Introduction
Description
We have designed DIGGER in order to study the evolution of the Dutch urban system by investigating information flows extracted from historical newspapers that go back to 1869. Newspapers are full of geographical information as most of news items include one or more place names. However, studying this geographical information systematically is not an easy task. In this project, we have geocoded place names contained in a selection of 102 million news items by developing a method coupling fast SRU queries and Named-Entity Recognition. The resulting dataset allow to create origin-destination matrices representing information flows between cities for more than one century..
The detailed description of the data collection can be found in the data paper section of the journal Cybergeo.
Acknowledgment
DIGGER was created while Antoine Peris was researcher-in-residence at the KB. During the data collection, Antoine was assisted by Willem Jan Faber from the Research Department of the KB.
The authors would like to thank Martijn Kleppe, Lotte Wilms and Steven Claeyssens for their availability and support during and after the creation of the dataset. Moreover, we thank also Evert Meijers and Maarten van Ham for their enthusiasm and all the fruitful discussion that have been very important the design of the data collection.
Academic papers
- Peris, A., Faber, W.J., Meijers, E., van Ham, M., 2020. One century of information diffusion in the Netherlands derived from a massive digital archive of historical newspapers: the DIGGER dataset. Cybergeo : European Journal of Geography. https://doi.org/10.4000/cybergeo.33747
- Peris, A., Meijers, E., van Ham, M., 2021. Information diffusion between Dutch cities: Revisiting Zipf and Pred using a computational social science approach. Computers, Environment and Urban Systems 85, 101565. https://doi.org/10.1016/j.compenvurbsys.2020.101565
When using this dataset we request you to cite it as follows:
Peris, Antoine; Faber, W.J. (Willem Jan) (2019): DIGGER: a dataset built on Delpher, the digital archive of historical newspapers of the National Library of the Netherlands. 4TU.ResearchData. Dataset. https://doi.org/10.4121/uuid:a14a1607-dafe-4a8a-aebc-d1c5cd66a588
Access
Dataset
The dataset consists of two main files that can be assembled together in order to create an origin-destination matrix representing information flows between cities. They contain the frequency of mentions of places in each newspapers with a time granularity of one year. In freq_count_STR.csv, one can find this data for unambiguous place names, and in freq_count_NER.csv, the data for ambiguous place names (that necessitated an extra step of Named Entity Recognition). Other files with metadata or contextual information on the cities can be found in the repository, see the section “Data collection and structuration” of Peris et al. (2020) for more information.
The dataset is accessible on the 4TU dataverse in open access under the license CC-BY.
Examples
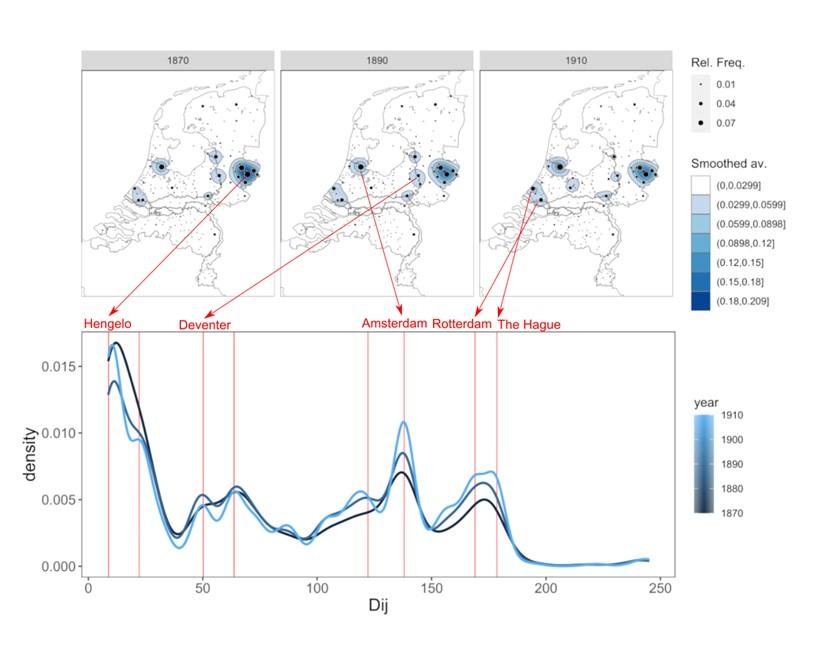
In the following graph, we map the places mentioned in the news from the regional newspaper Tubantia, published in Enschede, for three different periods of time (1870-1889, 1890-1909, 1910-1929). The kernel density distribution of the distance between the origin of the news (the places mentioned in an article) and the destination (the place of publication) is also plotted.