As KB Researcher-in-Residence and fellow at the Center for Advanced Internet Studies (CAIS), I currently study the KB’s unique collection of archived LGBT+ websites. This blog highlights steps that are a prerequisite to conduct computational analyses on this corpus, or on any other web archive. That is, conducting research on a web collection first requires research into this collection. What data is available? What is the quality? In short, then, this blog shows how I prepared a data set. It contains concrete lessons for both the KB as well as researchers who want to work with web archives.
In mid-2021 the National Library (hereafter: KB) issued its annual call for its Researcher-in-Residence program. This program enables researchers to analyze KB data in innovative ways to answer fundamental research questions, which in turn ought to improve KB services. Recipients are aided by a team of KB researchers. Unlike previous years, the call explicitly stated that the KB preferred projects that would harness underused datasets, such as its web archive.
The focus of this call was much needed. Even though archived websites are critical to understand our recent past and cultural heritage (Brügger, 2018; Milligan, 2019), the KB and other national libraries struggle to have researchers and the wider public engage with their web archive. A decade ago, it was noted that ‘[archived web] content is now awaiting users, like books in libraries awaiting borrowers’ (Rogers, 2013, p. 73). By and large, not much has changed since. In short, ‘limited access to most existing web archives, along with the limits of interfaces and processing infrastructures, and lack of sufficient contextualization information about appraisal, provenance and completeness, drive many historians away from using web archives for web history, and especially from applying various data analysis methods that would be native to the medium’ (Ben-David & Amram, 2018, pp. 159–160). However, researchers are to blame, too. Historians in particular still ‘remain largely oblivious to the richness of the archived Web as a primary source for the study of the recent past, if not oblivious to the very existence of Web archives’ (Winters, 2018, p. 593). Put differently, a chicken-and-egg problem exists: web archives are flawed, but if historians and other scholars do not scrutinize them and document how they can be used, they will remain underused, among others because libraries will be less inclined to devote resources to enhance the quality and accessibility. This in turn will result in blind spots in the historical record, particularly regarding the history of marginalized groups who have massively relied on the Web, such as LGBT+ people.
To help overcome this problem and create workflows that will help others engage with web archives, I capitalized on the call by submitting my project Mapping the Dutch Queer Web Sphere. Using Web Archive Hyperlinks and Named Entities to Reconstruct Historical Networks. A little under a year later, the KB officially launched its LGBT+ web collection (collection description). Following my proposal, it publicly acknowledged the urgency to preserve the online history of queers in the Netherlands, as the World Wide Web has been revolutionary to LGBT+ people in particular. During my residency I study this history employing two computational methods: hyperlink analyses and Named Entity Recognition. Both are distant-reading methods. This means that it is important to establish the quality of the data beforehand, to avoid a problem that is well-known in Digital Humanities research: garbage in, garbage out.
The need of extensive metadata
When I drafted my proposal, I could merely consult the public list which indicates which URLs have been harvested. However, the KB holds a file that contains additional, insightful metadata. Figure 1 presents the first lines of this file.
Figure 1. Excerpt of the file containing metadata about the LGBT+ web collection
They pertain to the first LGBT+ website that has been harvested, IHLIA, an influential LGBT+ heritage organization. This file contains a wealth of information. Among others, it shows that the first two harvests of ihlia.nl took place on April 4 and September 7, 2009 (lines 2 and 3, column H), which resulted in data files of about 1.4 and 1.6 GB, respectively (column I). My advice is to put this more elaborate file online, too, much like the KB publicly provides information about which and how many digitized newspapers are included in its extremely popular repository Delpher. To the very least, this information will help researchers to establish the aforementioned ‘appraisal, provenance and completeness,’ i.e. which and how much data is available and, subsequently, whether they are interested in studying these sources. Moreover, web archive scholars have rightly stressed that ‘web archiving is a complex, obscure and largely dark process’ (Bingham & Byrne, 2021, p. 3) – arguably more complicated than digitizing newspapers, which also poses problems (e.g. Verhoef, 2015, 2016, 2017). All the more reason, then, to be as transparent as possible.
