In the previous blog post , we talked about the benefits and the challenges of entity linking on Dutch historical documents. This post will describe the progress made during my researcher-in-residence project and the possible future work directions for the researchers interested in entity linking.
As mentioned in the previous post, the task of entity linking (EL) generally consists of three steps:
- Named entity recognition (NER): automatically detecting names of people, places, and other entities of interest mentioned in unstructured textual data
- Candidate generation: finding potential matches (candidate entities) in a knowledge base for the entity mentions extracted at the first step
- Disambiguation: using context information to choose one correct candidate for every entity mentioned in the text
My contributions as a researcher-in-residence at the KB consist of two parts. The first part concerns the first step of entity linking, and consists of three NER models and a dataset annotated by these models. The second part includes experiments that take us towards solving the other two steps, candidate generation and entity disambiguation.
Named entity recognition
The task of automatically extracting named entities from text is typically approached as a token classification problem. Every token (word or sub-word) in text is tagged with either ‘B-[ENT]’, ‘I-[ENT]’ or ‘O’, which corresponds to the beginning, inside or outside of a named entity of a certain class. For example, ‘B-PER’ is the beginning of an entity with the type “person”. A common approach to NER is to fine-tune a language model (such as BERT) on the token classification task, using training data that has been labelled in the way described above. The model uses context to predict labels of unseen tokens: for example, even if the village name “Muggenbeet” was absent from the training data, a good quality NER model will be able to tag it as a location in a sentence like “Hij woont in Muggenbeet”.
Dutch historical texts are a challenging domain for NER: OCR errors and historical spelling variations can affect both the entity names and the context around them. Recently, a useful resource for Dutch historical NER has been released by the Dutch Language Institute: a training dataset consisting of historical notary records between the 17th and 19th century, manually annotated by volunteers with PER (person), LOC (location) and TIME labels. Another recent breakthrough is the release of GysBERT, a BERT-based language model designed specifically for historical Dutch. Given these developments, it is natural to explore the potential synergy between them.
We used the NER dataset to fine-tune GysBERT alongside two other BERT-based models, BERTje and mBERT, and compared the performance of the three models. Surprisingly, GysBERT did not have any obvious advantages: all models performed on par with each other and outperformed a baseline non-historical multilingual NER model by a large margin.
Further analysis showed that the mistakes of the three models typically don’t overlap, which means that using all of them together in an ensemble can lead to improved results. The code for training and evaluating the models is available on GitHub. More details can be found in the paper we published at the LT4HALA ‘24 workshop (LREC-COLING conference).
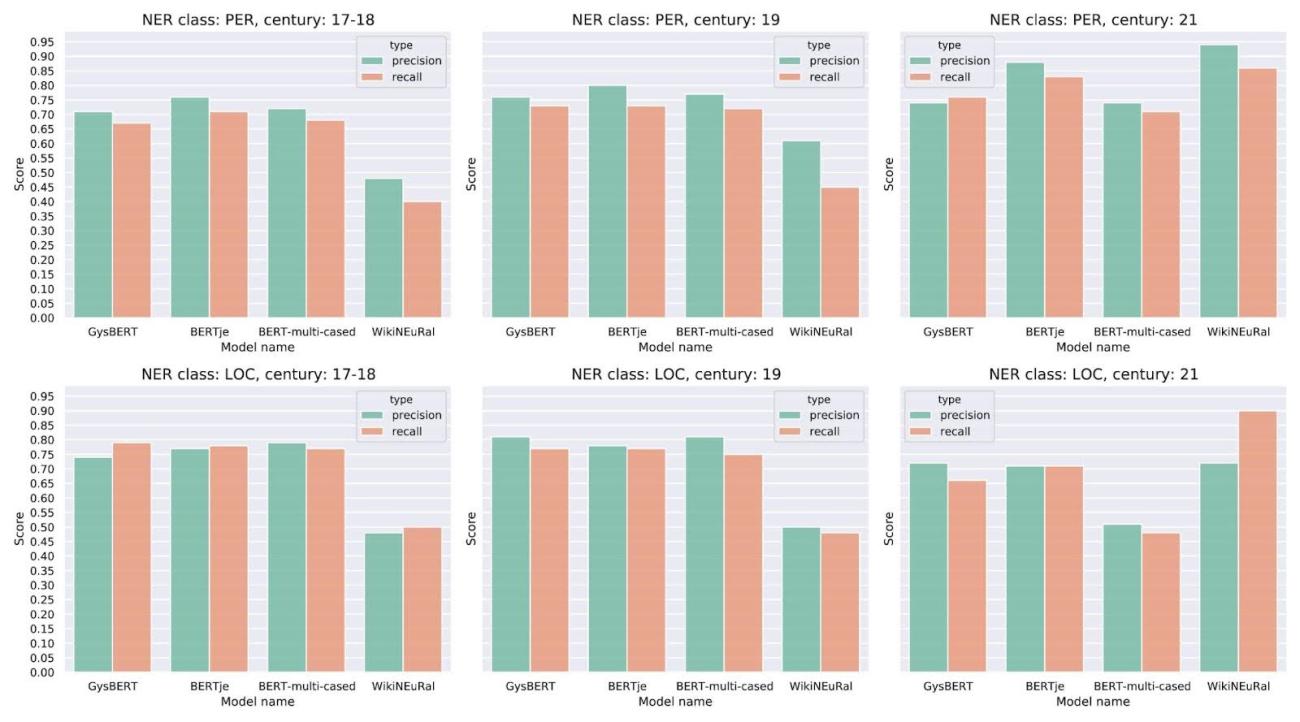
Figure 1: Evaluation results of the 3 fine-tuned models and a baseline model on the test subset of the dataset from the Instituut voor de Nederlandse Taal.
