Introduction
Welcome to the dataset page of the KB web collection. The dataset page and its analyses will be updated every summer.
Very short introduction about the KB web collection & web archives in the Netherlands
The KB started selecting a small collection of websites in 2006, archiving (or in web archive terminology: harvesting) these websites since early 2007. The web collection represents a ‘reasoned selection’ of the Dutch domain: Every particular website has been selected manually, focussing on the Dutch language, culture and history. This is why the KB calls it their web collection instead of web archive. The collection also includes websites containing innovative content, representing current trends on the Dutch domain. The KB actively searches for popular websites or websites that are currently relevant for the Dutch society.
The KB is not the only heritage institution in the Netherlands to archive selections of the Dutch web. According to our information, web archiving started in The Netherlands by the Dutch Documentation Centre of Political Parties (DNPP) in the year 2001. This organisation harvested websites of Dutch political parties, politicians and political movements. There are also some specialized archives that run web archiving projects, like the Groningen Archives (collects websites about the region Groningen) and the Netherlands Institute for Sound and Vision (collects a selection of websites of the Dutch broadcast organisations).
For more information about the different web archives in the Netherlands please visit the Register Webarchieven website [Dutch].
Web archiving process
KB primarily uses (and co-develops) the Web Curator Tool in combination with webcrawler Heritrix developed by the Internet Archive. The Web Curator Tool (WCT) is a tool for managing selective web harvesting for non-technical users. The underlying database is a PostgreSQL database.
In the WCT the curator creates a Target Record for each website selected for harvesting. A Target Record may consist of one or multiple domains (seeds). An example is the KB Target Record which contains the seeds:
- https:// www. kb.nl/
- https:// inschrijven.kb.nl/
The KB Lab website has its own Target Record. In most cases a Target Record contains one seed (as shown in the pie chart ‘Seeds per Target Record’).