At the start of my residency, I scrutinized the aforementioned metadate file. It should be noted that my project is particularly interested in mapping the networks that queer websites comprised over time, among other by analyzing how websites linked to another and to non-queer websites. Since most websites have been harvested once annually, I will do so by creating one network graph per year, for each of the most recent years. It is therefore critical to create a corpus that is composed of websites which have successfully been harvested each year, otherwise I would compare apples with oranges.
Quality of harvests
Alas, successful harvests are far from self-evident. Iris Geldermans provided me with quality control criteria that the KB uses to check whether this is the case. As the web archive grows bigger exponentially – each of the websites in the extant collection continues to get harvested annually, but on top of that new URLs are added frequently – it is impossible to ‘manually’ check the quality of individual harvest. Therefore, the KB uses the size of the harvest as an indication of the quality (see table 1).
Iris and I fine-grained this assessment. We established that in practice, harvests that had likely hit the maximum size limit which the KB wields – about 1.2 GB – resulted in a size of between a little over 1.2 GB and 2 GB. This owes to the fact that when the harvester hits the limit, it still finishes what it is working on, which might contain larger elements, such as pictures. I have created a list of websites this pertains to, which the KB could use when it decides to increase the limits of certain URLs. In the past, it has already done this for a few websites, such as coc.nl and ihlia.nl. These are the ones that have a harvests size of over 2 GB. For reasons mentioned before, I advise the KB to publicly share information about the harvest limit and exceptions, too.
Table 1: Presumed relation between size and quality, as used by the KB.
| Harvest size | Meaning |
| 0 bytes | Harvest failed |
| Under 1 KB | Harvest probably failed |
| 1KB-1MB | Questionable quality: Either very small website or partly failed harvest |
| 1MB-1.2GB | Harvest probably successful |
| 1.2-2GB | Harvest probably successful, might have run into the standard harvest size limit the KB uses |
| Over 2 GB | Harvest probably successful, size limit likely manually increased by KB |
I used this information to generate an overview of the quality of the harvest of LGBT+ websites per year (table 2).
Table 2: Number and quality of harvests of LGBT+ websites per year.
| Until 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
| 0 bytes | 0 | 0 | 0 | 3 | 6 | 3 |
| Under 1 KB | 18 | 45 | 46* | 6 | 8 | 13 |
| 1 KB - 1 MB | 24 | 20 | 27 | 30 | 25 | 30 |
| 1 MB - 1.2 GB | 205 | 76 | 160 | 228 | 249 | 315 |
| 1.2.GB - 2 GB | 41 | 12 | 20 | 35 | 34 | 60 |
| Over 2 GB | 9 | 0 | 2 | 4 | 6 | 9 |
| No info | 0 | 0 | 0 | 1 | 5 | 1 |
| Total | 297 | 153 | 255 | 307 | 333 | 431 |
*=corrected, one URL was incorrectly harvested 1040 times within three days due to a scheduling mistake.
Before I discuss this table, it should be noted that harvesting LGBT+ websites only really gained traction in 2018. It is no coincidence that only from that year onwards, LGBT+ sites have been grouped in a designated ‘LGBT collection.’ As of 2009, 8 different websites were harvested. Subsequently, the number grew slowly and haphazardly. In each of the years 2010 through 2014, for example, a maximum of 3 new URLs were added. In short, at the end of 2017 only 35 websites had been harvested at least once (some multiple times per year, resulting in the 297 harvests) – a number so small that this data has been grouped in the category ‘until 2017’.
Turning this metadata into a visualization (figure 2) highlights that the overall quality of the data in the years 2018 and 2019 is questionable.
