At the KB, we have been experimenting with Annif, a tool for automated subject indexing that is under active development at the Finnish national library - see http://annif.org/. We were curious to hear about initiatives in other organizations for using Annif, so on 2 April 2020 we organized a meet-up with Dutch (prospective) users of Annif. It was a virtual meeting (through MS Teams) of twelve people, among which was the Finnish development team. Some of the attendees were curious to hear how the tool had been used by others, to see if they could formulate their own use case. Others had already conducted experiments with Annif on various sources, and presented their findings on the following cases:
· Dissertations (Sara Veldhoen, KB) During ICT with Industry 2019, the KB worked together with a team of 11 external researchers on their case: can the correct research topics of dissertations be suggested automatically? Annif was one of the tools they experimented with. Read more: https://zenodo.org/record/3375192
· Ebooks (Thomas Haighton, KB) The KB seeks to develop tools that help catalogers with subject indexing. They train Annif to obtain suggestions based on title and summary (or blurb, 'flaptekst') and soon also on full text.
· Legislation (Annemieke Romein, Huygens ING) Annemieke hand-annotated early modern legislative texts ('Placcaeten') with categories from a hierarchical, domain-specific ontology. In her Researcher-in-Residence project at the KB, the books were made machine readable by applying HTR. As a proof of concept, they segmented one book into laws and trained Annif to assign the categories. Read more: https://lab.kb.nl/about-us/blog/categorisation-early-modern-ordinances
· Scientific papers/ research output (Yasin Gunes, VU Library) The university library applies NLP for harvesting information about publications, collaborations, and combining (matching) information from multiple sources. They create dashboards that visualise impact of research, for instance how it is related to SDGs. Annif may as well be trained treating SDGs as subjects (dataset will be published soon). Also, they consider having Annif suggest keywords to reduce the workload of the experts that assign keywords to publications. Read more: https://github.com/Yasin-VU/simple-python-bibliometrics
· Short articles on CBS website (Henk Laloli, CBS) CBS regularly publishes articles that are provided with keywords by the authors, from a controlled vocabulary (https://taxonomie.cbs.nl/). Even though the initial performance metrics were not so high, suggestions for new articles seemed useful in practice. Another consideration was whether it would be possible to link subjects to datasets/ tables (with Annif, if at all).
During the presentations and in the discussion afterwards, several topics were discussed that apply to many of the use cases. In what follows, I try to summarize them.
Backends
Annif includes several backends: different algorithms or models that underly the suggested topics. Each individual backend comes with strengths and weaknesses. Annif also allows one to compile an ensemble model, that combines results from trained models to obtain reliable outcomes. The ensemble can also be learned (metalearning).
How to determine what backend is useful for a specific use case? This is partly covered by this Annif tutorial https://github.com/NatLibFi/Annif-tutorial. The most important factors are the amount of training data, vocabulary size, and whether the input are short texts (titles) or full text. There's probably much more to say about this, which might be added to the Wiki. At the meetup, we discussed the following.
TFIDF is a very basic model, that doesn't take a lot of work to get running. You could see it as a "Hello World" backend: to make sure everything is installed correctly and runs smoothly.
Some backends, typically those that involve a lot of machine learning such as FastText, require more tuning of hyperparameters to get good results. This can be a lot of work, so sometimes you might favor models that work better out-of-the-box such as Omikuji.
In many cases, data can be imbalanced or skewed: there are many documents on a certain subject, and much less on another subject. For instance in the dissertation study that I presented, only the first 500 subjects have more than 25 documents. In the image below, the x-axis corresponds to subject rank (ordered by frequency) and the y-axis to the frequency of the subject (color indicates the source university).