Figure 1: Most Target Records in the KB web collection have one seed that gets harvested.
In the Target Record (TR) specific settings will be determined such as schedule frequency (when and how often a website is harvested). The Target Record may also be enriched with basic metadata like a subject code or a collection label. It is with the help of these data that I will try to give a global overview of how the KB web collection has grown over time. All analyses are currently based on data as from 2009 until 2024. The only exception is the analysis of the schedule frequencies because that data was not available for 2014 and 2020.
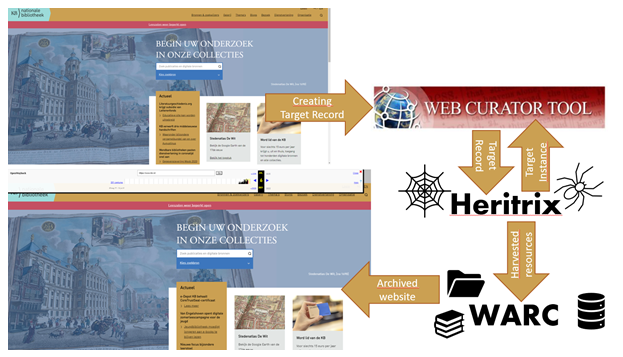
Figure 2: Web archiving process.
Based on Target Record parameters the Web Curator Tool communicates with the webcrawler Heritrix. WCT supplies the relevant information to the crawler: When to harvest the website and how. In case of the KB website it will (among many other things) tell Heritrix to harvest two seeds:
- https:// www. kb.nl/
- https:// inschrijven.kb.nl/
According to Target Record parameters WCT will also tell Heritrix to set the data limit at 10 Gigabyte and ensure the website will be harvested once every six months (limits and settings from 2020). Heritrix will then attempt to harvest the website on the set date(s) and time, putting every resource it finds within scope in a container-file, which is called a WARC file. This WARC file is stored in the archive; it is used to reconstruct the archived website in a Wayback Machine so that users can view it. The WARC file also contains a lot of metadata about when each resource (webpage, stylesheet, PDF, etc.) was harvested and its volume. In the Web Curator Tool a Target Instance is created each time a Target Record instructs Heritrix to harvest a website. In the Target Instance record you can find information about the result of the harvest and the log files.
However, as mentioned earlier, for the moment I am mostly interested in the Target Record information that tells Heritrix what to do.
Source
The Web Curator Tool, primarily a workflow management tool, does not retain old versions of the Target Record information. So when a curator changes the schedule frequency (for example), the information of the former schedule frequency can no longer be found in that specific data field. To map the history of the web collection I therefore had to look for other sources that contained information about old Target Record information. The needed information was found inside the selection-overviews. These overviews are made every couple of months. The most recent one is available on the website of the KB (found on the web collections FAQ page). Here users can find an overview of the current web collection [Dutch].
Although not all selection-overviews survived over time, I found enough original lists (print-outs from the WCT database) to continue this project. However, the available information required some pre-processing necessary prior to analysis. For example, Target Records appeared twice or thrice in the original overviews, so redundant records needed to be removed while keeping all relevant information. If a Target Record had two schedules it would appear twice in the original list. I made a second column (named schedule 2) and transferred the information to one of the records and removed the other. This way I made sure that no information was lost. This process of deduping and cleaning (removing double or triple Target Records whilst securing all relevant information) was done for nearly all original lists found.
