Machine learning canonicity in Dutch novels 1800-2000
In a previous post, we introduced a dataset of Dutch novels with textual features and metadata. In this post we explore the dataset with the aim of answering the question to what extent canonicity can be predicted using textual features. We first explore syntactic characteristics, and then train a classifier on lexical frequencies.
Motivation and approach
The question that motivated this project was: Why is one novel still read, while another is forgotten? Novels that have become classics are also called canonical, i.e., part of the literary canon. One component of canonicity is literary quality, which was addressed in the project The Riddle of Literary Quality. This project showed that it is possible to explain ratings of literary quality for contemporary novels using textual features. Specifically, 76% of the variation in ratings could be explained using a machine learning model.¹ This suggests that literariness is measurable in texts. However, this project only considered contemporary novels, for which literary ratings were collected in a large reader survey.
This project applies similar distant reading methods to gauge the predictability of canonicity using a diachronic corpus of novels from 1800-2000. As indicator of canonicity we use references of literary scholars and critics. We extract page-level word frequencies to use as representations for machine learning and parse the texts to obtain statistics for syntactic features. We then train supervised models to explore how well the canonicity of a novel can be predicted from its textual features.
Exploring syntactic features
The corpus was parsed using the Alpino Parser, and the output was converted to Universal Dependencies. When we look at the relative frequencies of part-of-speech (POS) and dependency tags, the following tags show the strongest positive correlation with the number of secondary references (i.e., these are more frequent in more canonical novels):
| 0.261778 | amod | adjectival modifier |
| 0.224071 | acl | adnominal clause |
| 0.224048 | case | case marking (e.g., prepositions) |
| 0.215297 | ADJ | adjective |
| 0.174690 | nmod | nominal modifier |
These correlations suggest that canonical texts tend to contain more complex language with more descriptions. Conversely, we can also look at tags which are less frequent in canonical novels:
| -0.227582 | compound:prt | phrasal verb particle |
| -0.224516 | obj | object |
| -0.217005 | AUX | auxiliary verb |
| -0.201338 | ccomp | clausal complement (but, because..) |
| -0.186859 | nsubj:pass | passive nominal subject |
These tags could indicate an avoidance of perfect verb tenses, passive constructions, and separable verb particles (e.g., up in clean up) in canonical novels. The negative correlation for objects seems harder to interpret, but a possible explanation is that canonical novels use more intransitive verbs (e.g., the water boils vs I boil the water), which leaves relatively fewer direct objects.
Machine learning results
We can train a model to directly predict the number of secondary references given a text (a regression task); however, initial experiments did not produce good results. We therefore simplify the task to a binary classification: a text is canonical if it has at least one secondary reference, and non-canonical if it has none. We could pick a higher threshold (and thus consider a smaller number of works as canonical), but experiments showed that this threshold gave the best results.
In order to get a fair assessment of how predictable this outcome is for texts the model has not been trained on, we apply cross-validation. We use regularized logistic regression (i.e., a linear classifier)² and obtain the following scores:
| Precision | Recall | F1-score | Support | |
| Non-canonical | 71.7 | 63.2 | 67.2 | 612 |
| Canonical | 72.1 | 79.2 | 75.5 | 734 |
| Accuracy | 71.9 | 1346 |
In other words, for a given novel, in more than 7 out of 10 cases, the canonicity can be correctly predicted from textual features (compared to a score of about 50% with random guessing). This model makes its predictions based on lexical features of the novels, namely the frequencies of the 100,000 most frequent bigrams (combinations of two consecutive words). This classifier therefore combines information from a large number of features to make its predictions. Still, we can inspect the features which are considered most predictive by the classifier to see whether these features are interpretable:
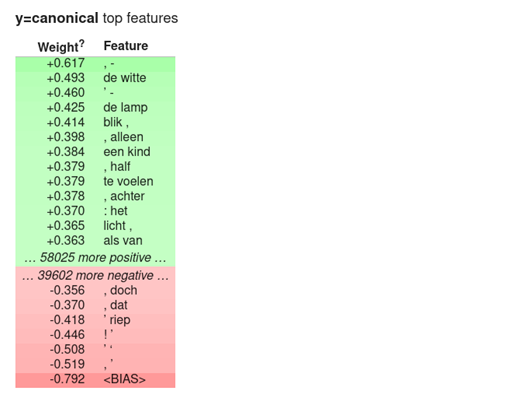
The prominent role of punctuation is striking. Weight refers here to learned weight from the (linear) classifier; given a feature, a weight larger than zero indicates that, all else being equal, the more frequent this feature is, the more likely it is that the text is canonical, and vice versa for negative weights. The classifier makes a prediction for a given text by multiplying its weights with all the frequencies of that text; when the sum is larger than 0, the text is predicted to be canonical.