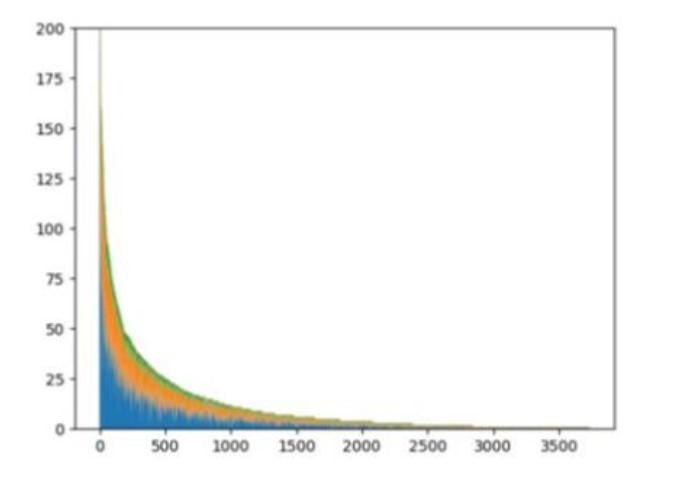
To deal with imbalanced data, Omikuji is probably a good backend as it was designed for extreme multilabel classification. For topics with few documents to base statistical models on, a lexical approach (Maui) may be best suited.
Data
For training the machine learning backends, annotated data (ground truth) is needed. Do not underestimate the amount of work it takes to preprocess and clean your data (I wrote an article in IP about this).
How much data is needed, depends a bit on the nature of the data (the documents and the subjects). As a rule of thumb, Osma suggested to have 10-100 training documents per subject.
It is possible to put a human in the loop that curates the results, so that the model can continue training using that as feedback. Whether this is possible depends on the backend, it currently work only with Vowpal Wabbit and NN ensemble.
It may be even better to have Annif report what documents it is least confident about, so that human annotators can focus their attention on those. However, this requires the backends to report some sort of confidence. The current algorithms are not good at estimating confidence, or it is not clear how it should be interpreted.
Vocabularies
An open question remains how to deal with the dynamic nature of subjects. New tags/ subjects can be added weekly. It would be even greater to have algorithms signaling new topics. It is not yet clear how to implement such things, but Osma suggested that lexicalized models (like Maui) might be more capable than statistical models.
Language variation
By design, languages are kept separate in Annif. Models cannot benefit from documents that share the same subjects but are written in different languages. Some experiments on multilingual vector spaces (https://github.com/commonsense/conceptnet-numberbatch) didn't yield good results and proved very inefficient.
One approach is to translate documents (e.g. through Google Translate) and then apply Annif. Note that this solution does not work for historical languages.
Also, not all backends support all languages. Annif does not rely on extensive natural language processing though: mostly stemming needs to be implemented, and a list of stop words added. The Radboud University in Nijmegen maintains LaMachine (https://proycon.github.io/LaMachine/), a package that includes several NLP modules tailored for Dutch.
The Maui backend, that is not actively maintained but was adopted by the Annif team, does not offer Dutch support. Note that this backend is Java-based, so the stemming should also be implemented in Java. If a stemming algorithm exist, integrating this into Maui should not be much work.
Evaluation
F1 and NDCG are the usual metrics to optimize for. They may obscure the performance in the long tail though. It could make sense to add additional requirements, such as having at least x% f1-score for every class. That would enforce the model to perform well across the board.
Subject-indexing is inherently subjective: people tend to disagree on the correct subject to assign, so there is no way a computer can be flawless. The Annif team did a comparison 2.5 years ago, to determine inter-annotator agreement (only 1/3 of the subjects were identical) and to compare algorithmic outcomes to human decisions. A follow-up study was performed last fall, where librarians judged lists of suggestions (double blind) - see https://tietolinja.kansalliskirjasto.fi/2019-2/1902-aaveita/ (in Finnish).
Annif in practice
Annif is used in the real world by the university of Jyväskylä for Master’s and doctoral theses: Annif provides suggestions, and the student/librarian curates the result. See LIBER Quarterly paper for some details. Kirjavälitys Oy, a Finnish company that manages logistics for booksellers (including metadata from publishers) also use Annif. They use book descriptions (marketing texts from publishers) as input to get an initial suggestion for subjects, which they curate manually. These enhanced metadata records are then distributed to Finnish libraries. And the University of Vaasa just started using Annif for their document repository.
Wrap-up
It was an enjoyable meet-up, with inspiration from existing use-cases and an informative discussion. We'd like to thank all attendees for joining, the Finnish development team in particular.
Please get in touch with us to spar if you consider using Annif for your use-case, or if you struggle with getting it to work. Also, subscribe to the Annif users mailing list: https://groups.google.com/forum/#!forum/annif-users, the active community channel where you can ask all your questions.
