Introduction
Printed personalia lists and gazetteers have guided visitors and researchers through libraries and archives for centuries. Their use has declined in the last two decades, as information retrieval (IR) techniques made the quest for knowledge easier and easier. Search engines, digital transcriptions and 24/7 online access are blessings to whoever seeks to find particular information from vast collections like those of the National Library of the Netherlands (KB). At the same time, more can be found than ever before. The goal is no longer to locate the right shelf or borrow the appropriate book, but rather to be linked to a specific page, paragraph, line or word within a matter of seconds.
The amount of potential search results has grown exponentially in the digital age thus increasing the need for registers and indices of people, places or even ethnic classifiers like ‘natives’ (Dut. inlanders) or ‘blacks’ (zwarten). The annotation scheme introduced for capturing such so-called entities in the colonial newspapers of the KB has been discussed in the previous weblog “Tagging the news from the Indies”. Importantly, this scheme went beyond annotating persons and places by also focussing on references to social-ethnic groups—corporations, official positions, ethnic classifiers—, quantities—consisting of the (spelled out) numerator and denominator, e.g. ‘five villages’—and textual references (e.g. a letter referred to in a newspaper article). The way in which the resulting seven entity types are connected in single phrases—e.g. a consecutive reference to position and name: ‘the librarian Jacob Geel’—allows a process of customised entity linking using Regular Expressions (regex) and SPARQL queries; a topic worth discussing at another occasion. In addition, the resulting indices of persons, places and other variables can be used as ever-extending dictionaries and regex queries that are added as extra layers of entity recognition upon the NER model, thus increasing its overall recall. In short, entity processing is more extensive than NER alone, still NER poses specific challenges due to the extent to which it leans on deep learning rather than conventional programming logic. This blog will attend to the second and third research question posed during the first Researcher-in-Residence project of 2021¹:
2. Can historical Named Entity Recognition (NER) be improved by applying it to natural languages from two different language families which are connected through colonial ties?
3. Given the mixed language use in colonial newspapers, is it possible to measure the extent to which texts are based on the Dutch language or the Indonesian ones by looking at the contexts in which entities occur?
Question 2 can only be answered positively for historical Indonesian. The post-independence revisions of spelling conventions (Ejaan Melindo in 1959, Ejaan Baru in 1967, Ejaan yang Disempurnakan in 1972 and Ejaan Bahasa Indonesia in 2015) and rapidly changing vocabulary make modern Indonesian significantly different from colonial era Malay. Unlike for Dutch and English, modern texts taken from born-digital materials hardly suffice for creating a machine learning model for historical documents written in Malay, Sundanese and Javanese. The F1 score for a NER model based on modern Indonesian but trained on more than 350.000 tokens from late colonial and early independence Indonesian text, drops below 55 percent (F1: 0.5483). Interestingly, applying a mixed model based on colonial era Dutch and Indonesian languages, lifts this score up to 72 percent (F1: 0.7222). This improvement was not detected in the NER model designed for historical Dutch. This last worked better without Indonesian languages being included.
Adding Indonesian training data to Dutch NER models led to unforeseen consequences. For instance, the preference for initials and acronyms in late colonial and early independence Indonesian texts resulted in some full stops in Dutch texts to be recognised as names of persons and organisations. This clearly is not desirable as it indicates catastrophic interference. Overall, it is true that NER models can be improved by combining natural languages from two different—although historically connected—language families into one model. At the same time, the efficiency of this multilingual or polyglot method depends on the extent to which the languages have changed over the previous half a century. Historical Dutch and Indonesian are both low-resource languages but because the former resembles its modern counterpart more closely, it benefits more from the massive datasets extracted from Wikipedia and social media which underlie current deep learning techniques.
Creating mixed language NER models
There are indications that NER models for historical Dutch would also be able to benefit from multilingual methods when more control is applied to the sequence transformation on which the current State of the Art (SOTA) machine learning (ML) models are based. Like other ML models, these so-called transformer models encode input sequences, turn them into vectors and decode them back into output sequences. But they also transform the sequences during the encoding and decoding process by focusing on certain parts of the input sequence which are calculated to be most relevant for the output sequence. This self-attention layer is crucial to both the training and application of NER models.²
Sequences are indexed letters, words and strings in which all elements are positioned in a certain order. The same elements can be repeated within them as they are still distinguishable through their rank within the sequence. Transfer models struggle with outputs which are radically different from the input, as is the case with translations or word embedding of entities which occur in both Dutch and Indonesian texts. Part of the difficulties experienced when creating mixed language NER models thus comes down to the different sentence-structures of Indo-European and Austronesian languages.