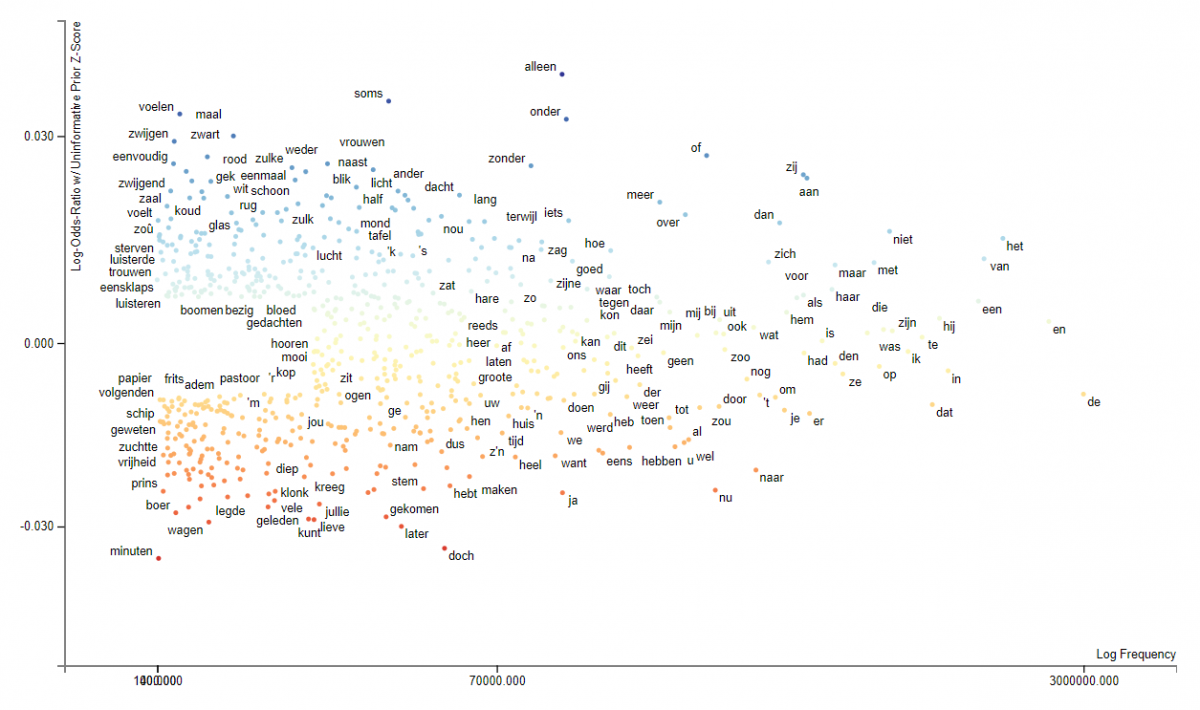
The following plot gives an overview of a model trained on words instead of bigrams, with the x-axis corresponding to frequency, and the y-axis to being predictive for canonical or non-canonical texts:
View the interactive version of this plot on Github.
Another way in which we can try to interpret the behavior of the classifier is to look at the mistakes it makes, and in particular mistakes made with a high degree of confidence:
Misclassifications: novel is canonical, but predicted as non-canonical
| Score | Year | Author, Title |
| -1.29 | 1948 | H. de Roos, De schippers van de Kameleon |
| -0.95 | 1915 | C.J. van Osenbruggen, Wilde Jo |
| -0.87 | 1974 | A. Alberts, De vergaderzaal |
| -0.77 | 1974 | Hans Vervoort, Zonder dollen |
| -0.74 | 1911 | Emile Erckmann, De loteling van 1813 |
Two things stand out about these novels: the first two novels are children’s novels, and they all received only a single secondary reference. On the subset of children’s novels, the classifier scores 87.3% on recognizing non-canonical texts, but 30.6% on canonical texts, indicating a clear learned bias towards expecting children’s novels to be non-canonical. As for the other novels, they could be stylistic outliers compared to the rest of the corpus and therefore underestimated by the model. The opposite explanation, that the model is right and their reception as canonical is undeserved, is not plausible.
