A dataset with page-level features and metadata of Dutch novels 1800-2000¹
Why is one novel still read, while another is forgotten? Literary scholars answer that the first is part of the canon, while the other is not. But what determines “canonicity”? Canonicity is a contentious topic. Literary scholars make lists of the most important authors of all time², but are such lists completely subjective? Do they systematically exclude important books by authors that do not fit a preconceived pattern such as white male? Could there be objective textual features that partly explain the value judgments leading to this demarcation? In this project I created a dataset for exploring such questions (as well as code and a tool). In this post I describe the corpus composition, metadata, and textual features that are part of the dataset. In the next post we will use the dataset to determine to what extent canonicity can be classified using textual features.
Corpus composition
The corpus is based on titles available in DBNL, a digital library of Dutch literature containing manually corrected OCRed scans of both primary and secondary texts. We select novels and novellas originally written in Dutch, excluding collected works, but including children’s novels. Several further selection criteria are applied on the available texts. The following table shows the number of titles remaining after each step:
1629 texts with TEI available
1431 after dropping translated and collected works
1409 first edition >= 1800
1377 latest editions
1359 language detection
1346 duplicate detection
If we plot the number of texts for each decade (based on year of first publication), we see the following distribution:
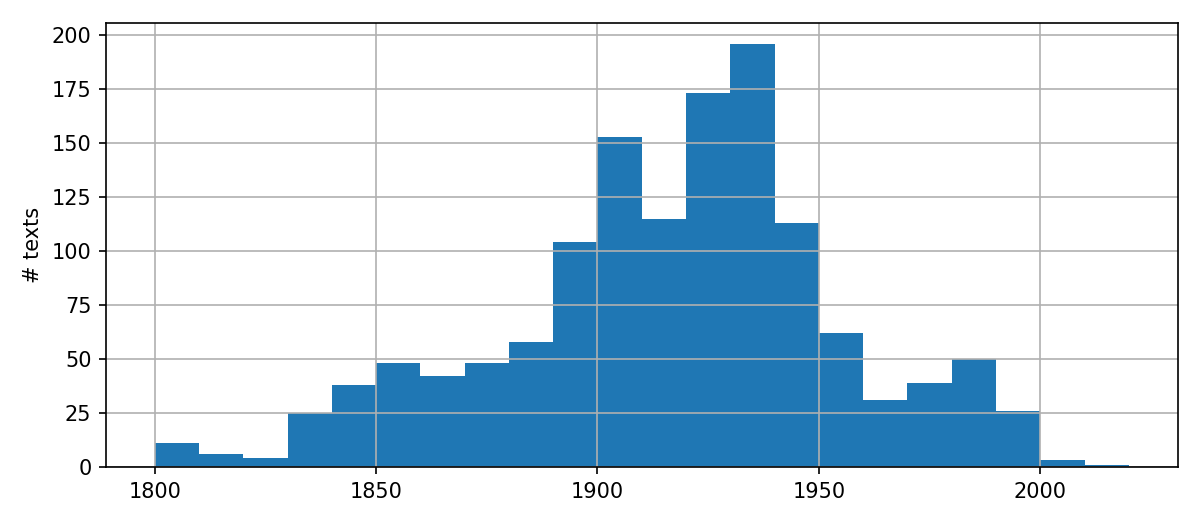
There is a strong peak of works in the first half of the 20th century. More recent novels appear in lower numbers since novels from this period are typically still being sold (e.g., Mulisch, Reve, Hermans). The lower number of 19th century books reflects the way novels are selected for digitization and the availability of source material.
Canonicity indicators
For each text we collect relevant metadata, including indicators (or proxies) of canonicity. We include the following indicators:
- MdNL 2002 canon list: whether the author is part of the list of 108 canonical authors composed by members of MdNL.
- Secondary references in DBNL: the number of times an author or title is referred to in critical and scholarly texts. Such secondary literature and the references they contain are structurally collected and curated by DBNL (example)
- GNT: the number of pages dedicated to the author in the textbooks Geschiedenis van de Nederlandse literatuur. Note that these textbooks are also used to select texts for digitization in the DBNL.
- Library: the number of copies of this title held in Dutch public libraries; the number of times this title was borrowed.
- Wikipedia/Hebban: the number of times the author is mentioned on Wikipedia or the book review site Hebban in the DBRD dataset.