The recently introduced T5 text-to-text framework seeks to mediate this issue.³ It has the potential to select text sections in Dutch which are relevant for sequences in Indonesia. The upcoming Multitask Unified Model (MUM)—a successor to the Bidirectional Encoder Representations from Transformers (BERT) used during this Researcher-in-Residence project—will incorporate this new technique thus potentially allowing training translated phrases between Dutch and Indonesian. The Dutch summaries of the Indonesian and ‘Malay-Chinese’ press made by Office of Popular Literature (Bureau der Volkscultuur - Afdeeling Pers) between 1918 and 1940 would be particularly suitable for such a purpose. Still, the unexpected effects of mixing Indonesian and Dutch models which is mentioned above shows BERT is not yet up to this challenge. Moreover, the diversity of sources used in this project and the disbalance of entity types within them (see graph 1 until 8) will also complicate the use of MUM on our database. We therefore opted to abandon the aim to mix different Indonesian and Dutch sources together for the Dutch NER models.
Besides the mixed model (gado2 or gado-gado), we divided the languages into four main corpora: Dutch (1600-1800), Dutch (1800-2000), Indonesian (1600-1800), and Indonesian (1800-2000). The NER model created for these separate corpora as well as the mixed one can be accessed at Hugging Face as ‘nl1’, ‘nl2’, ‘indo1’, ‘indo2’ and ‘gado_gado’ (https://huggingface.co/willemjan). We invite interested readers to apply these models for their research and hope that they will be improved upon by a wider community of researchers to create a standard reference for entity recognition of historical Dutch and Indonesian languages. The following paragraphs give suggestions on how to pre-process the input data to obtain the best possible results from these models.
| Dutch, 1600 – 1800: Ground Truth (GT) | Dutch, 1800 – 2000: GT | |||
|---|---|---|---|---|
| Pages | 1.547 | Pages | 379 | |
| Lines | 53.720 | Lines | 29.632 | |
| Tokens | 372.691 | Tokens | 197.614 |
| Indonesian Languages, 1600 – 1800: GT | Indonesian Languages, 1800 – 2000: GT | |||
|---|---|---|---|---|
| Pages | 14 | Pages | 419 | |
| Lines | 322 | Lines | 75.583 | |
| Tokens | 2.122 | Tokens | 359.590 |
| Dutch, 1600 – 1800: Total dataset (GT and automatically classified content) | Dutch, 1800 – 2000: Total | |||
|---|---|---|---|---|
| Pages | 382.845 | Pages | 19.782 | |