Similarly, we can consider the opposite kind of mistake, and focus again on the predictions of which the classifier is most certain:
Misclassifications: novel is non-canonical, but predicted as canonical
| Score | Year | Author, Title |
| 1.28 | 1912 | Israël Querido, De Jordaan: Amsterdamsch epos. Deel 4 |
| 1.15 | 1903 | Israël Querido, Menschenwee. Roman van het land. Deel 1 |
| 1.02 | 1942 | Emiel van Hemeldonck, Kroniek |
| 0.86 | 1924 | Em. Querido, Het geslacht der Santeljano's |
| 0.81 | 1921 | Em. Querido, Het geslacht der Santeljano's |
The Querido novels (Israel and Emanuel are brothers) are part of a series, and the other parts do have secondary references, so these are arguably not mistakes. Van Hemeldonck is an author with quite a lot of secondary references, but not for Kroniek; this appears to be a metadata issue, since DBNL does contain a review of this work. These observations suggest that with manually-assigned canonicity labels, the accuracy could be higher.
The classifier is available as an online demo, which offers the possibility to explore the features used for classifying particular texts in the corpus, or your own text.
Discussion and Conclusion
Let’s take stock of what was achieved, what was not, and what still remains to be done. These results only scratch the surface of what can be investigated with this corpus of novels and metadata. The main result is that we found a relatively strong link between canonicity and textual features: the predictive model obtains an accuracy score of 71.9%. This leaves 29.1% which may be explained by non-textual factors, such as luck or cultural capital, or using more sophisticated methods, such as deep learning and richer linguistic and narratological features of the texts. These results suggest that canonicity may be more difficult to predict than literariness, as was done in The Riddle of Literary Quality; however, the results are not fully comparable since The Riddle used literariness ratings based on a large reader survey and a synchronic, contemporary corpus.
There were two main challenges in this project. The corpus has good coverage of novels from 1900-1950; for other periods, representativeness is lacking. This has two reasons. First, the availability of digitized texts, and second, the requirement within DBNL to have permission from each publisher to make texts available for research. Recent developments in the EU concerning text and data mining exemptions to copyright suggest that this may be less of an issue in the future.³
The other challenge was more practical in nature. A text may contain multiple works, a single work may be spread over multiple volumes, and finally, a single work may be manifested in multiple different versions. Although these relations can be inferred from the available metadata and TEI tags, fully disentangling such relations proved challenging, and I chose not to pursue this within this project.
Looking at the future, I want to suggest several directions for future work using the dataset made available by this project. Rather than treating each text as a bag of words, the page-level features can be used to analyze the structure of the texts and their narratives. Examples of relevant methods are dispersion-based metrics (to what extent is the use of a word concentrated in a specific part of the text, or spread evenly), and co-occurrence statistics (which words tend to be used together).
This project used a simple proxy for canonicity based on secondary references, which was binarized for classification experiments. A better operationalization of canonicity would integrate multiple sources of information into a continuous score.⁴ In addition, canonicity is a dynamic concept affected by perspectives and periods; ideally, such variables would also be taken into account, although obtaining such data is challenging.
Another aspect is the degree of language change over time, in general, and also in particular in relation to canonicity. Again, using more sophisticated models, it may be possible to determine interactions of time as a variable with textual features, and what this says about the evolution of canonicity over time.

Related
Part 1. A dataset of Dutch Novels 1800-2000
Related tool: Canonizer
Related dataset: Dutch Novels 1800-2000
Notes
1. Andreas van Cranenburgh, Rens Bod (2017). A Data-Oriented Model of Literary Language. Proceedings of EACL, pp. 1228-1238. http://aclanthology.org/E17-1115
Andreas van Cranenburgh, Karina van Dalen-Oskam, Joris van Zundert (2019). Vector space explorations of literary language. Language Resources & Evaluation. vol. 53, no. 4, pp. 625-650 https://doi.org/10.1007/s10579-018-09442-4
2. Regularized linear models are simple, interpretable, and work well for long texts and large numbers of features, but they cannot learn feature interactions; applying more sophisticated models (e.g., neural networks) is left for future work—or as an exercise for the reader, since the data is available!
3. See for example: Margoni, Thomas and Kretschmer, Martin, A Deeper Look into the EU Text and Data Mining Exceptions: Harmonisation, Data Ownership, and the Future of Technology (July 14, 2021). http://dx.doi.org/10.2139/ssrn.3886695.
4. For example, see this recent paper: Brottrager, Stahl, Arslan (2021). Predicting Canonization: Comparing Canonization Scores Based on Text-Extrinsic and -Intrinsic Features. Computational Humanities Research Conference.