Named Entities like persons and places are technically the same across languages, still their contexts and connotations do differ. There is much potential in fine-tuning data mining methods by teaching machines to operate across languages and recognize subtle differences in connotations caused by differences in syntax, script and vocabulary. Recent advances in multilingual or polyglot Named Entity Recognition (NER) have focused on combining vast data sources from modern day online platforms like social media and Wikipedia.
Using ten to ten thousand of millions of words in a hundred languages—including Javanese, Sundanese and Indonesian—from all over the world, the XLM-R Transformer model significantly improved the performance of English, Dutch, German and Spanish models in 2019-2020 and recently has also proven capable of raising the bar for 36 non-western languages.¹ Indonesian scores relatively high in these tests. With 22,704,000,000 tokens in its repository, it among one of the best represented modern languages in the online world; which is not at all surprising considering the 140 million Facebook users who are native speakers of this language.²
The large quantity of data available for modern Indonesian was analyzed by casting aside the golden standard of hand-labelling or manual tagging of persons, places and other entities to instead leverage the Wikipedia page markup, especially hyperlinks between lemmas.³ Such techniques are hardly applicable to the much smaller set of historical sources in Indonesian languages, nor for the more comprehensive but equally fuzzy Dutch material from the seventeenth until the twentieth-first century. I will address some ways in which the historical corpora of these languages can be exploited with similar benefits as those obtained through bridging their modern varieties.
Linking languages through entities has proven to work, but how about historical connections between and within them? How does modern Dutch compare to seventeenth century Dutch, or Indonesian tweets to palm scripts? During the first half of the year 2021, I and Willem Jan Faber explored the connections between entities in Dutch and Indonesian late colonial and early independence newspapers as well as related documents like letters and biographies of journalists. To explore long-term patterns, we combined this data with a sizeable set of annotated East India Company (VOC) records—mainly reports and letters which reported news to the superiors in Batavia and the Dutch Republic—from the seventeenth and eighteenth century. We posted three main research questions, of which I will discuss the first in this current blog.
- What do the disbalances in retrieving European and Asian entities tell us about colonial biases lingering in these newspapers and/or the methods used to analyze them? How does the preference of honorifics over surnames in Indonesian—or indeed all Austronesian—languages influence data analysis and retrieval?
- Can historical Named Entity Recognition (NER) be improved by applying it to natural languages from two different language families which are connected through colonial ties?
- Given the mixed language use in colonial newspapers, it possible to measure the extent to which texts are based on the Dutch language or the Indonesian ones by looking at the contexts in which entities occur?
Linking these historical languages—Dutch, Javanese, Sundanese and Malay [modern-day Malaysian and Indonesian]—to each other is a promising way in not only increasing the performance of historical NER models, but also estimating the extent to which Dutch texts from a colonial context were mixed with other languages. But these facets (question 2 and 3) will be discussed further in the next blog, for now I will focus on how polyglot models help in detecting Asian entities while also cautioning how the mixed quality of digital source material and generalisations within annotation schemes can bake in Eurocentric biases in the NER (question 1).
Plate 1. This blog will elaborate on how the images of newspapers were automatically transcribed and manually labelled with tags.
Asian Entities
The digitisation efforts of the Dutch collections predate the Indonesian ones and were directed by much stricter and consistent guidelines than those applied in Jakarta. Considering that the Indonesian scans are not always neat and sharp, our first challenge was to improve the text recognition of the Indonesian newspapers. Many of the available digital copies were made under poor lighting conditions and were severely compressed by Adobe Flash plugins leading to Character Error Rates (CER) reaching far above fifty percent. In other words, the digital texts no longer resembled the printed one and were not suited for Natural Language Processing (NLP). The related handwritten archival records had not been transcribed at all. Nonetheless, we were able to incorporate the Indonesian sources by developing a custom Handwritten Text Recognition (HTR) model. This allowed us to create the first ever digital resource of historical Malay/Sundanese/Javanese periodicals encompassing nearly 14.000 Indonesian newspaper editions from 1900 until 1945, with a CER of only 0,86 percent in our validation set.