| Lines | 16.230.300 | Lines | 1.456.777 | |
| Tokens | 93.114.181 | Tokens | 10.509.449 |
| Indonesian Languages, 1600 – 1800: Total | Indonesian Languages, 1800 – 2000: Total | |||
|---|---|---|---|---|
| Pages | 3.628 | Pages | 38.276 | |
| Lines | 136.584 | Lines | 6.663.466 | |
| Tokens | 843.427 | Tokens | 31.507.154 |
| Dutch, 1600-1800 | Combined model with Dutch and Indonesian | |
|---|---|---|
| Precision | 0.9327 | 0.8889 |
| Recall | 0.8899 | 0.7843 |
| F1 | 0.9108 | 0.8333 |
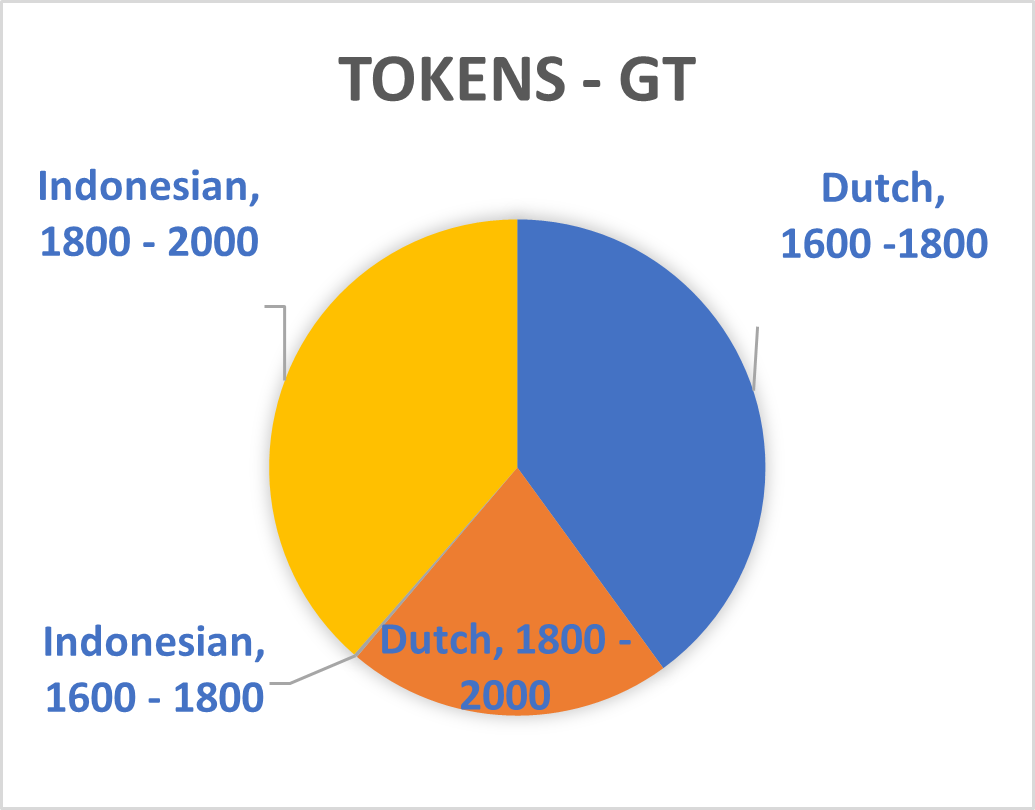
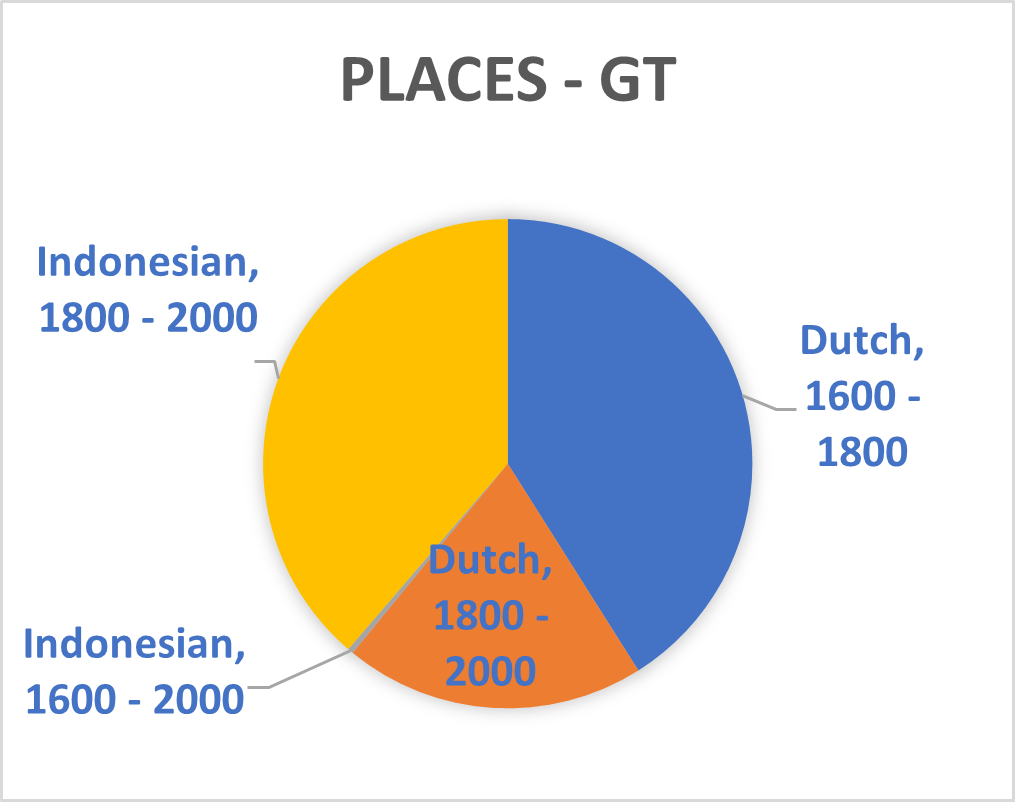
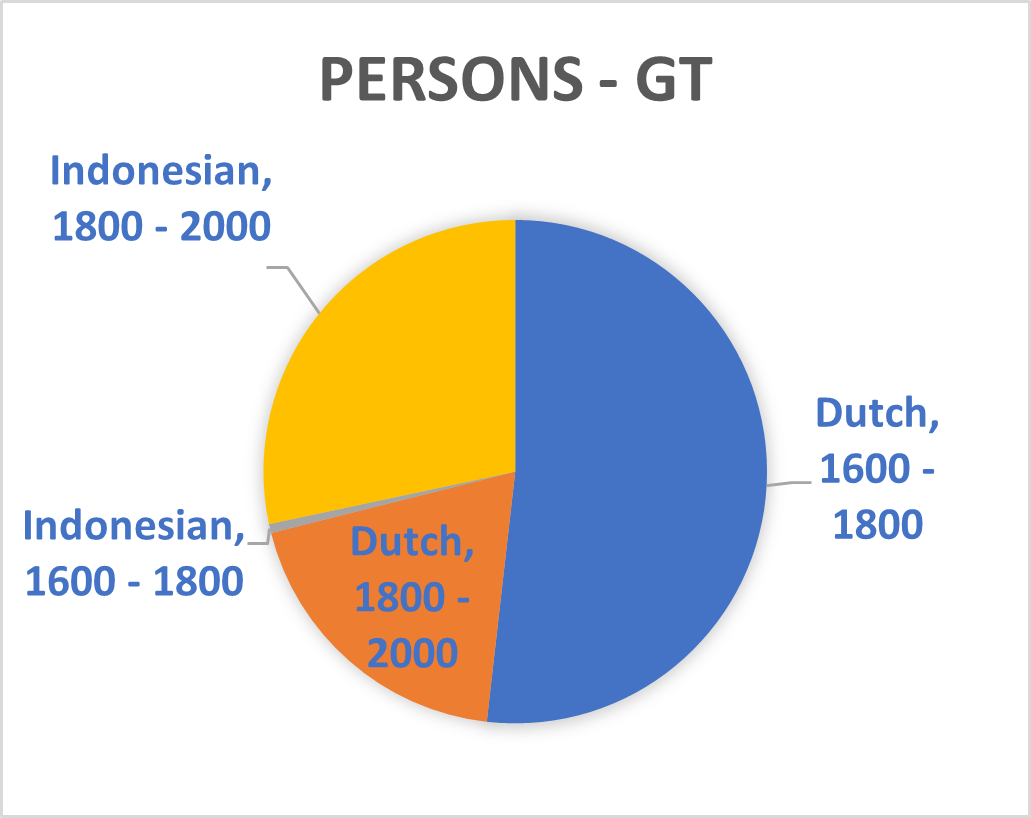
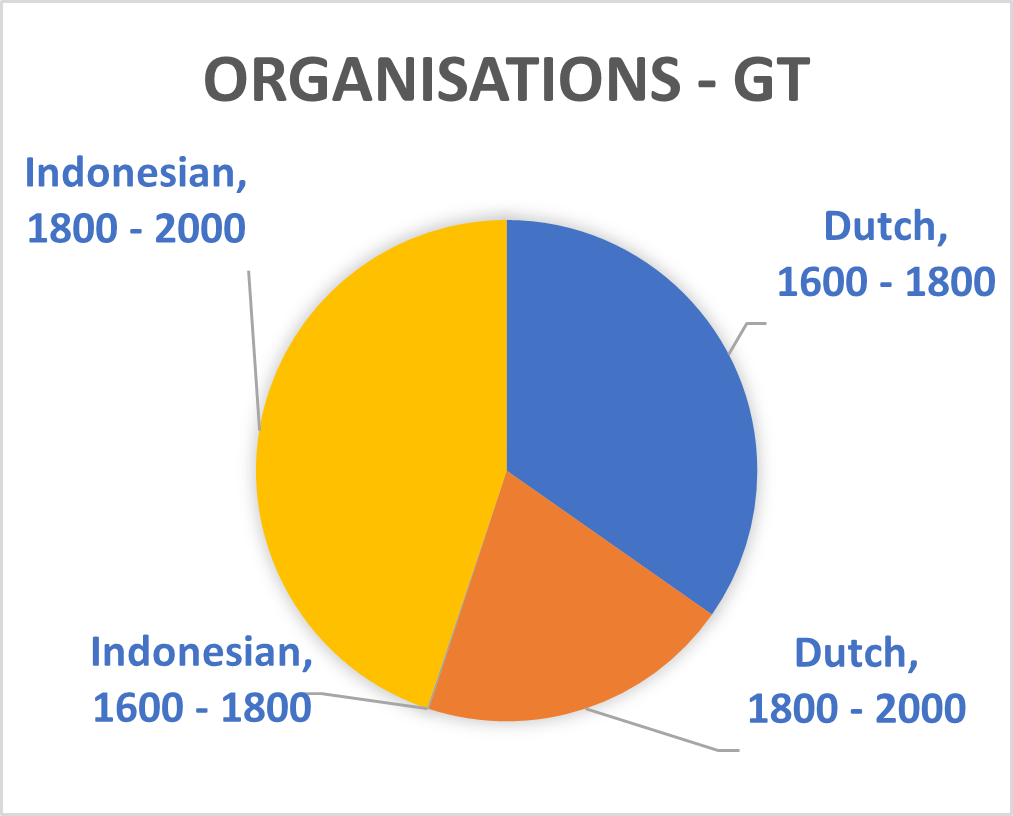
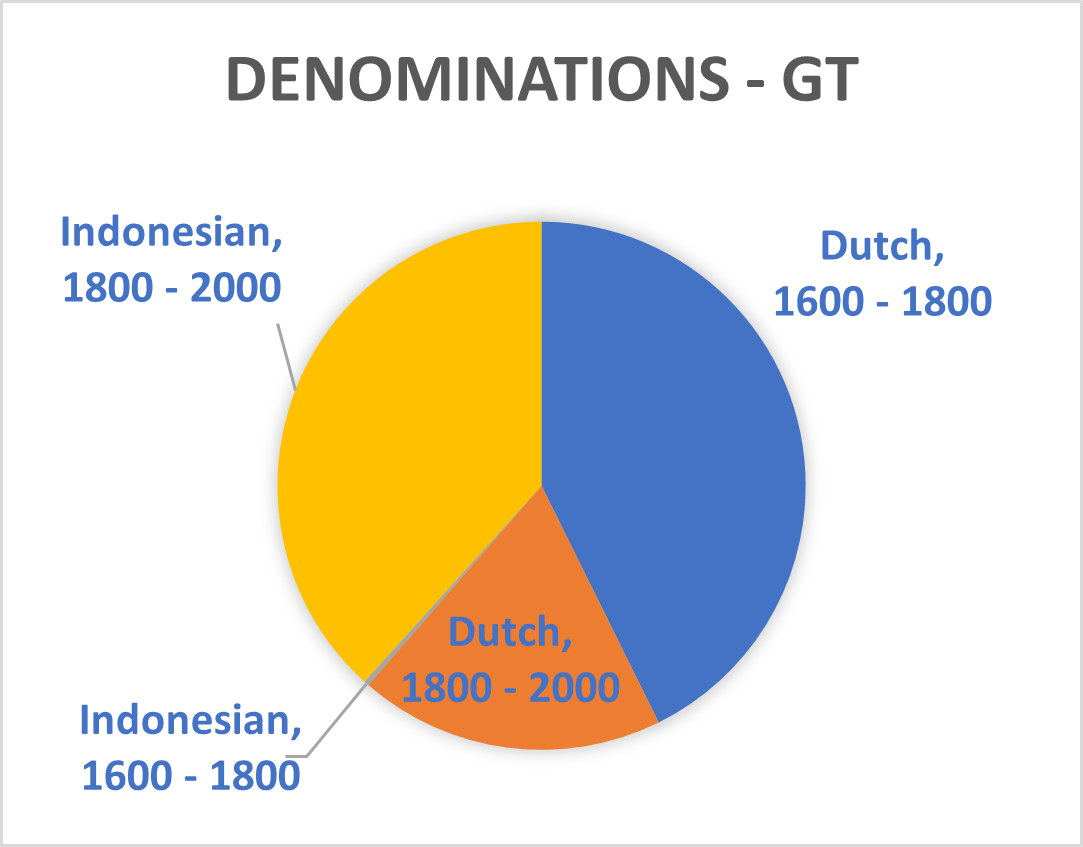
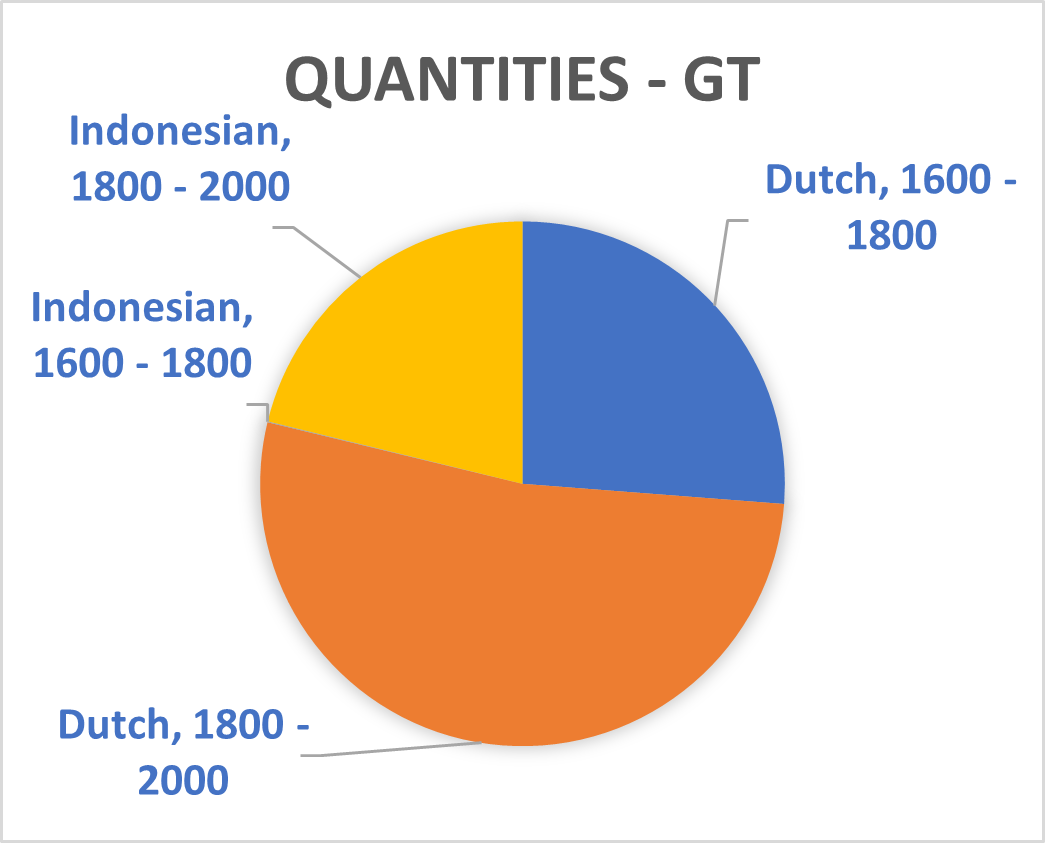
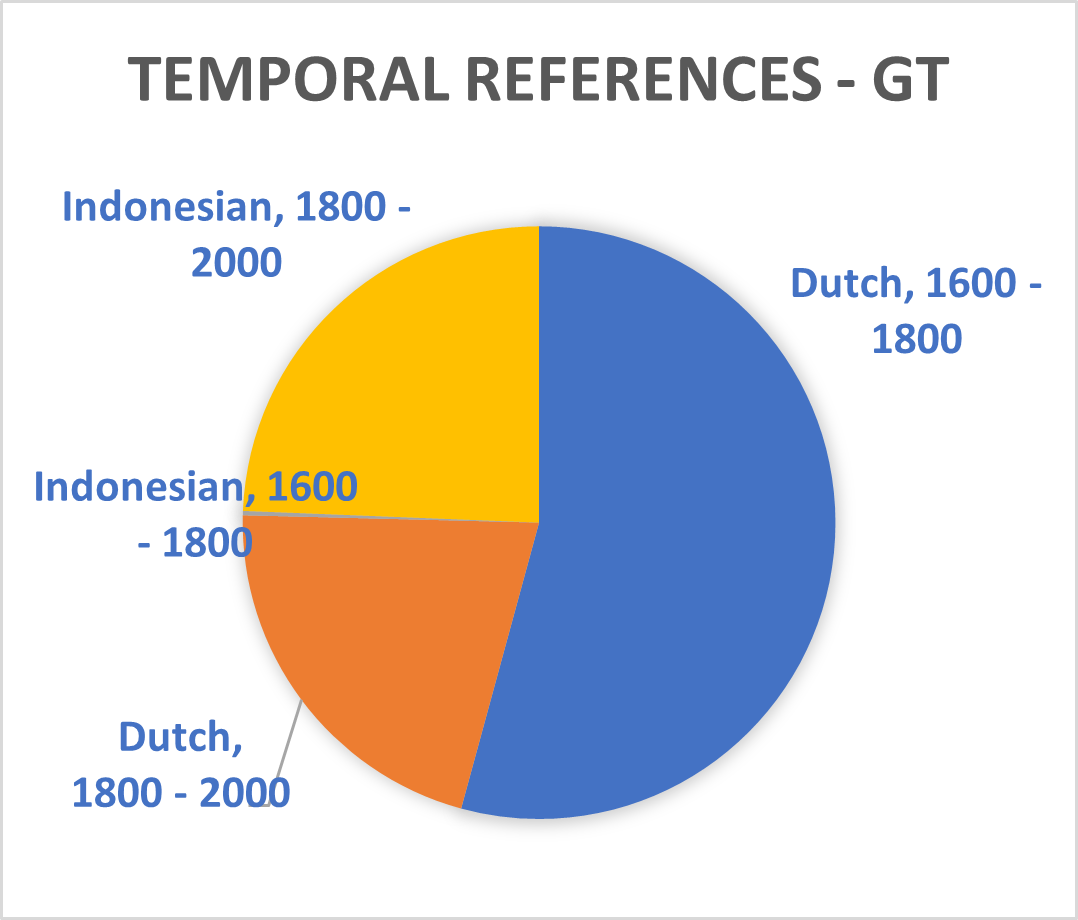
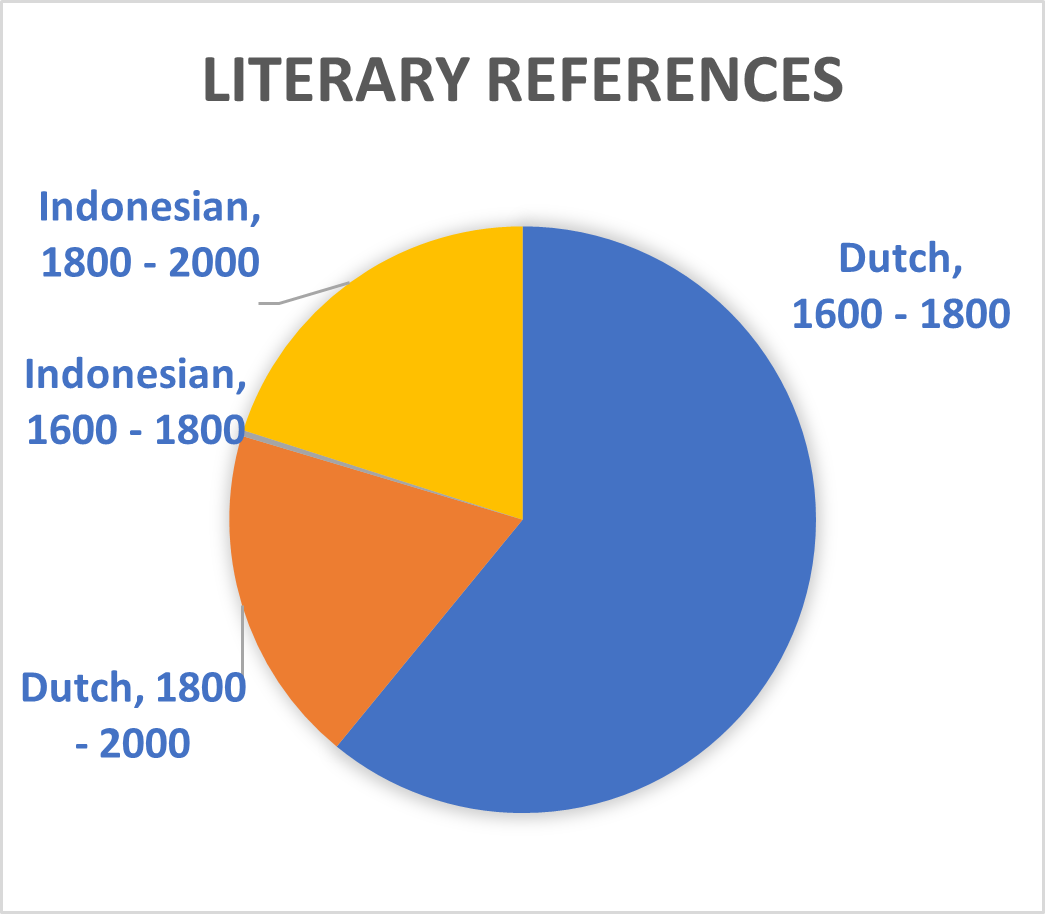
Splitting Phrases
The F1 scores for each of these corpora were measured separately. This evaluation was done in two ways: I. on all digital material from the corpora, II. on key phrases from these corpora. The latter test might appear arbitrary but proved crucial in indicating the real performance of the NER models. The recall and precision of NER models is strongly influenced by which phrases