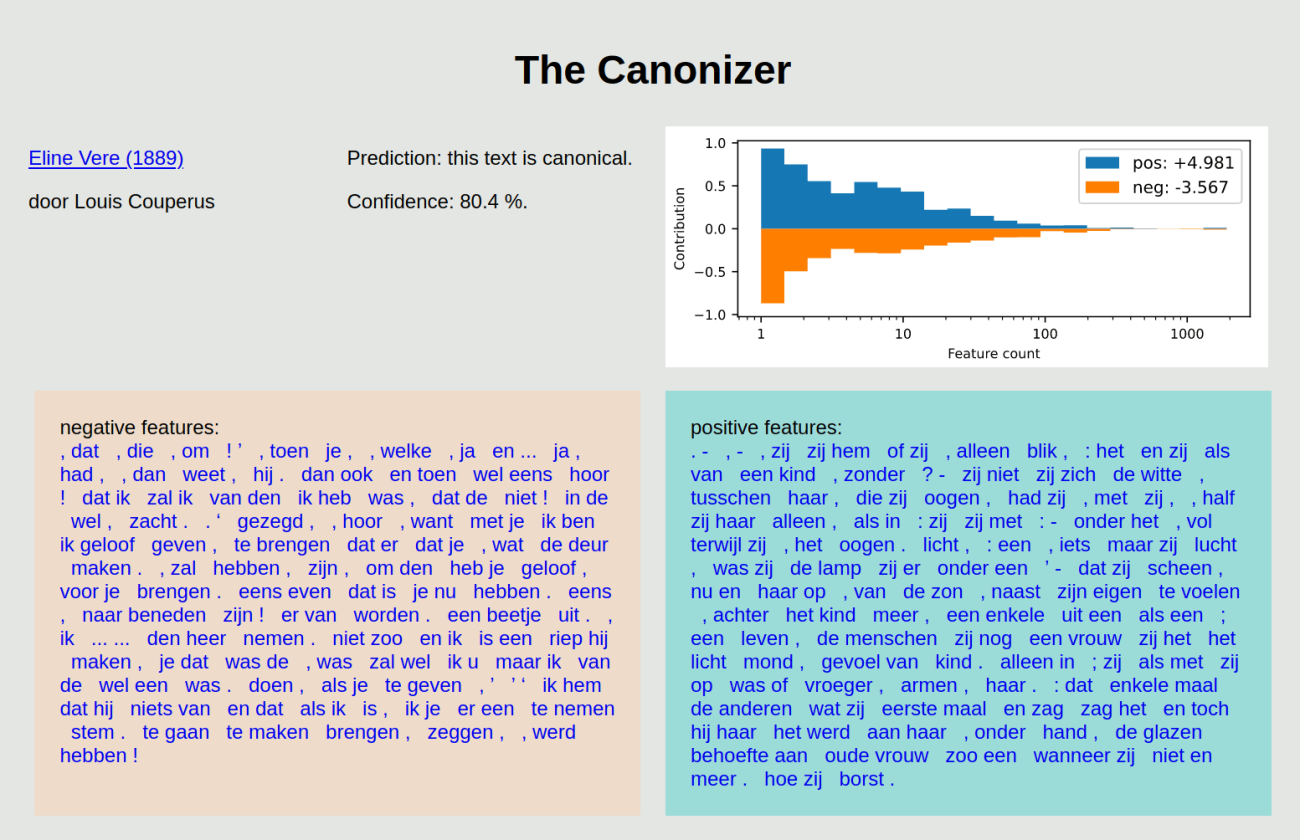
The Canonizer can either classify a novel from its training corpus (DBNL novels), or you can enter your own text.
The prediction includes a confidence score indicating how likely the classifier believes its prediction to be correct, as well as a visualization of the weight of evidence for and against the text being canonical, as considered by the classifier.
The classification is based on a large number of bigram features: the frequency of each feature is multiplied by the weight learned by the model, and the results are summed into a single classification score. To give an idea of the kind of features that contribute to the classification, a table is shown with the top 100 features with the highest frequency (in the selected text) and weight (as learned by the model). This list shows both features that are particularly frequent in (non-)canonical texts, as well as features that are not necessarily frequent, but highly indicative of a (non-)canonical text (such features will have a large weight). Clicking on a feature will take you to a page visualizing the frequency of this feature across the corpus.
Finally, an overview is shown of the top 10 texts in the corpus that are most similar in terms of their word counts. When a text from DBNL is used as input, this text will be at the top of the list with a similarity score of 1.000. Typically, other texts by the same author will also feature prominently in the list. The similar texts are also visualized in a scatter plot in which each text is represented by a dot, with similar texts plotted close together.