While this is a lot to read through, it is but a small sample in comparison to the digital records on Delpher, not to mention Twitter. For the period from the 1930 until 1962 alone, the digitised Dutch-language colonial periodicals count 52.773 editions; nearly four times as many as their Indonesian equivalents for the period mentioned above. Ironically, the first decade of independence (1949-1959) is almost solely covered by digitised Dutch-language newspapers. To improve the balance, we traced and digitised additional Indonesian material in Indonesia and the Netherlands from 1930 until 1960, with some bridging material from more recent decades to tie in with the already existing social media-based models.
We also semi-automatically compiled lists of Indonesian entities—journalists, politicians, feminists, writers and Islamic scholars—from Indonesian secondary literature, some of which were only available on Java or even confined to regional publishing markets like that of Banda Aceh, Makassar or Ternate. Automatic Data Extraction of newspaper registers gave us an impression of what was still missing. The Indonesian Journalist Association had, for instance, compiled a two-volume encyclopedia over a period of ten years which proved a useful database of Indonesian periodicals and journalists that complemented the register of Dutch-language material of Anneke Scholte and Gerard Termorshuizen.⁴ Based on the seminal work of these researchers, we estimate that up to sixty percent of the Dutch-language periodicals is preserved in digital form and only about twenty percent of the Indonesian-languages equivalents. Sadly, large parts of the latter group are left to decay in a tropical climate and are thus likely to disappear forever if not captured soon.
The quantity of Dutch material is not necessarily a blessing for data analysis. Delpher’s transcriptions are prone to a higher CER than our HTR set, especially for microfilms. Worse is the segmentation which often cuts through articles, as was already noticed during the Digital Film Listings (DIGIFIL) programme a year ago. Reprocessing samples from the Delpher websites in HTR proved a good way to raise the overall quality, but it was unfeasible to handle all colonial newspapers in this manner within the span of our programme. Nonetheless, the general quality of the Indonesian and Dutch transcription proved good enough for the downstream task of Named Entity Recognition and Linking.⁵
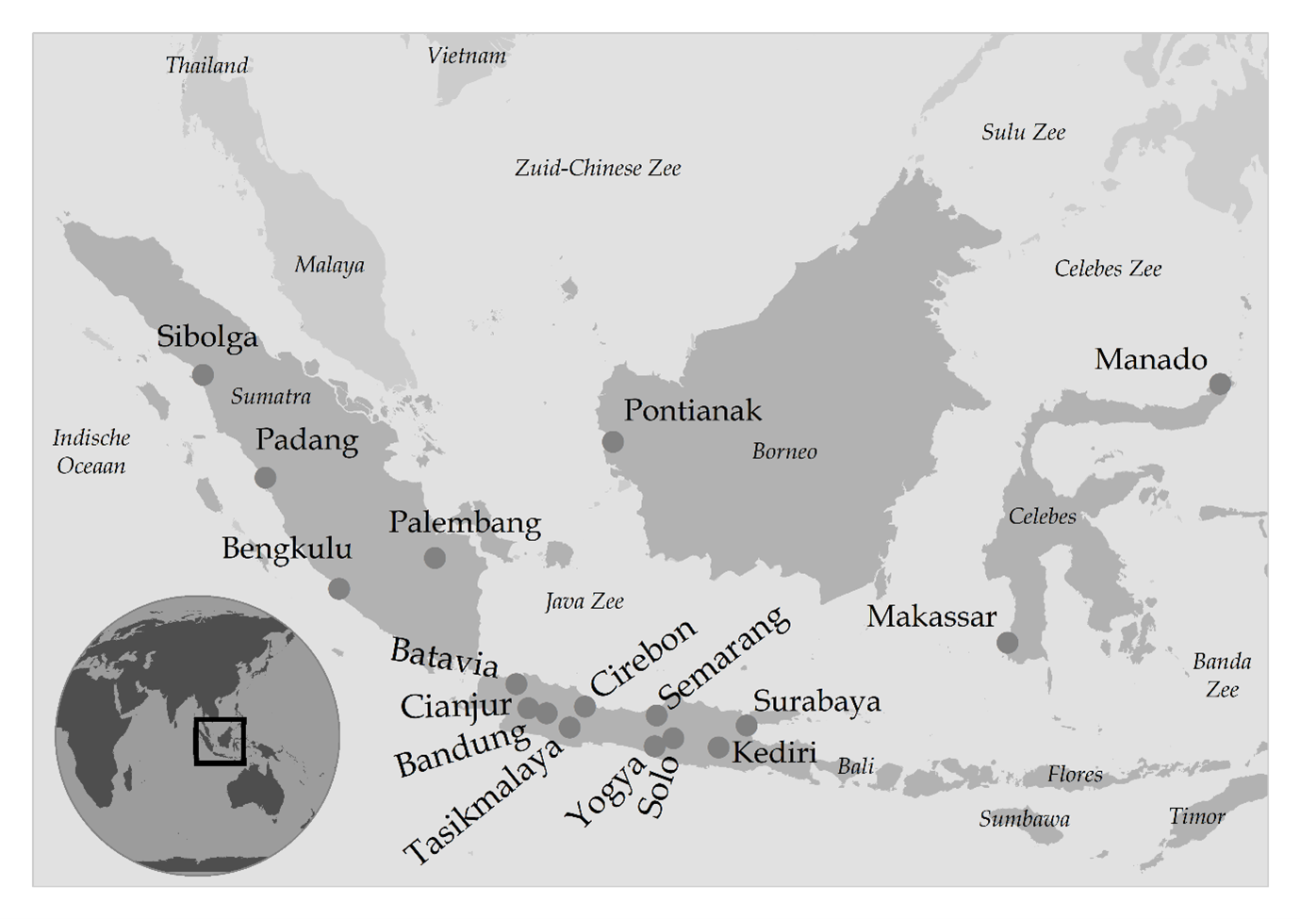
Map 1. Centers of the Malay-language press during the late colonial period.
Tagging entities across languages, scripts and time