The following scatter plot compares three canonicity indicators; note that both axes are logarithmic (an interactive version of this plot is available here):
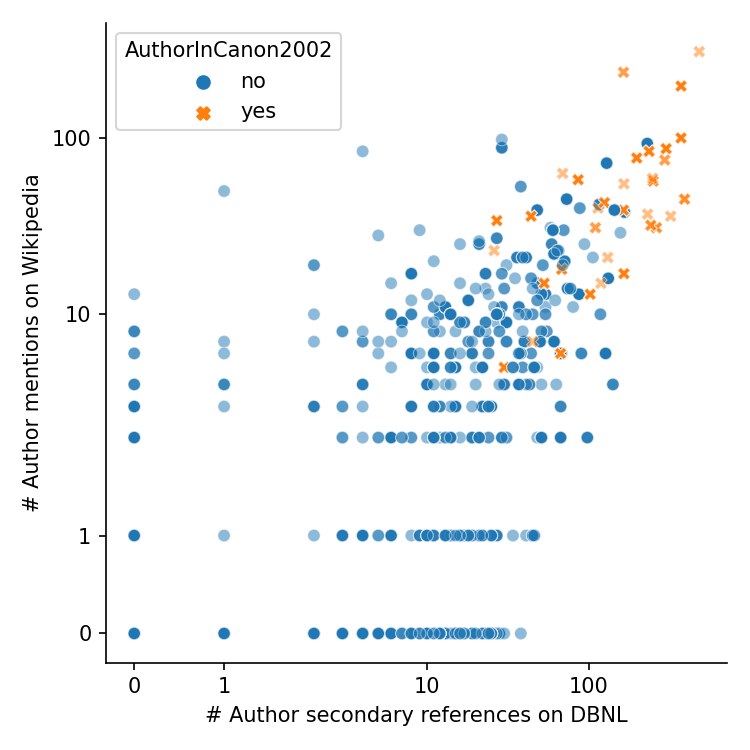
We can see a clear correlation between the two axes (r=0.704), and the authors on the 2002 canon list appear in the upper right, confirming that they are considered most prominent. Still, there are authors with many secondary references which do not appear on Wikipedia, and vice versa. The two datapoints in the upper right corner are Multatuli and Couperus, respectively.
On the one hand, these correlations support the construct validity of canonicity as a variable, since different measures are in agreement. However, these measures are definitely not independent; there is a degree of circularity to canonicity. For example, texts digitized by DBNL have been selected for their cultural significance, which may include canonicity, but a text being part of DBNL also cements its canonical status. An established author will typically receive more attention, regardless of the merit of their later work. Over time, only a select few older texts will still be read, which means that a few prominent texts will become more important, at the expense of other texts that are forgotten. It is very difficult to capture all of these dynamics in a model, and that is not in the scope of this project. The goal is rather to see how far we get in predicting canonicity when only considering textual features, without taking into account other influences. Ideally we would do this on a representative corpus, but as noted, DBNL does tend to favor canonical works.
We can gauge the coverage of our canonicity indicators by looking at the number of novels with a nonzero value for each indicator:
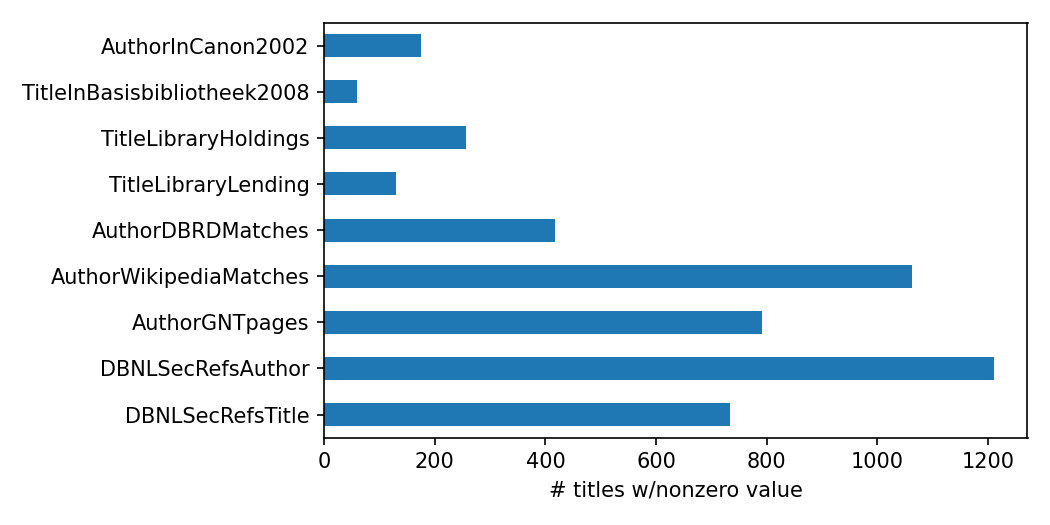
Based on the library lending data, we can already make a sobering observation about the books which are forgotten: more than 90% of them! In the rest of this project I therefore focused on the DBNL secondary references to titles as proxy for canonicity, since this indicator is both specific to particular titles (as opposed to authors), and leads to a relatively balanced, inclusive selection of canonical texts (as opposed to a small number).
