SUMMARY
Is an average OCR quality of 70% enough for my study? What OCR quality should we ask from external suppliers? Should we re-do the OCR of our collections to bring it from 80% to 85%? Libraries and researchers alike face the same dilemma in our times of textual abundance: when is OCR quality good enough? User access, scientific results and the investment of limited resources increasingly depend on answering this question.
During this project, I will conduct a comprehensive assessment of the impact of OCR quality in Dutch newspaper, journal and book collections, comparing it with published results for English and French. This will be done via extrinsic evaluation: assessing results from a set of representative downstream tasks, such as text classification or clustering. The ultimate goal of the project is to contribute guidelines detailing when OCR quality is to be considered good enough, in order to inform the development and use of textual collections.
Current research
My work is multidisciplinary and focuses on two main areas: science studies and computational arts and humanities research. The former line of work has me delving into topics such as information extraction from humanities publications, citation and text analysis of scientific publications, studying the sources of Wikipedia and their usage. In the latter line of work, where the collaboration with the National Library also rests, I primarily work on information extraction and processing from heritage collections, as well as data-driven research in the arts and humanities. In my case, since I have a background in history, I tend to focus on topics related to this discipline. A recent and sadly timely example is a study of the 1630-31 plague outbreak in Venice (https://www.medrxiv.org/content/10.1101/2020.03.11.20034116v1), conducted in collaboration with epidemiologists.
AI for Cultural Heritage
The application of machine learning, or artificial intelligence (AI), to the broad domain of cultural heritage, is nowadays called AI for Cultural Heritage. Its scope is wide, as it in principle encompasses all AI techniques or reflections on their use, to the even wider area of cultural heritage. Nevertheless, with the rapid growth of digitised and born-digital collections of cultural and historical importance, the use of machine learning is rapidly expanding. Machine learning is traditionally used in this setting to extract, process and enrich information. For example, an OCR pipeline includes the steps of digitisation, pre-processing (e.g., layout analysis), OCR, post-processing and use (e.g., for search). Furthermore, scholars increasingly adopt the data science toolkit to analyse data at scale. This shift, also common to several other disciplines (e.g., computational biology or computational social sciences), is currently referred to as computational arts and humanities research. More information can also be found on the Creative Amsterdam website (https://www.create.humanities.uva.nl/ai-for-cultural-heritage) and Computational Humanities Research community forum (https://discourse.computational-humanities-research.org).
Optical Character Recognition
An important or perhaps the most important step in the digitisation of textual collections is Optical or Handwritten Character Recognition (O/HCR), which is the automatic conversion of images of typed or handwritten text into machine-readable text. It is worth noting that O/HTR was and still is primarily developed for modern-day industry document processing purposes. Examples include the automatic recognition of mailing addresses or the processing of scanned documents. Since library holdings largely contain printed materials, our focus here will be on OCR. Given the scale of digitisation in recent decades, and the use of these collections primarily via full-text search, the importance of OCR cannot be underestimated.

OCR, like any automated process, is not devoid of errors. In practice, several challenges concur into making OCR processes error-prone, and some of these challenges are particularly problematic for historical collections. We name a few here, see Smith and Cordell (2018) for a more comprehensive discussion. A first challenge is the variety of the materials in terms of quality of support, conservation, types and other factors which influence OCR. A known example is given by the long ‘s’ type, which was widely used up to the XIX century and is very similar to a modern ‘f’ (see figure, from https://usesofscale.com/gritty-details/basic-ocr-correction). A second challenge is multilinguism and linguistic variation over time. Not all languages are equal with respect to available linguistic resources and the wealth of data which can be used to train OCR algorithms. Furthermore, languages change over time, therefore an OCR algorithm trained on modern-day English might not work as effectively on XVII-century texts. Another challenge is legacy pipelines. Digitisation practices have changed and improved over time, and so have OCR algorithms too, with a direct impact on OCR quality.
A Known Unknown
In data science and machine learning, there is a saying: “garbage in, garbage out”. This stands as a warning to always keep in mind that, among the many challenges and pitfalls of using data for creating services and doing analysis, data quality is of critical importance. If the input data is of bad quality (garbage in), the outputs will likely also be highly distorted or biased (garbage out). OCR quality is, in this respect, a so-called “known unknown” for digital humanists and information professionals: we know it is a key factor to consider, but we still know very little about how it impacts what we do with OCRed data (Smith and Cordell 2018). Recent work has started to explore the impact of OCR quality on so-called ‘downstream tasks’: the activities we perform using OCRed data (Hill and Hengchen 2019; van Strien et al. 2020; Traub et al. 2018).
My residency at the National Library contributes to this recent line of work, by focusing on collections in Dutch and by comparing over a variety of downstream tasks, in order to come up with a set of guidelines on the impact of OCR quality.
Methods and Data
For this project, I plan to focus on a selection of downstream tasks which are relevant to the digital humanities and the library and information communities. In particular, I will focus on:
- Document classification: the goal is to assign one or more labels to each document. The model learns from an annually annotated dataset; this is therefore a supervised learning task.
- Document clustering: the goal is to group documents into clusters, by similarity. This task also includes topic modelling, a widely used technique in the digital humanities. These are therefore unsupervised learning tasks, because they are performed in the absence of annotated data.