We developed a pretrained Named Entity Recognition (NER) transformer model by tagging Malay, Dutch, Sundanese and Javanese texts across Latin and Javanese scripts. Our two Indonesian research assistants, Christopher Reinhart and Shinta Farida, hand-labelled texts and entities which were relevant to an educated Indonesian audience. The particularities of the Indonesian languages required adaptations of the universally accepted tagging guidelines set out by the Sixth Conference on Natural Language Learning (CoNLL-2002). The ‘miscellaneous’ category—which covers ethnic denominations, references to literary works and a host of other concepts—scored particularly low in our NER model with an F-score at about 80 percent rather than the around 90 percent scores for persons, places and organizations. This related to the fact that Indonesian languages do not normally contain inflected adjectives. For instance, in Malay there is no morphological distinction between ‘an Indonesian’ (orang Indonesia) and Indonesia (negeri Indonesia). Without tagging the main noun (orang or negeri), the modifier (in both cases Indonesia) cannot be distinguished in the extracted list of entities. But the problem goes deeper as Indonesian syntax also allows vaguer references that are depended on the circumstances of speech. Like Arabic, it encourages poetic expressions that would be considered inaccurate in Germanic languages. Broadening the annotation scheme as to include noun phrases overcame this issue.
The ambiguity of the ‘miscellaneous’ category is also apparent for Dutch texts. CoNLL-2002 neglects the historical differences within European languages and the typography of the source material used. By combining literary references with (ethnic) denominations two very different types of contexts are mixed together. Literary references tend to occur is short phrases, registers and text margins leading to different sentence structures than (ethnic) denominations which predominate in running texts, especially in essay-like articles or reports. We opted to apply structural tags indicating headers, headings, footers, footnotes, marginalia, tables and captions to keep track of the entities’ occurrences within different page sections. The results encouraged us to split the references from the denominations and also distinguish quantified denominations (‘three Javanese peasants’) from narrative ones (‘the Javanese’). While the tagged tokens of the latter two categories will appear similar, their contexts show significant differences. These statistical patterns correspond to the different purposes of quantified and narrative denominations, namely one of counting groups in a biased manner vis-a-vis designating them for arguments’ sake. Finally, dates and time references also deserve to be labelled separately. They statically correlate with different phrases and epistemologically contain temporal data which needs be kept apart for historical analysis. We thus ended up splitting the ‘miscellaneous’ category in four tags: ‘denomination’, ‘ quantity’, ‘date’ and ‘reference’.⁶ All these can be applied across-domains and thus within and between different archives and collections.
