Summary
The goal of the project is to conduct a comprehensive assessment of the impact of OCR quality in Dutch newspaper, journal and book collections (see my previous blog post). This is done via extrinsic evaluation: assessing results from a set of representative downstream tasks, such as text classification or clustering. I present here our results for topic modelling, document classification and post-OCR correction.
All results are very encouraging: we find that both for topic modelling (using LDA) and document classification (using a variety of methods, including deep neural networks), working on an OCRed version of a corpus does not in general compromise results. On the contrary, it may be even better sometimes. Furthermore, using data from the ICDAR 2019 post-OCR correction challenge, we are able to significantly improve the quality of the OCR, up to and over 16% improvement. While more work is needed, including assessing with different datasets and methods, our results suggest that the quality of existing OCR might be sufficient to successfully perform a variety of tasks.
Mirjam Cuper (KB) and Konstantin Todorov (UvA) have also contributed to this work as follows: Mirjam has contributed data, including the evaluation of OCR quality, and provided invaluable support throughout the project; Konstantin is fully responsible for the post-OCR correction task.
Methods and data
We consider the following downstream tasks which are relevant to the digital humanities and the library and information communities. In particular, I will focus on:
- Document classification: the goal is to assign one or more labels to each document. The model learns from a manually annotated dataset; this is therefore a supervised learning task.
- Document clustering: the goal is to group documents into clusters, by similarity. This task also topic modelling, a widely used technique in the digital humanities. These are therefore unsupervised learning tasks because they are performed in the absence of annotated data.
- Post-OCR correction: the goal is to post hoc improve the quality of the OCR. This can be done using either supervised, unsupervised and rule-based techniques. This task is somewhat different from the previous three, as its purpose is to improve on the quality of OCRed texts, independently of their subsequent use.
In order to assess the impact of OCR on these downstream tasks, we use extrinsic evaluation: for each task, we compare the results of the same models on two different versions of the same corpora: on the one hand, the OCRed text, and on the other hand, a ’ground truth’ version which is known to be correct, or close to.
Results for this post are based on the following datasets:
- Historical newspapers from the KB OCR research project.
- A selection of books from DBNL.
- ICDAR 2019 post-OCR correction challenge.
Topic modelling
Topic modelling is a widely-used technique in digital humanities, as it allows to cluster documents and interpret such clusters via word probability distributions (the ‘topics’). We consider a popular method, called Latent Dirichlet Allocation (or LDA), and use the IMPACT dataset provided by the KB (dataset 1 above).
We apply several pre-processing steps including: removing stopwords, lemmatizing and lowercasing, removing short tokens and adding frequent bigrams. We then train an LDA model for 15 topics using the ground truth and OCRed versions of the IMPACT dataset independently. Our results suggest a strong similarity between the two topic models. Firstly, intrinsic evaluation using topic coherence yields similar results. Secondly, using topic matching and the Kullback-Leibler divergence (KL, a measure of the distance between two probability distributions, such as topics), we are able to effectively find a pairing of topics between the two models (ground truth and OCRed), suggesting that the two do not differ substantially. Lastly, the topic model trained on OCRed data is as stable in its document topic distributions like the one trained on ground truth, if not even more so.
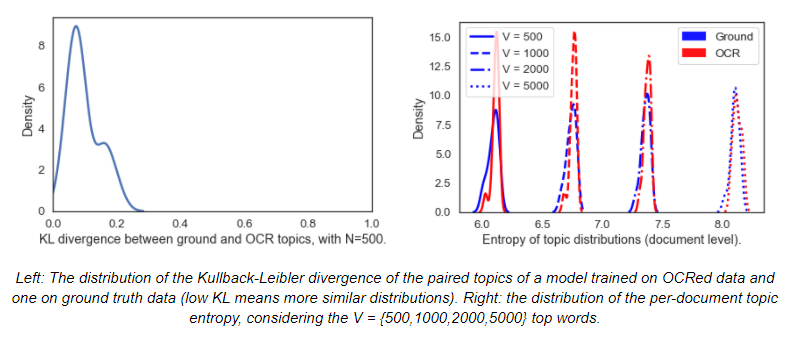
Document classification
We use the second dataset of Dutch literature (above) and consider the task of classifying the genre of a book, as given by the DBNL API. We train a variety of classifiers, including: Naive Bayes, Support Vector Machines, Random Forests, Multilayer Perceptron, all with simple count and TF-IDF features. We also test a deeper neural network architecture using dedicated embedding and an LSTM layer.
Our results below report the accuracy of each model, as evaluated on a held-out 20% of the dataset, while the remaining 80% has been used for training. We refer the reader to our repository for the details of preprocessing, model tuning and fitting. As it can be seen below, the OCRed version of the dataset does not compromise results. On the contrary, and surprisingly, it often yields slightly better results than using the ground truth. The LSTM (recurrent) neural network architecture is the best performing model, with an accuracy of over 93% on the OCRed dataset.