Textual features
A large part of the corpus is still under copyright, so the dataset does not contain the full text of the novels. The dataset does contain a set of derived features, described in the following sections.
Page-level counts of unigrams and bigrams
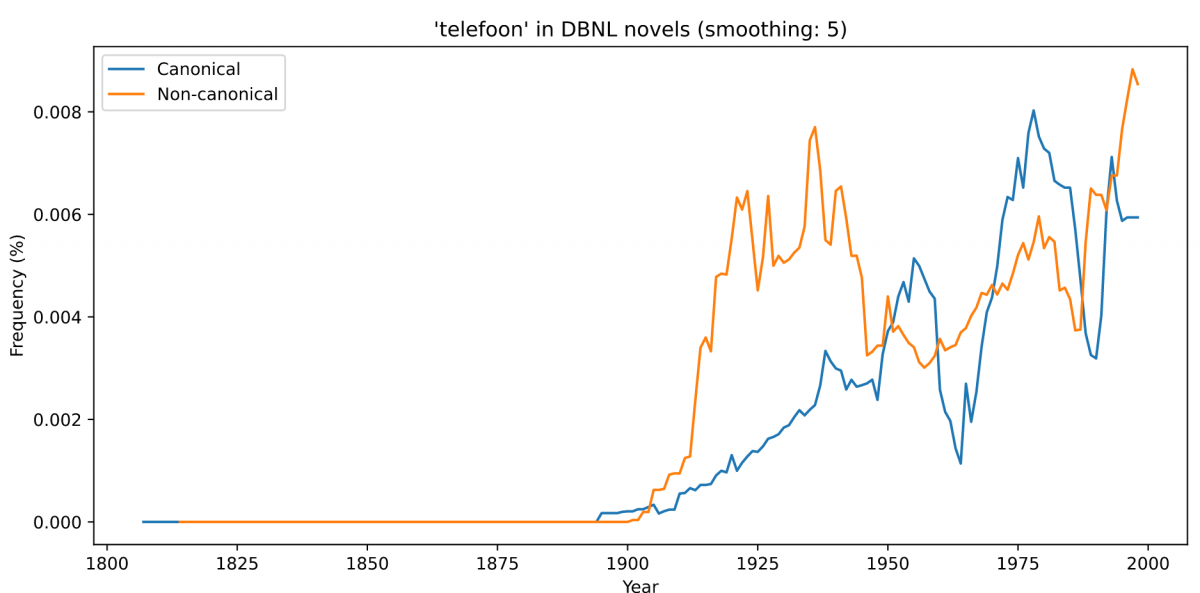
I.e., for each novel and page, the counts of words and pairs of consecutive words. For example, consider the frequency of telefoon (telephone); interestingly, it is first picked up predominantly in non-canonical novels:
Syntactic features for each text
These consist of text complexity metrics and frequencies of universal dependency relations and part-of-speech tags, extracted with udstyle.py. The next section and the next blog post show applications of these data.