The definition of ‘person’ needed refining too. The CoNLL-2002 guideline overemphasises ‘named’ entities; as in entities whose names are (partially) spelled out. Referring to person names is more common in European languages than Austronesian ones, in which honorifics and kinship terminology are often used to address others, even when they are strangers. In line with more recent tagging standards ranging from the general Transkribus tagging guidelines to the domain-specific labelling methods for the East India Company Testaments and medieval Spanish manuscripts, we included mentions of ‘his sister’, ‘father’ and the like to avoid Eurocentric or modernistic recognition methods.⁷ The subsequent process of Named Entity Linking is weakened by this choice, but the context of these references and associated named entities can still be used to successfully link these ‘latent entities’ to the knowledge base, in our case Wikidata.
Based on these observations, we formulated our own tagging manual based with clear instructions in English and Indonesian leading to an inter-annotator agreement of nearly 95 percent. The resulting dataset became the foundation of our Gado2 Named Entity Processing application to which I will dedicate a separate blog post later on. The refinements in text recognition and labelling led to a comprehensive set of Dutch and Indonesian entities which was analyzed in an embedding projector to detect the biases in which they were framed by the newspapers. The analysis of the projector results greatly benefits from the improvements made in the transcription and recognition techniques as it grants more confidence on whether the disbalance between retrieved European and Asian entities was caused by the press rather than biases in our methodology.

Related
Notes
1. A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, and V. Stoyanov, “Unsupervised Cross-lingual Representation Learning at Scale”. arXiv, 1911.02116 (2020 [2019]). <https://arxiv.org/abs/1911.02116>; Julian Plue, “jplu/tf-xlm-r-ner-40-lang” <https://huggingface.co/jplu/tf-xlm-r-ner-40-lang/tree/main>. For a more elaborate overview, see Borach Jansema, “Unlocking Inclusivity Possibilities with Polyglot-NER Fundamentals of massive multilingual Named Entity Recognition”, towards data science (28 June 2021) <https://towardsdatascience.com/unlocking-inclusivity-possibilities-with-polyglot-ner-9990baf03561>.
2. Note that Julian Plue curtailed the Indonesian dataset to 10,000 documents to keep it in line with other lower-resource languages. “Leading countries based on Facebook audience size as of April 2021 (in millions)” Statista <https://www.statista.com/statistics/268136..>
3. X. Pan, B. Zhang, J. May, J. Nothman, K. Knight and H. Ji, “Cross-lingual Name Tagging and Linking for 282 Languages”. ACL Anthology, 1946–1958 (2017)
4. Widodo Asmowiyoto et al., Ensiklopedi Pers Indonesia, two volumes (Jakarta: Persatuan Wartawan Indonesia, 2013 [2008]); Gerard Termorshuizen, Realisten en Reactionairen: Een geschiedenis van de Indisch-Nederlandse pers, 1905-1942 (Leiden: KITLV, 2011), 893-1083.
5. Note that it remains challenging to conduct a comprehensive assessment of the impact of transcription quality on pretrained transformer models, see Giovanni Colavizza, “Is your OCR good enough? Probably so. Results from an assessment of the impact of OCR quality on downstream tasks”. KB Lab (16 March 2021). https://lab.kb.nl/about-us/blog/your-ocr-good-enough-probably-so-result….
6. ‘Date’ was already a standard reference within the Handwritten Text Recognition Transkribus application and thus preferred over the more accurate ‘temporal’.
7. Due to their different research purposes and source material, clinical and biological annotation methods were not considered. “How To Enrich Transcribed Documents with Mark-up”, https://readcoop.eu/transkribus/howto/how-to-enrich-transcribed-documen…; Elena Álvarez-Mellado, María Luisa Díez-Platas, Pablo Ruiz-Fabo, Helena Bermúdez, Salvador Ros & Elena González-Blanco, “TEI-friendly annotation scheme for medieval named entities: a case on a Spanish medieval corpus”, Language Resources and Evaluation 55 (2021), 525–549; Milo van der Pol “Unsilencing the VOC Testaments”. https://kia.pleio.nl/groups/view/6ccab050-a92c-4ee2-81bf-7e6bcd30e564/h…;