- Language modelling: the goal is to learn a meaningful representation of the way language used in a corpus. Commonly, this task is performed using unsupervised or self-supervised techniques.
- Post-OCR correction: the goal is to ex post improve the quality of the OCR. This can be done using either supervised, unsupervised and rule-based techniques. This task is somewhat different from the previous three, as its purpose is to improve on the quality of OCRed texts, independently of their subsequent use.
In order to assess the impact of OCR on these downstream tasks, I will take an approach called extrinsic evaluation: for each task, I will compare the results of the same models on two different versions of the same corpora: on the one hand, the OCRed text, and on the other hand, a ’ground truth’ version which is known to be correct, or close to. Typically, the ground truth is prepared by manual annotators and assessed in its quality beforehand. Preparing the ground truth is very costly and laborious, hence typically only small datasets are available which come with these two versions (OCR and ground truth).
Luckily, the National Library has prepared, or made accessible, a set of datasets meeting these criteria. In particular, I will be working on the following datasets, all in Dutch:
- XVII-century newspapers from the Meertens Instituut (https://www.meertens.knaw.nl/cms/nl/nieuws-agenda/nieuws-overzicht/278-2020/146210-crowdsourcing-maakt-zeventiende-eeuwse-kranten-op-delpher-beter-doorzoekbaar).
- A selection of books from DBNL (https://lab.kb.nl/dataset/dbnl-ocr-data-set).
- Two book datasets from the IMPACT project (https://lab.kb.nl/dataset/ground-truth-impact-project).
- Radio bulletins (https://lab.kb.nl/dataset/ground-truth-impact-project).
- Historical newspapers OCR GT-set (https://lab.kb.nl/dataset/historical-newspapers-ocr-ground-truth).
A key element of the project is the actual quality of the OCR, since it varies significantly across these datasets. The quality of the OCR can be assessed in a variety of ways, including using text distance metrics (e.g., Levenshtein), the confidence of the OCR model itself, or via external means (e.g., dictionary lookup). It is by comparing results on corpora of varying OCR quality, that we can come to some conclusions about the impact of OCR on these tasks. For this crucial part of the project, I am supported by Mirjam Cuper, from the KB Digital Humanities team. The figure below provides an example of the variety we have in the datasets in terms of OCR quality.
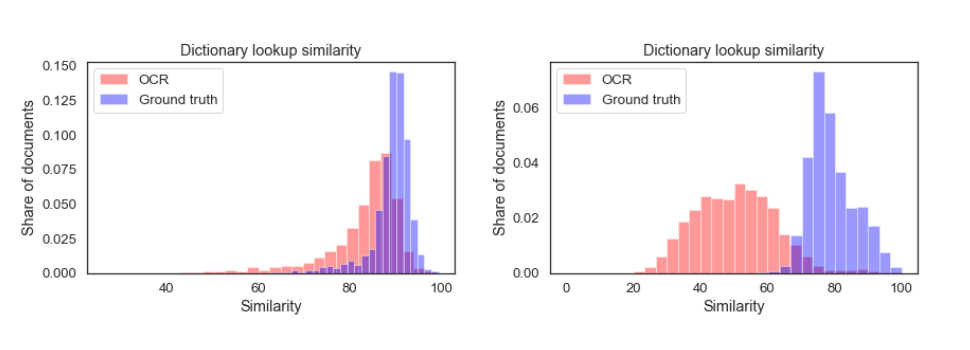
OCR quality using dictionary lookup for the Historical Newspaper OCR GT corpus (left) and the Meertens newspaper corpus (right). Clearly, XVII-century materials are more challenging to OCR, hence the quality of the OCRed and ground truth versions differ more substantially.
Closing paragraph
Increasingly, library services and digital humanities scholarship relies on complex document processing pipelines, which often include OCR. It is my hope that this project can serve to inform researchers and practitioners on what can be done with OCRed corpora, and where it might be most useful to put resources for digitization in the future. I am grateful to the National Library for this opportunity, and look forward to working together.

TO KNOW MORE
Hill, Mark J, and Simon Hengchen. 2019. “Quantifying the Impact of Messy Data on Historical Text Analysis.” Digital Scholarship in the Humanities 34 (4): 825–43.
https://doi.org/10.1093/llc/fqz024.
Smith, David A, and Ryan Cordell. 2018. “A Research Agenda for Historical and Multilingual Optical Character Recognition”
http://hdl.handle.net/2047/D20298542.
Strien, Daniel van, Kaspar Beelen, Mariona Ardanuy, Kasra Hosseini, Barbara McGillivray, and Giovanni Colavizza. 2020. “Assessing the Impact of OCR Quality on Downstream NLP Tasks.” In Proceedings of the 12th International Conference on Agents and Artificial Intelligence, 484–96. Valletta, Malta: SCITEPRESS – Science and Technology Publications.
https://doi.org/10.5220/0009169004840496.
Traub, Myriam C., Thaer Samar, Jacco van Ossenbruggen, and Lynda Hardman. 2018. “Impact of Crowdsourcing OCR Improvements on Retrievability Bias.” In Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries – JCDL ’18, 29–36. Fort Worth, Texas, USA: ACM Press.
https://doi.org/10.1145/3197026.3197046.