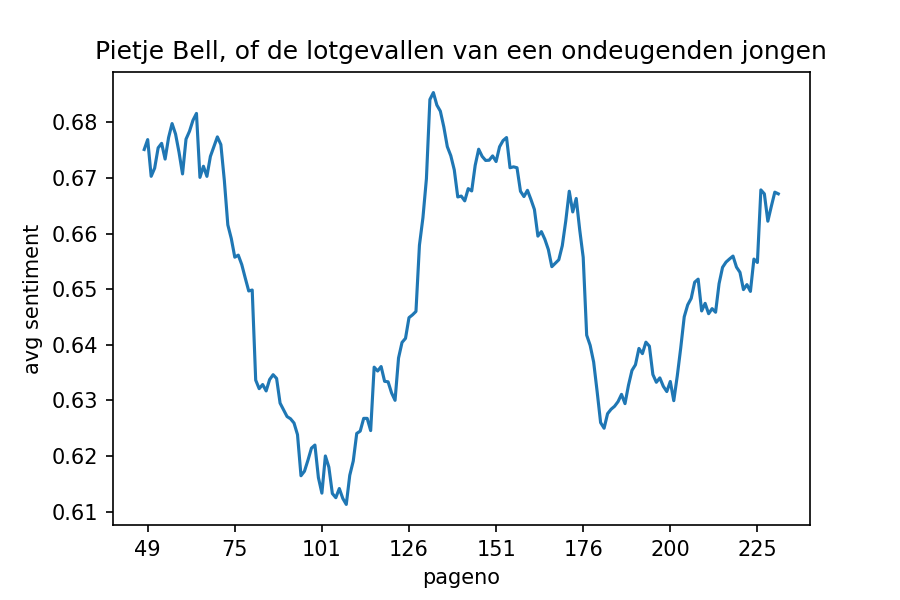
Page-level sentiment scores
Sentiment scores produced by the Pattern library. The following visualization shows the average sentiment score in a children’s novel, which can be used as a way of summarizing the plot shape:
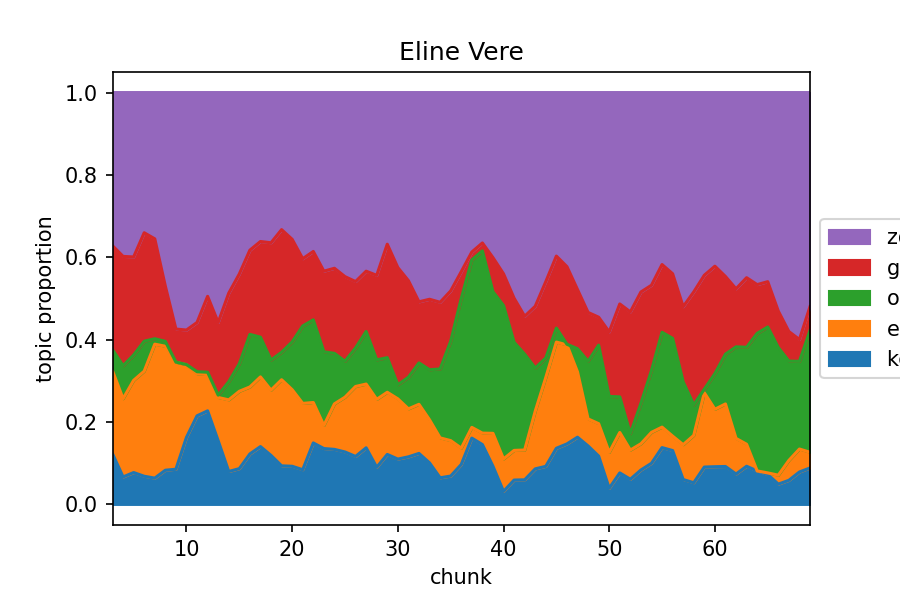
Topic weights from a Mallet LDA topic model
A topic model automatically discovers topics, bundles of commonly co-occurring words, in texts. For example, these are the 5 most prominent topics across Eline Vere by Couperus:
Skipgram word embeddings trained with fastText
Word embeddings are automatically learned representations that capture distributional aspects of word meaning. Word embeddings are useful for exploring semantic relatedness and as a component in NLP systems. Although pre-trained word embeddings exist that have been trained on much larger datasets, such datasets typically only consist of contemporary web text.³
Corpus statistics
Since the corpus is diachronic in nature, we can analyze the change of textual features over time. One particularly prominent variable that stood out in exploratory analysis is sentence length. The following figure shows the mean sentence length (y-axis) over time (x-axis). There is a strong, significant negative correlation of -0.448, indicating that sentences in novels are getting shorter. Similar correlations appear if instead of sentence length we consider the number of clauses per sentence, number of modifiers, or average dependency distance.
