Introduction
Update 2 October 2025: the live demo is no longer supported by the KB Lab and has been removed.
Context
Tracing semantic patterns over time on the basis of texts is still in its infancy. Most approaches build on a linguistic principle which states that the meanings of words are determined ‘by the company they keep’. In other words, meanings arise from contexts defined as distributions of words, which suggests that we can trace meanings over time by examining changing contexts. Topic modelling is at this moment the only technique based on the principle of word distributions that has gone beyond an experimental stage and has proven its value by achieving results that domain experts (in this case historians not necessarily involved in computer-assisted research) recognize.
Tool
The ‘Frame generator’, developed by the KB Lab in collaboration with cultural historian prof. dr. Joris van Eijnatten in the context of his KB Fellowship (2016), is a tool aimed at meaningfully reducing a set of (possibly thousands of) texts to word patterns that cut across the distributions generated by topic modelling, thus providing additional insight into the content of the dataset. The method implemented builds on topic modelling by combining it with two other proven techniques: (1) the automatic extraction of keywords and (2) the identification of co-occurrence patterns.
Features
- Generate topics with the Mallet or Gensim topic modelling library
- Extract a single, ranked list of keywords based on either topics or tf-idf scores
- Find co-occurrence patterns for the keywords in the texts from which they were originally extracted
- Optionally lemmatize and pos-tag the input texts with NLP suite Frog and restrict the keywords and collocates to specific part-of-speech tags
- Optionally correct OCR errors and spelling variations with user-provided lists of regular expressions
- Access and reuse the results of each processing stage as comma-separated values files
- Use from the command line, as a Python library or web application
When using the Frame generator, we request you to cite it as follows:
Lonij, J., Eijnatten, J. van. (2016), Frame Generator. KB Lab: The Hague http://lab.kb.nl/tool/frame-generator
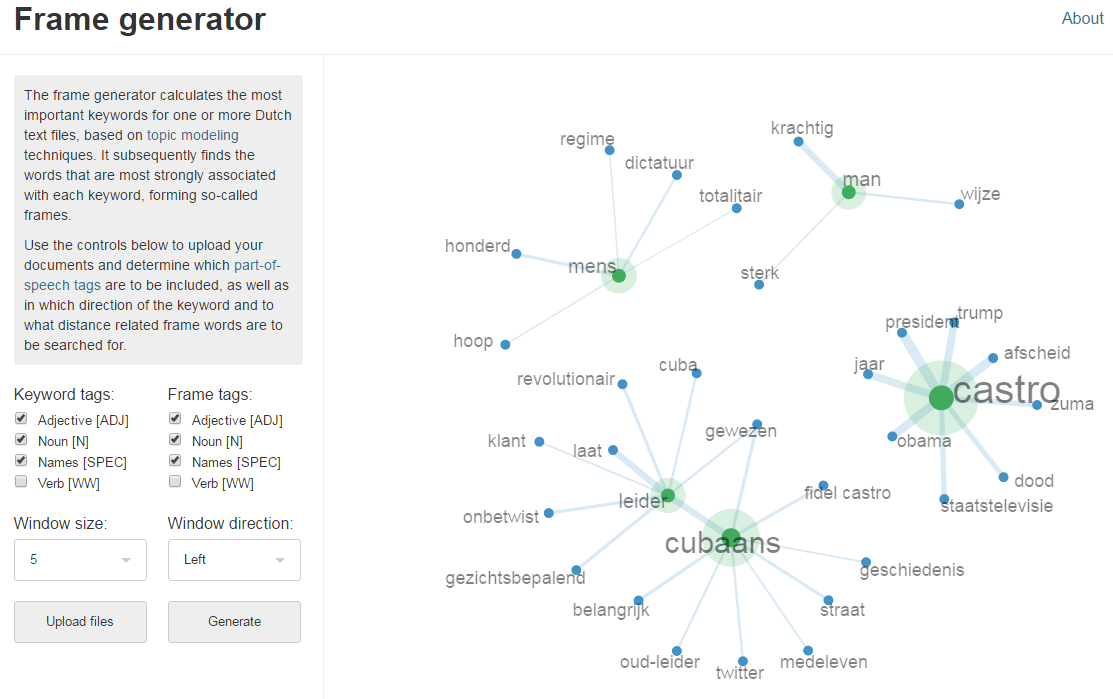
Instructions
Online demo
An online demo with a graphical user interface, showcasing Frame Generator’s main functionality, is available at the tab Live Demo. This web interface includes a basic visualisation of the results as well.