Update 2025
The first version of this page was made in 2021. Based on my experiences preprocessing the data I started collecting my own data directly from the WCT database. So every dataset since 2021 was made through my own datadump and in the month October, making most of the preprocessing of the data described above here redundant.
Selection overview - data available
X data is available
V data is not there, but has a valid reason
| Creation date selection overview: year-month | State (TR) | Schedule (TR)** | Collection (TR)*** | Subject (TR) | Date selected (TR) |
|---|---|---|---|---|---|
| 2009-10 | X | X | V | X | X |
| 2010-10 | X | X | V | X | X |
| 2011-05 * | X | X | V | X | X |
| 2012-10 | X | X | V | X | X |
| 2013-10 | X | X | V - Started | X | X |
| 2014-12 | X | Not available | X | X | X |
| 2015-03 * | X | X | X | X | X |
| 2016-09 | X | X | X | X | X |
| 2017-10 | X | X | X | X | X |
| 2018-10 | X | X | X | X | X |
| 2019-04 * | X | X | X | X | X |
| 2020-10 | X | Only 1 schedule available for each TR | X | X | X |
| 2021-10 | X | New method **** | X | X | X |
| 2022-10 | X | X | X | X | X |
| 2023-10 | X | X | X | X | X |
| 2024-10 | X | X | X | X | X |
* Because not all original lists survived the months that were analysed differ per year. For the sake of consistency I tried to find original lists generated in or close to the month of October. But as you can see in the table, this was not always possible. Please keep this in mind when you view the diagrams below.
** Another notable information gap was with the schedule information that is missing (2014) or incomplete (2020). Consequently both 2014 and 2020 are missing in the analysis of schedule frequency.
*** In the case of the collection information, the KB started to create special web collections in 2013. So it makes sense that the first time this information appears is in 2014.
**** After publication of the original version of this dataset page, created in 2021, I made a better query that included schedule type information. Because of this schedule type could be analysed in more detail starting with the dataset from 2021-10.
I will explain each type of data in detail in their corresponding analysis, but here is an example of the Target Record data found in the original lists (after pre-processing).
| Subject | 01 |
|---|---|
| Name | Koninklijke Bibliotheek |
| Primary seed | https://www.kb.nl/ |
| Date selected | 2007-10-31 11:24 |
| State | Approved |
| Scheme ** | 57 15 6 1/6 * |
| Scheme 2 * | [ empty ] |
| Scheme 3 * | [ empty ] |
| Subject | NL-blogosfeer |
* Column added during pre-processing.
** Starting 2021-10 the schedule information would be supplemented with schedule type. It would look like this: 57 15 6 1/6 ? *, - 6. With the ‘- 6’ indicating the cron schedule being a half yearly schedule.
Analyses
Before discussing the analyses, it is important to stress that I have chosen for (mostly) bar charts. This is because of the irregularities in month and because schedule data is missing. I discovered that bar charts visualised these deficiencies best.
Total number of Target Records