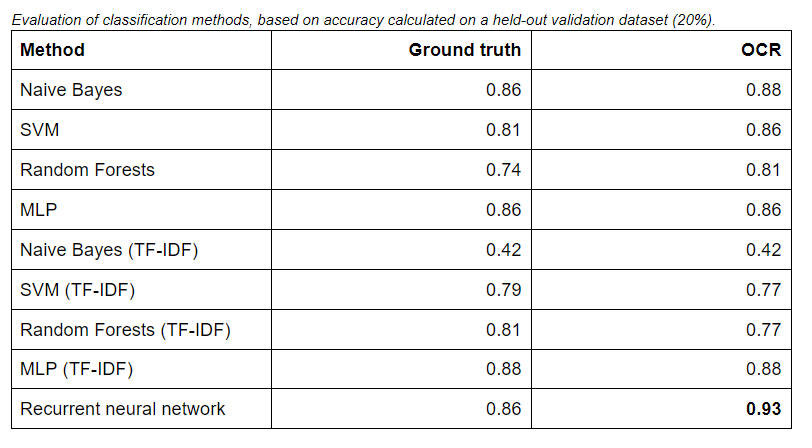
Post-OCR correction
Lastly, we extend our previous work on post-OCR correction to assess the performance of a state-of-the-art neural network architecture on Dutch. We use readily-available data from the ICDAR 2019 post-OCR correction challenge and a sequence-to-sequence architecture reliant on pre-trained embeddings such as BERT, and which has shown good results for a variety of languages, including French and German. We refer the reader to the original paper for more details. For the purposes of adapting to Dutch, we use BERTje.
The results of post-OCR correction on Dutch are again promising, also considering the relatively bad starting point in terms of OCR quality. We are able to gain a 10-16% improvement over the uncorrected OCR version, as measured by the normalized Jaccard similarity and the Levenshtein distance, respectively. While these results are lower than what we can get for German, they remain higher than French and English, using the same approach on data from the ICDAR 2019 challenge. More details can be found in the original paper’s repository.
Closing
In summary, we have shown that OCR quality need not be a blocker for the profitable use of a variety of machine learning techniques. While our results are limited to Dutch and the specific datasets we relied on, they further confirm previous work in suggesting that OCRed corpora can be used even if they contain noisy text. Future work might focus on extending these assessments, both in terms of datasets and tasks/methods, but also in more precisely assessing the boundary where a too low OCR quality effectively prevents the use of a certain method.
Code and data
More details on the datasets we used can be found here: https://github.com/Giovanni1085/KB_OCR_impact/wiki/Datasets.
The same repository also contains all the code necessary to replicate our results: https://github.com/Giovanni1085/KB_OCR_impact.
For post-OCR correction, see instead here: https://github.com/ktodorov/eval-historical-texts/blob/master/docs/arguments/postocr_arguments_service.md.

To know more
Hill, Mark J, and Simon Hengchen. 2019. “Quantifying the Impact of Messy Data on Historical Text Analysis.” Digital Scholarship in the Humanities 34 (4): 825–43. https://doi.org/10.1093/llc/fqz024.
Rigaud, Christophe, Antoine Doucet, Mickaël Coustaty, Jean-Philippe Moreux. 2019. ICDAR 2019 Competition on Post-OCR Text Correction. 15th International Conference on Document Analysis and Recognition, Sep. 2019, Sydney, Australia. pp.1588-1593. Ffhal-02304334f. https://hal.archives-ouvertes.fr/hal-02304334/document.
Smith, David A, and Ryan Cordell. 2018. “A Research Agenda for Historical and Multilingual Optical Character Recognition” http://hdl.handle.net/2047/D20298542.
Strien, Daniel van, Kaspar Beelen, Mariona Ardanuy, Kasra Hosseini, Barbara McGillivray, and Giovanni Colavizza. 2020. “Assessing the Impact of OCR Quality on Downstream NLP Tasks.” In Proceedings of the 12th International Conference on Agents and Artificial Intelligence, 484–96. Valletta, Malta: SCITEPRESS – Science and Technology Publications. https://doi.org/10.5220/0009169004840496.
Traub, Myriam C., Thaer Samar, Jacco van Ossenbruggen, and Lynda Hardman. 2018. “Impact of Crowdsourcing OCR Improvements on Retrievability Bias.” In Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries – JCDL ’18, 29–36. Fort Worth, Texas, USA: ACM Press. https://doi.org/10.1145/3197026.3197046.
Todorov, Konstantin, and Giovanni Colavizza. 2020. “Transfer learning for historical corpora: An assessment on post-OCR correction and Named Entity Recognition.” Computational Humanities Research. http://ceur-ws.org/Vol-2723/long32.pdf.