Summary
Nizar Hirzalla has finished his Master AI project for the VU: Automating Authorship Attribution in Heterogeneous and Sparse Publication Data through Supervised Machine Learning. This blog post describes his project, which was performed at the Koninklijke Bibliotheek, National Library of the Netherlands and co-supervised by Sara Veldhoen.
Automating Authorship Attribution
Authorship attribution is the process of correctly attributing a publication to its corresponding author, which is often done manually in real-life settings. This task becomes inefficient when there are many options to choose from due to authors having the same name. Authors can be defined by characteristics found in their associated publications, which could mean that machine learning can potentially automate this process. However, authorship attribution tasks introduce a typical class imbalance problem due to a vast number of possible labels in a supervised machine learning setting. To complicate this issue even more, we also use problematic data as input data as this mimics the type of available data for many institutions; data that is heterogeneous and sparse of nature.
The thesis searches for answers regarding how to automate authorship attribution with its known problems and this type of input data, and whether automation is possible in the first place. The thesis considers children’s literature and publications that can have between 5 and 20 potential authors (due to having the same exact name). We implement different types of machine learning methodologies for this method. In addition, we consider all available types of data (as provided by the National Library of the Netherlands), as well as the integration of contextual information.
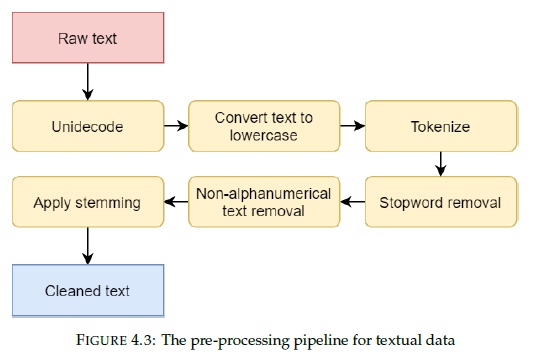
Furthermore, we consider different types of computational representations for textual input (such as the title of the publication), in order to find the most effective representation for sparse text that can function as input for a machine learning model. These different types of experiments are preceded by a pipeline that consists out of pre-processing data, feature engineering and selection, converting data to other vector space representations and integrating linked data. This pipeline shows to actively improve performance when used with the heterogeneous data inputs.
Ultimately the thesis shows that automation can be achieved in up to 90% of the cases, and in a general sense can significantly reduce costs and time consumption for authorship attribution in a real-world setting and thus facilitate more efficient work procedures.While doing so, the thesis also finds the following key notions:
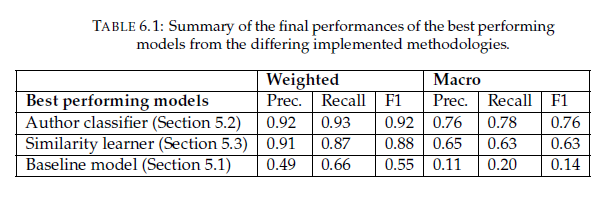
- Between comparison of machine learning methodologies, two methodologies are considered: author classification and similarity learning. Author classification grants the best raw performance (F1. 0.92), but similarity learning provides the most robust predictions and increased explainability (F1. 0.88). For a real life setting with end users the latter is recommended as it presents a more suitable option for integration of machine learning with cataloguers, with only a small hit to performance.
- The addition of contextual information actively increases performance, but performance depends on the type of information inclusion. Publication metadata and biographical author information are considered for this purpose. Publication metadata shows to have the best performance (predominantly the publisher and year of publication), while biographical author information in contrast negatively affects performance.
- We consider BERT, word embeddings (Word2Vec and fastText) and TFIDF for representations of textual input. BERT ultimately grants the best performance; up to 200% performance increase when compared to word embeddings. BERT is a sophisticated language model with an applied transformer, which leads to more intricate semantic meaning representation of text that can be used to identify associated authors.
- Based on surveys and interviews, we also find that end users mostly attribute importance to author related information when engaging in manual authorship attribution. Looking more in depth into the machine learning models, we can see that these primarily use publication metadata features to base predictions upon. We find that such differences in perception of information should ultimately not lead to negative experiences, as multiple options exist for harmonizing both parties’ usage of information.

This blog is written by Nizar Hirzalla.
The thesis Nizar has written, Automating Authorship Attribution in Heterogeneous and Sparse Publication Data through Supervised Machine Learning, can be found here on the website of his VU supervisor dr. Victor de Boer.
Figures used in this blog are found in the thesis.
The code can be found here on the KB github page.