Figure 3: Number of Target Records in the KB web collection for each year.
Goal: To give a picture of the growth of the number of Target Records. As of 2024 we have a little under 25.000 Target Records in the web collection that the archive attempts to harvest or have been harvested.
Data used: I have used the column ‘date selected’ from an original list from 2024 (October). This column contains the date and time a Target Record was made. From this information I selected the year and counted how many Target Records were created in a particular year. So this graph shows for each year all the Target Records that are there up to October 2024. Below you can see the number of new Target Record created each year.

Figure 4: Number of Target Records created per year.
State
Goal: Now we know how many Target Records in total there are, it is interesting to know which ones were being actively harvested. Not all Target Records are active. Some have ended.
Data used: For this I used all original lists mentioned above. The column used, was ‘State’.

Figure 5: What part of the KB web collection is still actively being harvested by Heritrix based on the state of the Target Record?
In the bar chart ‘State’ you see three types of Target Records:
- Active
- Ended
- Completed
With active Target Records, for the most part, Heritrix still attempts to harvest the seeds. For more information about how ‘active’ an active Target Record is, see the analysis of the schedule frequency below.
Completed Target Records have finished their schedules. No new harvest has been scheduled (yet). A Target Record can be completed in one year and be active in the next if it is given a new schedule by a curator.
Ended Target Records have stopped and are no longer harvested (even if they have a schedule). A curator has to end a Target Record manually and it can be finished for several reasons. The most common reason is that the website is no longer online. A website can be completely gone but it is also possible that it has migrated to a new domain. If the latter is the case and if the domain has significantly changed, a new Target Record is made. Otherwise the hyperlink is just updated within the existing Target Record (and it remains active). A new Target Record is also created if several websites merge into one new website. This sometimes happens with project websites. The project first has its own website, but when completed it becomes a part of an existing website of the organisation behind it. It also happens when different businesses merge. One or multiple Target Records are then stopped and continued as a new Target Record. A final reason for a Target Record to stop is because a website (or part of a website) was archived for a special collection. Normally the KB archives whole websites, but for special collections (the Coronavirus COVID-19 collection for example) we also archive specific parts of websites for a shorter amount of time. These seeds get their own Target Records and can be stopped if the special collection or event has ended.
Update 2025
In 2024 the decline of the XS4ALL domain set in, causing thousands of websites to vanish from the internet. As a significant special collection, this also affected our web collection as a lot of Target Records were ended. For more information read the blogpost 'No longer XS4ALL'.
Schedule frequency
Goal: Let’s take a closer look at the Target Records which are still active. Within this group I wanted to give an overview of how often they are harvested and if this has changed over time. A Target Record can have multiple schedules.
Data used: I used the original lists from 2009 until 2013, 2015 until 2019 and 2021 onwards. In 2014 this data was missing and in 2020 it was incomplete. I only used schedules from Target Records that had an active state.
Pre-processing: At the start of this page there was an example of a schedule ‘57 15 6 1/6 ? *’. Schedules in Heritrix are written as a cron. Because type information was missing I manually gave each schedule a type by looking for strings that indicated their frequency (such as ‘/6’ for twice a year and ‘/3’ for quarterly).
From 2021 onwards this was no longer necessary because I added schedule type information to the cron schedules. Because of this I only needed to count the schedule types (ANNUALLY, HALF_YEARLY, QUARTERLY, BI_MONTHLY, MONTHLY, WEEKLY, DAILY, CUSTOM). This gave me a more detailed view into the type of schedule. Because of this daily, weekly and monthly became a separate category. So be mindful that 2021 did not all of a sudden introduced new schedule types but schedules that were a part of the custom group before, just got their own category.
Analyses:
- Combination of schedules a Target Record has (one, two or three schedules).
- Overview of the amount of Target Records with multiple schedules (two or three).
- Schedule frequency of all schedules total. Analysis of all available schedules. Keep in mind that a Target Record may have multiple schedules as shown in analyses one and two. Analysis of the ratio of all schedules within proportion of each specific year.
- Custom schedules. Analysis of all types of custom schedules from April 2021 and October 2024.
- 'To Date’. Analysis of schedules with an end date (made in July 2021). To what collection do they belong and have the Target Records they belong to really ended?
- Schedule frequency of all schedules without ‘Yearly’. Analysis of all available schedules except the group ‘Yearly’. Keep in mind that a Target Record can have multiple schedules as shown in analyses one and two.