To use the demo, upload one or more plain text files (with .txt extension) with the button 'Upload files'. A number of settings can be controlled:
- Select the part-of-speech tags to be included in generated keyword list as 'Keyword tags'.
- Select the part-of-speech tags to be included as collocates for each keyword as 'Frame tags'.
- Set the the maximum word distance of a frame word to the corresponding keyword with 'Window size'.
- Set the direction (left, right or both) of the keyword in which frame words are searched for with 'Window direction'.
Once all options are set, press the 'Generate' button to generate keywords and frames for the uploaded text(s). This may take some time, but when the process completes a visualisation of the results appears in the right column.
Examples
Concept Europe
The Frame Generator was initially used to investigate popular perspectives on the concept of ‘Europe’ arising from the KB collection of Dutch historical newspapers. To this end, a dataset was prepared of articles that mentioned the word ‘Europe’ at least once. A subset of articles was then selected on the basis of (Dutch-language) synonyms for the words ‘unity’ and ‘unification’ (such as ‘integration’, ‘agreement’, ‘settlement’, ‘consensus’, ‘treaty’, ‘harmony’, etc). This subset was assumed to contain news articles that discuss Europe as a unified political / cultural / economic entity, or as an entity involved in a process of unification. The other subset was based on synonyms for competitions (such as ‘match’, ‘prize’, ‘winner’, ‘cup’, etc); this subset was assumed to contain articles on sports and other competitions. The data from each of these two subsets were grouped into 10-year periods.
Analysis
The datasets prepared were analyzed with the Frame Generator, using the command line interface. The results were interpreted by visualizing the co-occurrence networks with Gephi. For our use case we found that newspaper reporting on ‘European unity’, while showing a remarkable degree of continuity, became less rich rhetorically, less international, and more focused on institutional technocracy than on intra-continental relations.
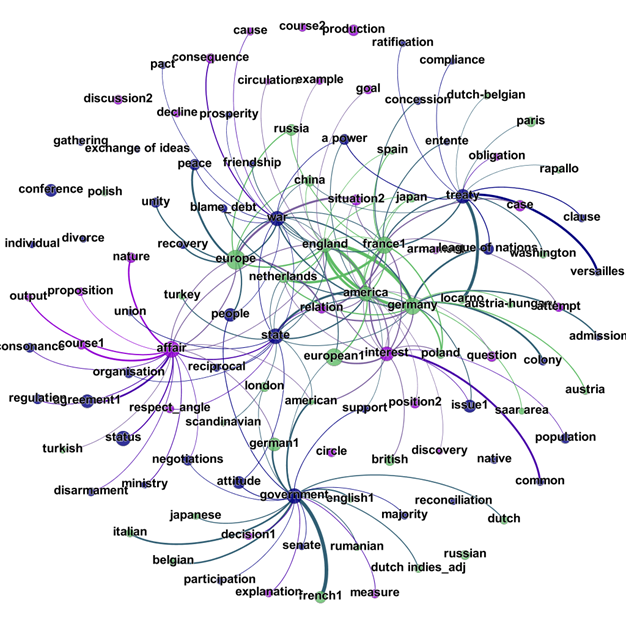
Network graph in Gephi showing a frame of contextualised keywords related to spatial entities (green), concepts related to community formation (blue) and abstract terms (purple), based on newspaper articles from De Telegraaf (1925-1929; n = 767).