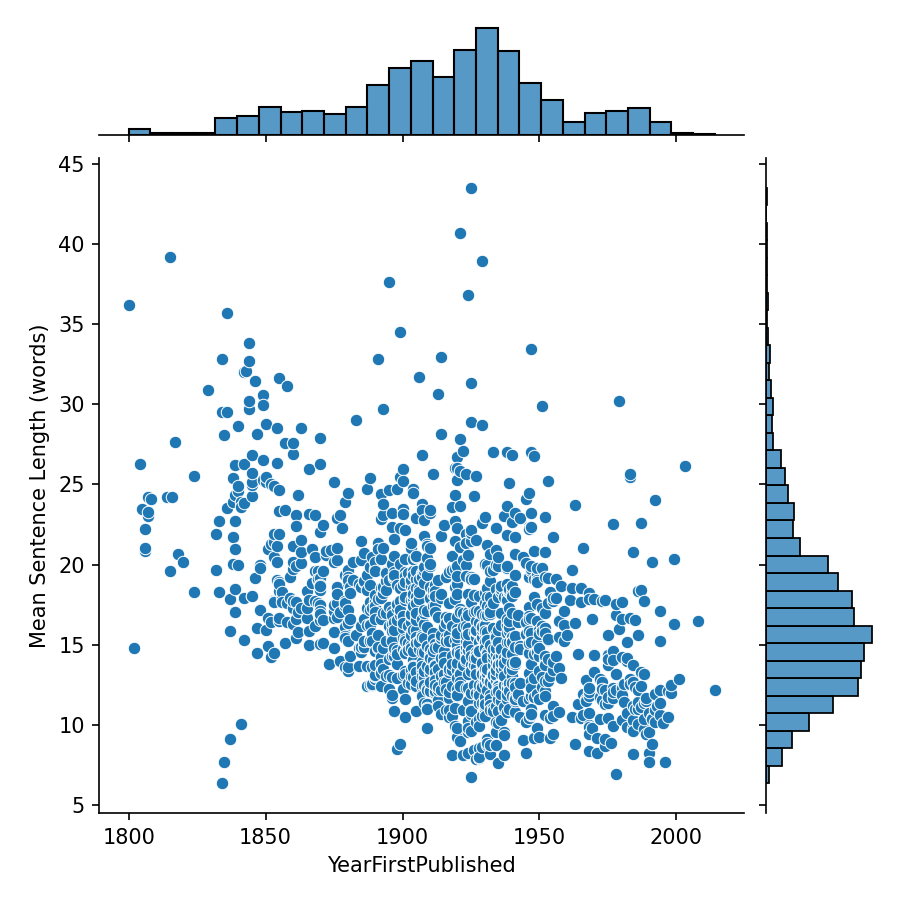
Previous work⁴ has reported a similar decrease in sentence length for English. Some of the more recent novels have a mean sentence length below 15, which could be explained by a large proportion of dialogue, which tends to contain short questions and answers. However, sentence length is also associated with text complexity.
In the next blog post we address the question to what extent canonicity can be predicted from some of these textual features.
Acknowledgements
The author wishes to thank Trudie Stoutjesdijk and Edde de Kok from Data Warehousing, Victor van der Wolf from the OZP team, and Coen van der Geest and Erik Vos for sharing data.

Related
Part 2. Machine learning canonicity in Dutch novels 1800-2000
Related tool: Canonizer
Related dataset: Dutch Novels 1800-2000
Notes
1. I wish to acknowledge the contributions of the following people to this project. Michel de Gruijter and Sara Veldhoen for guidance and support in weekly meetings. Trudie Stoutjesdijk and Edde de Kok from Data Warehousing, Victor van der Wolf from the OZP team, and Coen van der Geest and Erik Vos for sharing data. Gertjan van Noord for help with spelling normalization. Ryanne Keltjens, Arno Kuipers, and the Digital Scholarship Team for helpful comments.
2. For example: Bloom, Harold (1994). The Western Canon. Harcourt Brace.
3. A previous researcher-in-residence project analyzed gender bias in word embeddings trained on newspapers in Delpher: https://lab.kb.nl/about-us/blog/introduction-gender-bias-historical-newspapers.
4. Rudnicka, Karolina. "Variation of sentence length across time and genre." Diachronic corpora, genre, and language change (2018): 220-240. Štajner, Sanja, and Ruslan Mitkov. "Diachronic stylistic changes in British and American varieties of 20th century written English language." Proceedings of the Workshop on Language Technologies for Digital Humanities and Cultural Heritage. 2011.