Figure 6: Shows how many schedules there are per Target Record.

Figure 7: Section of figure 6: only shows the Target Records with two or three schedules.

Figure 8: Shows the total amount of active schedules and their frequency in ratio to their total.
In the bar chart ‘Schedule frequency ratio’ you’ll see several types of schedules:
- Yearly
- Every six months
- Quarterly
- Bi-Monthly (every other month)
- None
- Custom
Starting from 2021 you can also find the types:
- Monthly
- Weekly
- Daily
The custom schedules are a heterogeneous group of schedules. There are serval uniquely made schedules to harvest websites on particular moments with all kinds off frequencies. Up until 2021 this group also contained daily, weekly and monthly schedules. There are also schedules that only run for a particular year. This means that after this year, though the state of a Target Record is still active, the schedule is inactive and the Target is no longer harvested.

Figure 9: Most custom schedules are only harvested in one particular year. These schedules are inactive after that particular year. If a Target Record does not have another schedule, this Target Record is no longer harvested (even though the state can still be active).
Another group that has the state ‘active’, but is not being harvested, is the group ‘None’ with no schedule at all.
The last challenge is that some schedules have a ‘To Date’, an end date that can be manually specified. Because this information was not in the original lists I could only analyse how many there were in 2021. There were little over 300 schedules with a ‘To Date’ in an active Target Record in July 2021 (according to database analysis). Most of these are ‘Quarterly’ schedules from the Society critical websites collection. Target Records belonging to this collection received two schedules: A quarterly schedule with a ‘To Date’ (ending in Q4 2020) and a yearly schedule with a ‘Start date’ (starting in 2021) but without ‘To Date’. These Target Records are therefore still active.
This analysis was redone in July 2022, August 2023 and August 2025, but there was no significant change.
It is important to note that some schedules have a ‘To Date’ because these schedules appear active in this analysis, but actually aren’t because their schedule has ended.
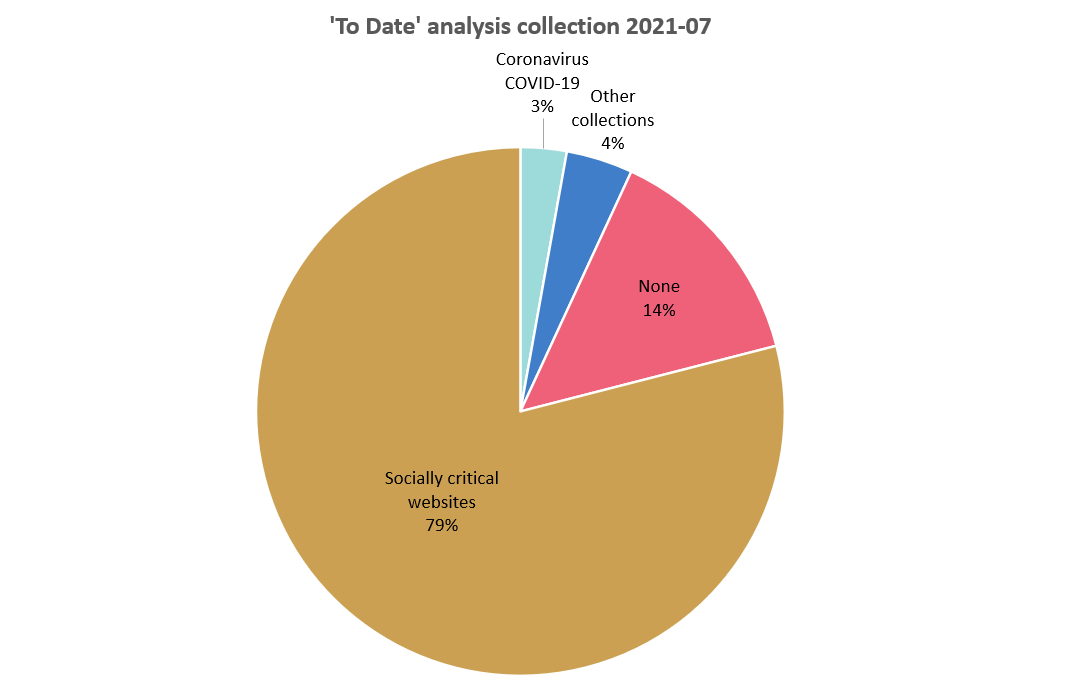
Figure 10: Analysis of schedules with a ‘to date’ shows that most of them belong with the Socially Critical web collection. It is not a problem this groups has an end date, because these Target Records also received a yearly schedule.
As you can see, harvest frequency has changed significantly over time. At the start of the web collection Target Records were harvested mostly ‘Quarterly’ or ‘Every six months’. This changed in 2015-2016 to ‘Yearly’ as most used schedule frequency. You can see the decline in ‘Quarterly’ and ‘Every six months’ schedules more clearly if use a ratio analysis or you leave the yearly schedules out of the analysis.