Expanding these developments, we applied the three NER models to the open domain part of the DBNL data, which consists of 3542 publications. The resulting dataset is available here. The dataset consists of 4 parts: the predictions of each of the 3 NER models and the predictions obtained by combining the models in majority voting. It can be used as silver data for training entity linking models, or in digital humanities applications.
Towards entity linking: expanding the annotations
Most entity linking benchmarks consider large knowledge bases, such as Wikidata. Connecting named entities from the DBNL dataset to Wikidata would offer numerous research opportunities in the field of historical Dutch entity linking. We take initial steps in this direction. The DBNL dataset contains a limited number of entity annotations linked to the DBNL internal thesaurus: for every chapter in the title’s TEI-XML-file, it is known when it mentions a certain author or place. While these annotations are a useful resource for entity linking, extra steps need to be taken to convert them into a conventional EL format: namely, expanding the annotations so that they point to specific entities in text rather than a chapter in general, and connecting the internal thesaurus to Wikidata.

Figure 2: A sample of the DBNL annotations.
Figure 2 shows an example of entity annotations in DBNL. There are three types of annotations: “annotatie” refers to a link to the DBNL internal thesaurus at the beginning of a chapter, while “person” and “topo” refer to named entities (people and places respectively) that are seen in the text but not (yet) linked to the thesaurus.
A straightforward approach is thus to connect the “annotatie” tags from the thesaurus with the “person” or “topo” tags within each chapter whenever possible. To do so, we used string matching as shown on Figure 3. An ID of an “annotatie” corresponding to a name shares a prefix with this name: for example, ‘mult001’ refers to ‘Multatuli’ and ‘amste001’ refers to ‘Amsterdam’.
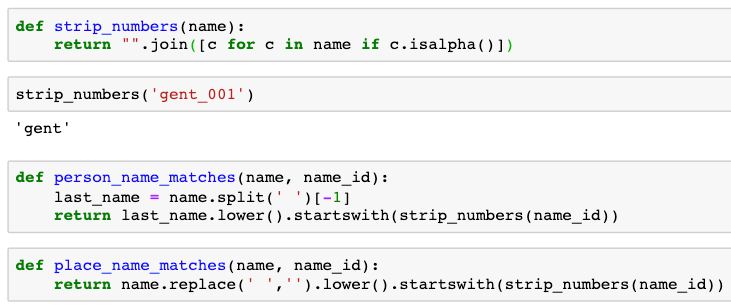
Figure 3: Code snippet for matching the thesaurus annotations with the corresponding names of people and places.

Figure 4: An example of connecting the annotations.
Figure 4 shows an example of matching the annotations: the publication “_taa001taal07_01.xml” (De Taalgids, Zevende Jaargang, 1865) contains a chapter annotation referring to vond001 (Joost van den Vondel) and a "person" tag for Vondel, so they can be connected.
Part of the thesaurus of the author names (not place names) already has a 1:1 mapping with Wikidata. We used a SPARQL query to obtain this mapping. This has resulted in getting ground-truth Wikidata links for 425 authors. For 228 authors, no link could be found.
The code for expanding the annotations and connecting part of them with Wikidata is available on GitHub. The code can be used for creating a dataset with ground-truth annotations for entity recognition and linking. Such a dataset, while too small to train a large end-to-end entity linking model, can be useful for evaluating NER and EL models in the future.
Towards entity linking: remaining steps and ideas
If a future researcher-in-residence is interested in working on entity linking (and I hope they are!), here are the next steps I would recommend:
- NER evaluation: the models released in the first part of this project have been evaluated on the Taalinstituut dataset, but not directly on DBNL. A relatively straightforward step towards evaluating them would be to use the matched annotations introduced in the second part: if an entity appears there but not in the automatic annotations, this means the models have overlooked it, i.e. made a false negative error. This method, however, does not help us find false positives (non-existent entities predicted by the model), so for a full picture a better way would be to evaluate the models manually on a randomly sampled subset of data.
- Candidate generation: we have shown that some of the author names found in DBNL can be directly linked to Wikidata via the internal thesaurus – but for many other names of people and places this is not the case. To link these names, one needs to find potentially matching candidate entities for every name and then disambiguate them. The first idea that comes into mind is to run a SPARQL query that uses fuzzy matching on the labels – however, the size of DBNL data can easily overwhelm the Wikimedia API, so extra steps need to be used (such as caching the results, pausing after a number of queries, or using a Wikidata dump instead of the online version).
- Entity disambiguation: perhaps the most interesting step, and not a straightforward one. To choose one correct candidate link per entity, one needs to use the context information. My idea is to use a semi-automatic approach: when running entity linking on a DBNL publication, pick one entity from a context window (for example, a page) and disambiguate it manually – this will be the “seed entity”. Then, disambiguate the remaining entities automatically using some measure of similarity between the seed entity and the candidates. This approach worked well when I was working on automatic network analysis for the project ArtDATIS: the dataset we had was the correspondence archive of Sybren Valkema, so by choosing “Q2618110: Sybren Valkema” as the seed entity we could tell if a candidate entity for another name is close enough to be correct. I did this using SentenceBert embeddings of two Wikidata fields of the entity: description (in case of Sybren Valkema it’s “Dutch glass artist (1916-1996)”) and professions (P106, in our case “glass artist, ceramicist, textile artist”). For DBNL it will be less straightforward, since there is no single entity that unites the whole archive, and the names mentioned in texts are more diverse in general, but maybe this approach can be used as inspiration for another method.