are put through the machine. Unlike modern Dutch texts, historical European and Asian languages do not always indicate sentences through full stops and spaces. Moreover, their often-ambiguous syntax proves difficult to unravel for Part-of-speech (POS) tagging. Indeed, the language change and genre difference inherent to analysing sources over a wide time span cannot be overcome through mere spelling normalization heuristics and requires profound engagement with the semantics of structure in large historical corpora.⁴
Before the breakthrough of Transformer models in 2017-2018, scholars sought to provide an alternative to spelling normalization by emphasizing the “importance of embedding the entire feature space, rather than just individual words”.⁵ Self-attention layers allow us to do the opposite: to capture the feature space through highlighting individual entities. NER thus becomes the indicator of syntax as the embedded context of each annotated entity is taken apart and re-assembled repetitively on a massive scale during the machine learning process. At the same time, the syntax—however difficult to define in early modern Dutch and Indonesian language corpora—can also be used to improve entity recognition. Splitting sentences and phrases turned out to be a crucial step in making our NER model work. I was able to automate this process by filtering key phrases through the text recognition and layout analysis provided by the Handwritten Text Recognition (HTR) methods that were used to obtain our machine-encoded text.
HTR and NER
As was explained in the previous blogpost, we opted to use HTR due to the flaws in the digital images and microfilms of historical newspapers from the Indies. This had the benefit of allowing us to experiment with annotations schemes without having to redo the tagging every time we added a new entity category, like ‘denominations’, ‘quantities’ or ‘references’. Importantly, HTR also enables linking the (automatically) annotated text files back to the original page layout. At the same time, the use of text lines in HTR is at odds with the use of phrases in NER. After all, HTR maps out the appearance of a text, whereas NER approaches it semantically. The choices made during the conversion between lines and phrases is vital to how the NER operates and deeply impacts evaluatory procedures like the calculation of F1 scores.
One decision to be made is whether to stick to line coordinates captured by HTR or to reconstruct sentences using basic characteristics of the machine-encoded texts that the HTR produces. Alternatively, it is also possible to conduct the NER simultaneously with HTR by applying Natural Language Processing (NLP) simultaneously with Image Classification (IC), or in other words by synchronising keyword spotting with word embedding. This method is still experimental and not yet ready for batch procedures. Moreover, it remains difficult to manipulate this above-mentioned method (NLP-IC) through Regular Expressions (Regex).⁶ Similar issues limit the use of HTR line coordinates and associated annotations as stored in PAGE-XML files. Parsing XML is straightforward, but altering their sequential structure is not.⁷ PAGE-XMLs preserve the original line segmentation and page divisions which inhibits reconstructions of semantically relevant sequences. After all, line coordinates are tied to tokens which often occur multiple time across a page, especially when they convey stop words. While such tokens can be distinguished through their order on a certain page, they become hard to tell apart when a page is split into phrasal sequences. Plain text was therefore preferred over NLP-IC or XML analysis.