Figure 11: The decrease in not-yearly schedules is also very visible in absolute numbers.
Special Collections
The KB started assembling special collections for the web collection in 2013 in similar fashion as the UK Web Archive. A Target Record may belong to multiple special collections. It can be given a collection label when it is created, but also receive a collection label retrospectively. The Wadden collection, for example, started in 2017. The curator searched for already existing Target Records that belonged to the collection and added the collection tag. This does not happens for all collections though.
For more updated information about the special collections visit the KB webcollecties page. (Dutch)
The special collections are (with English translation and explanation if necessary):
| Dutch title | English translation | Closed * collection | Period **** | Explanation | Further reading |
|---|---|---|---|---|---|
| Ambassades en consulaten | Embassies and consulates | 2014 - present | Web collection of Dutch embassies and consulates in other countries. Cause for this collection was the possibility that some embassies (and their websites) would disappear (2014). This didn’t happen. What did happen in 2017, was that all websites merged into one big website. | ||
| Bedrijf- en productschappen | No English equivalent ** | Y | 2014 | 1 January 2015, all ‘bedrijfs- en productschappen’ were dissolved. | KB special web collections page. |
| Caribisch Nederland | Caribbean Netherlands | 2008 - present | Websites related to or from the Caribbean Netherlands. | KB special web collections page. | |
| Chinees Nederland | Chinese Netherlands | Y | 2018 | Web collection about the Chinese immigrant community in the Netherlands. | KB Lab page - web collection Chinese Netherlands |
| Coronavirus COVID-19 | Y | 2020 - 2022 | Web collection about the corona pandemic. It is also a Dutch contribution of Dutch websites to the international IIPC collection. *** | IIPC collection – Novel Coronavirus (COVID-19) – Dutch contribution | |
| Handwerken | crafting, needlework | 2018 - present | Web collection about showcasing a wide range of (textile) craft topics. | KB special web collections page. | |
| Internetarcheologie | Internet archaeology | Collection of early internet websites (older than the year 2001). | |||
| Nederlands-Indië / Indonesië | Dutch East Indies / Indonesia | 2023 - present | Web collection about the (recent) history of the Dutch East Indies, Indonesian people in the Netherlands, Dutch people with an Indonesian past and all persons and organisation whom concern themselves with Indonesian history and culture in the Netherlands. | KB special web collections page. | |
| Kloosters | Monasteries | 2015 - 2016 + 2020 - present | Also websites from orders, congregations and abbeys in the Netherlands. | KB special web collections page. | |
| Levensbeschouwing en religie | Modes of belief and religion | Y | 2021 - 2022 | Web collection that preserves a cross section of the diversity of religion in the Netherlands by archiving the websites of a wide range of communities, institutes, foundations, companies, small businesses, blogs and many other kinds of private initiatives. | Collection description on Zenodo [Dutch]. |
| LHBT+ | LGBT+ | 2018 - present | Collection of websites about and by the LGBT+ community in the Netherlands. Made in collaboration with IHLIA, a heritage organisation involved in collecting information about the LGBTI community and making it accessible. | ||
| Maatschappijkritische websites | Society critical websites | Y | 2016 - 2018 | Socially critical websites from or about the Netherlands in the period 1993 – 2017. | Collection description Society critical websites on Zenodo [Dutch] |
| Nederland in de Eerste Wereldoorlog | The Netherlands during World War One | Y | 2014 - 2019 | Dutch contribution of Dutch websites as a member library of the International Internet Preservation Consortium (IIPC), to provide a transnational perspective on the war's centennial commemoration. *** | IIPC collection – World War I Commemoration – Dutch contribution |
| NL-blogosfeer | Dutch blogosphere | Y | 2018 | Collection of Dutch weblogs. | KB Lab page – Web collection NL-blogosfeer |
| 500 jaar Reformatie | Y | 2016 - 2017 | Commemorating 500 years (Protestant) Reformation in 2017. | KB special web collections page. | |
| Tocht naar Chatham (1667) | Raid on the Medway | Y | 2017 | Attack by the Dutch Navy on English warships in 1667. | KB special web collections page. |
| XS4ALL | Dutch website provider named XS4ALL | Y | 2019 | Collection of websites from the provider XS4ALL. Some of which date back to the early days of the internet. | Collection description XS4ALL-homepages on Zenodo [Dutch] |
* Collections that have ended. No new Target Records will be added. This distinction was first added in 2022.
** A ‘bedrijfschap’ was a sectoral organisation under public law in the Netherlands of companies that worked in the same industry. A ‘Productschap’ was a sectoral organisation under public law in the Netherlands of companies that worked with (or processed) the same raw material in successive stages. Both mostly occurred in the agriculture sector.
*** All collections mentioned here are collections in the KB archive, but the KB also contributes (in selecting websites) to transnational web collections such as the Olympic Summer 2012. These collections are defined and archived by the IIPC. The Netherlands during World War One and the COVID-19 collections are exceptions as they also became a collection in the KB repository.
**** Period in which active collecting took place
Data used: I used all collection tags available and simply counted them. All original lists were used because the data was complete in all lists. All states were used as well. Please keep in mind that there is some inconsistency in month as explained at the start of this article.
For analysis I have divided the collection into two groups. Collections with an active collection and collections which are closed. This distinction started in 2022, version 2 of this page).
The group larger than one thousand Target Records only contains the XS4ALL and Internetarcheologie collections. This is partly because lots of XS4ALL websites were older than the year 2001 and therefore also received the Internetarcheologie tag. This also explains the growth in the Internetarcheologie collection.