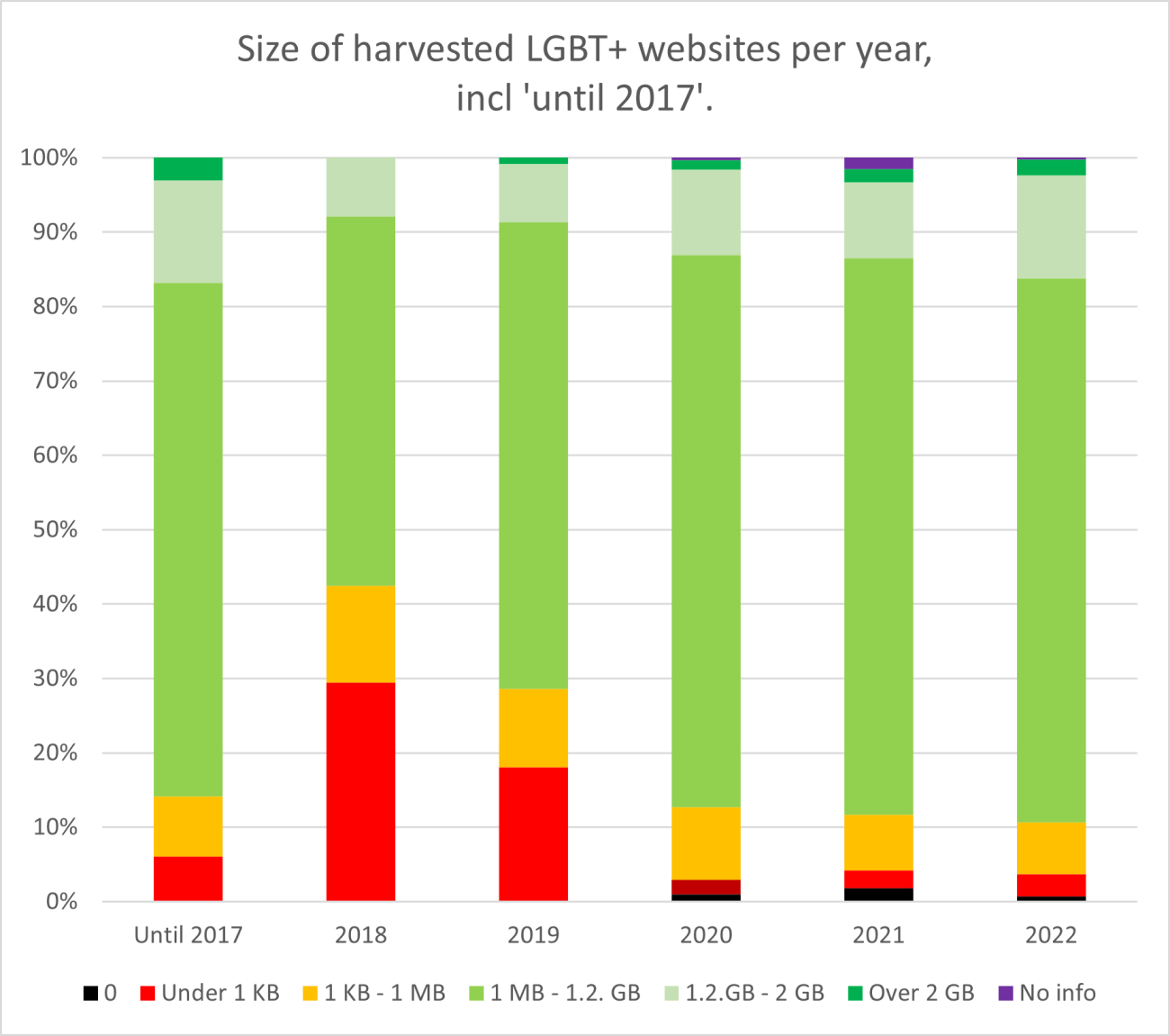
Figure 2. Quality of harvested LGBT+ websites over time. Courtesy of Iris Geldermans.