The conversion to plain text does require additional steps when converting NER results back to the original transcription. Line and page breaks of the transcription need to be reinserted halfway phrases. This process can be automated by text-based—in contrast to XML-based—identifications for each line in the original text. The identification derives from the ‘column number’ (col) of the last character of a line, n-grams, and a combination of the first and last token of a line.⁸ The resulting ID provides sufficient reference points to extensively reconfigure the HTR transcriptions of Indies newspapers within and across pages and articles without disconnecting the listed output of NER from the layout of the input text. More so than with NLP-IC or XML analysis, lists of curated conjunction words, stop words and formulaic phrases created by librarians and archivists per corpus and language can be used to filter phrases from plain texts to increase the consistency among input sequences fed to the self-attention layer.⁹ Using this method resulted in a state of the art—at least for low-resource historical language— F1 score of around 91 percent for challenging input sequences like early modern Dutch (Dutch, 1600-1800, F1: 0.9108). As noted above, it did fail to deliver a promising score for independence-era Indonesian (Indonesian, 1800-2000, although mainly 1930-1960, F1: 0.5483), which—as mentioned—is largely due to the modernization of this language during the second half of the Twentieth Century, although it also indicates the challenges posed to Natural Language Processing by the strongly context-based Austronesian syntax in general.
This project gave a new twist to the decades-old debate on using linguistics or statistics as the basis of Natural Language Processing. Clearly, methodologies leaning on statistics have proven superior since at least the late 1980s. Nonetheless, the repetitive simulation-based nature of the transfer learning problem, and the granularities added to the input sequence by the self-attention layer, ensures that applying some form of semantic curation to split texts based on the intrinsic characteristics of historical corpora has much to offer to the field. Moreover, it can complement the attempt to customize the entity linking models as mentioned in the introduction of this blog. The semantics of structure proved crucial for implementing the annotation scheme presented in the previous blogpost and also in bridging the gap that would otherwise persists between different low-resource historical corpora from Asia and Europe. In other words, the NER and the phrasal selection which supports it are among the remedies to centuries of colonial exploitation which still leads to silences and biases within archives and libraries. Without relying on these ML-derived registers, the Dutch haystack of digitized holdings might suppress historical Asian material alike the skewed colonial era personalia lists and gazetteers from the nineteenth and twentieth century.

Related
Notes
1. The programme was conducted by Simon C. Kemper and Willem Jan Faber and managed by Lotte Wilms, Iris Geldermans and Michel de Gruijter.
2. Paul Azunre, Transfer Learning for Natural Language Processing (Manning, 2021), 15-16, 121-28.
3. Mihir Kale, Abhinav Rastogi, “Text-to-Text Pre-Training for Data-to-Text Tasks” (2020), arXiv:2005.10433.
4. M. Wevers and M. Koolen, “Digital begriffsgeschichte: Tracing semantic change using word embeddings”, Historical Methods: A Journal of Quantitative and Interdisciplinary History 53:4 (2020), 226-243; M. Koolen et. al., “Modelling Resolutions of the Dutch States General for Digital Historical Research” in A. Weber et. al., eds. COLCO 2020 Collect and Connect: Archives and Collections in a Digital Age 2020: Proceedings of the International Conference CEUR Workshop Proceedings Vol. 2810 (Sun SITE Central Europe, 2020) < http://ceur-ws.org/Vol-2810/ >; M. Koolen and R. Hoekstra, “The Semantics of Structure in Large Historical Corpora”, conference paper at Ottawa Digital Humanities 2020 <https://dh2020.adho.org/wp-content/uploads/2020/07/289....>
5. Yi Yang and Jacob Eisenstein, “Part-of-Speech Tagging for Historical English”. https://arxiv.org/abs/1603.03144
6. Cheikh Rouhoua, Marwa Dhiaf, Yousri Kessentini en Sinda Ben Salem, “Transformer-Based Approach for Joint Handwriting and Named Entity Recognition in Historical documents”, Pattern Recognition Letters. https://arxiv.org/abs/2112.04189; Mohamed Ali Souibgui, Sanket Biswas, Sana Khamekhem Jemni, Yousri Kessentini, Alicia Fornés, Josep Lladós, Umapada Pal, “DocEnTr: An End-to-End Document Image Enhancement Transformer” https://arxiv.org/abs/2201.10252
7. Susan Li, “Parsing XML, Named Entity Recognition in One-Shot: Conditional Random Fields, Sequence Prediction, Sequence Labelling” Towards Data Science. https://towardsdatascience.com/parsing-xml-named-entity-recognition-in-…
8. line.replace(‘(^(\w\.|\w\,|\w\"|\w\'|\"\w|\w){1,99})(.*)’, ((\w|\w¬|\w-|\w\.|\w\,|\w\"|\w\'|\"\w){1,99}$)’, ‘\1; \4’).
9. < https://github.com/marijnkoolen/fuzzy-search >