Figure 12: If you remember figure 4 (number TR created each year) you can find the reason for the peak in 2020 here: the XS4ALL collection was added. Over 3.000 websites were added in the course of 2019 – 2021. XS4ALL is a closed collection, Internet archaeology is still active.

Figure 13: Overview of all collections which are still active.

Figure 14: Overview of all the collections where active collecting no longer takes place.
Subject
When creating a Target Record, the curator also adds a subject code. A Target Record can have a maximum of 2 subject codes.
Data used: I used all subject codes available and simply counted them. All original lists were used because the data was complete in all lists. All states were used as well.

Figure 15: Total number of Target Records, divided into those with one and those with two subject codes. Most have just the one.
Top 11 most used subject codes
Keep in mind that a Target Record may have 1 or 2 subject codes as shown in the analysis here above. There are 33 subject codes in total. This is the top 11 most used subject codes in October 2024.

Figure 16: Eleven most used subject codes.
| Top 11 | Subject code | Subject text |
|---|---|---|
| 1 | 23 | Urban planning, architecture, art, photography, film, radio, television |
| 2 | 31 | History, biography |
| 3 | 24 | Spare time, sports and games |
| 4 | 01 | General |
| 5 | 19 | Technology, industry * , crafts |
| 6 | 04 | Sociology, statistics |
| 7 | 03 | Religion, theology |
| 8 | 06 | Law, government administration |
| 9 | 09 | Commerce |
| 10 | 18 | Medicine |
| 11 | 08 | Education, nurture |
* The Dutch term used for industry is ‘nijverheid’. It indicates small scale workshops and industry at home as well as large industry.
Target Instances
At the start of this article I mentioned that I was mostly interested in Target Records. However I have also taken a crack at counting the number of harvests there are for each year. For this the Target Instances that were selected are those that harvested more than one page, excluding the Target Records that are crawled daily. This resulted in a nice first impression, but it is not yet as clean as I’d like. It still contains some failed harvests.
Goal: Give a rough impression how many successful harvests there have been for each year. If you combine them you have the total amount of harvests available for research.
Data used: In this case I made my own query on the Web Curator Tool Postgresql database and received the information directly from there.

Figure 17: Because of Quality Assurance schedule frequencies were lowered and failed harvests reduced. This is why in 2021 the total number of Target Instances diminished. In 2024 the decrease is caused by XS4ALL websites disappearing from the live web and the subsequent ending of their Target Records.
Technical Description
This is a short overview of the techniques the KB web archive used to harvest the websites.
| Date | Web Curator Tool | Heritrix |
|---|---|---|
| September 2007 - August 2019 | WCT 1.14.4 | Heritrix 1 |
| August 2019 - August 2020 | WCT 2.0.2 | Heritrix 3.3.0-SNAPSHOT |
| August 2020 - May 2021 | WCT 3.0.0-SNAPSHOT | Heritrix 3.3.0-LBS2016-02 |
| May 2021 – May 2023 | WCT 3.0.0 | Heritrix 3.3.0-LBS-2016-02 |
| May 2023 - Present | WCT 3.1.4. | Heritrix 3.4.0. |
Notable other technical impacts:
In 2024-2025 there was a migration project moving the webcollection and the software to different hardware. Because of this there was a freeze in harvesting in april 2025. Impact on forming the collection was kept to a minimal.
Researching the web collection
As there is no legal deposit in the Netherlands and due to copyright reasons, the collection can only be studied in the reading rooms of the library. Visit the KB website for more information about visiting the web archive.
Further reading
For more information about which websites are in the current collection visit the FAQ web collection page on the KB website [Dutch].
For more general information about the KB web archive and the web archiving team visit the web collection page on the KB website [Dutch].
When using this dataset we ask you to cite it as follows;
I. Geldermans, Historical growth of the KB web archive (version 5, 19-08-2025) KB Lab, the Hague. https://lab.kb.nl/dataset/historical-growth-kb-web-archive.
This article is governed by the Creative Commons Attribution 4.0 International Licence. Please use this attribution: ©2025 National Library of the Netherlands/Iris Geldermans, CC BY 4.0.