This could owe to the fact that in these years, many websites switched from http to https and the crawler that was used at the time to harvest websites was not able to bypass this problem. Either way, the poor quality of these two years had me decide to exclude this data and focus on the years 2020 through 2022 – at least as far as the network visualization based on hyperlinks are concerned; additionally, I will conduct case studies that do span the era 2009-2022 in toto.
A final data preparation step entailed perusing the metadata file line by line for the years 2020 through 2022. I compared the quality of harvests of each single URL from one year to the next. If the harvest in one or more years was unsuccessful, I excluded this website from the corpus for reasons mentioned before: I want to diachronically compare one-and-the-same corpus. ‘Unsuccessful’ need not necessarily entail a harvest size of under 1 KB. A large deviation vis-à-vis other years may also qualify, which for instance goes for the website gayslowdating.nl (figure 3).
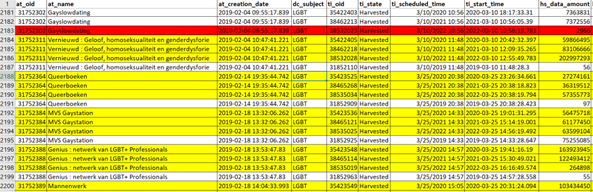
Figure 3. Excerpt of how I used the metadata file to exclude URLs that have (likely) not been harvested successfully, in this instance gayslowdating.nl.
Of course, if the quality of a recently harvested website was questionable, I could check whether the website was in fact online. Gayslowdating.nl was not – and it is likely it was not online at the time of the harvest, which could explain this outlier.
From data preparation to data analysis
In sum, this process has resulted in the creation of corpus of 201 queer websites that seem to have successfully been harvested in each of the years 2020, 2021 and 2022. Additionally, I have prepared another corpus of websites that appears to have successfully been harvested in 2022. Even though I will not be able to compare that to previous years, turning the latter into a network visualization will provide insight into the most recent Dutch queer web sphere. Since the LGBT+ web collection has grown considerably over the last two years, this corpus is significantly larger and comprises 348 unique websites.
We are currently in the phase of moving from data preparation to data analysis. Building on the work done in conjunction with the previous researcher in residence, software engineer Willem Jan Faber has indexed the selected data in a SolrWayback environment. We will use this interface to extract hyperlinks – which I will subsequently analyze in Gephi – and conduct Named Entity Recognition. In the next blog, I hope to inform you on the outcomes of these analyses.
Literature
Ben-David, A., & Amram, A. (2018). Computational Methods for Web History. In N. Brügger & I. Milligan (Eds.), The SAGE Handbook of Web History (pp. 153–167). SAGE.
Bingham, N. J., & Byrne, H. (2021). Archival strategies for contemporary collecting in a world of big data: Challenges and opportunities with curating the UK web archive. Big Data & Society, 8(1).
Brügger, N. (2018). The Archived Web: Doing History in the Digital Age. MIT Press.
Milligan, I. (2019). History in the Age of Abundance? How the Web Is Transforming Historical Research. McGill-Queen’s University Press.
Rogers, R. (2013). Digital Methods. MIT Press.
Verhoef, J. (2015). The cultural-historical value of and problems with digitized advertisements. Historical newspapers and the portable radio, 1950-1969. Tijdschrift Voor Tijdschriftstudies, 38, 51–60.
Verhoef, J. (2016). Lawaai als modern onheil. De draagbare radio en beheerste modernisering, 1955-1969. Tijdschrift voor Geschiedenis, 129(2), 219–240.
Verhoef, J. (2017). Opzien tegen modernisering. Denkbeelden over Amerika en Nederlandse identiteit in het publieke debat over media, 1919-1989. Eburon.
Winters, J. (2018). Web Archives and (Digital) History: A Troubled Past and a Promising Future? In N. Brügger & I. Milligan (Eds.), The SAGE Handbook of Web History (pp. 593–605). SAGE.
