New every week
To start with stating the obvious: the digitised newspaper collection available in Delpher is a treasure trove of historical information. One distinctive characteristic of newspapers is that they often contain information that periodically recurs in a systematic fashion with slight variations. Leading question in the DIGIFIL project, funded by CLARIAH, was: how to extract this kind of systematically repeated information in bulk, in an automated way.
Like newspapers, cinemas are institutions that function within a repetitive pattern: in the Netherlands, film programmes have changed weekly for over a century (on Thursdays or Fridays, depending on the period). And these weekly programmes were advertised in listings, called ‘filmladders’ in Dutch. Systematic knowledge about which films were screened where can teach us a lot about audience preferences and film popularity. In the ‘audiovisual’ 20th century, the cinema was one of the key channels of visual information, shaping the way citizens have viewed themselves and the world around them. The dream worlds from Hollywood have become inextricably part of our collective imagination.
To facilitate the study of film distribution and consumption in the past, Cinema Context was launched in 2006, an online encyclopaedia of Dutch film culture. Presently, it contains over 100,000 records of film programmes. These were all collected manually, by copying information from ‘filmladders’ or adverts in newspapers, be it digitised or on paper or microfilm (2006 seems like a long bygone era...). The goal of the DIGIFIL (Digital Film Listings) project was to develop ways to automate this process, having the computer extract film programmes from the newspapers for us. Cinema Context contains film programmes until 1948, therefore we focused our efforts on the period 1948-1995. Also, we decided to focus on the 4 largest cities: Amsterdam, Rotterdam, The Hague and Utrecht.

De Telegraaf, 7 February 1952, https://resolver.kb.nl/resolve?urn=ddd:110585422:mpeg21:p008
Finding a needle in the haystack
The first phase consisted of a classic 'needle in a haystack' problem: identifying the listings out of the gigantic mass of articles in the Delpher database. First, we tried to identify listings by searching the titles of segments, but there was too much variation and another obstacle was the errors in segmentation, when for instance the film listings were cut off halfway and the rest of the segment was named differently. Instead, we used a different strategy, allocating ‘cinema scores’ to segment. This score was based on the occurrence of names of cinemas or films in a certain article and this proved to work rather well. Using information from Cinema Context on which cinemas were active in which city during which period we could create lists of which cinema names to expect in which period. We created similar lists of film titles that could be expected in a certain year, that helped to establish the ‘cinema score’ of a certain article.

Algemeen Handelsblad, 25 July 1963, https://resolver.kb.nl/resolve?urn=KBNRC01:000033452:mpeg21:p007
From implicit to explicit structure
The next step was to make the implicit structure of the data explicit. Film listings are governed by a systematic pattern: they contain information on: a cinema (in a certain city), a film, time slots, sometimes also information on age restrictions. For a human reader this is obvious, but the challenge is to make this implicit structure explicit for a computer to read:
From implicitly structured data:
GRONINGEN
BIOSCOPEN: Beurs 2.30 Titanenstrijd, 6.30, 9 Complot in de Tropen. (Zo 2, 4.15, 6.30, 9); Cinema 2.30, 7, 9.15 Gienn Miller Story. (Zo. 2, 4.30, 7, 9.15); Grand 7, 9.15 Spel met de Duivel (Zo. 2, 4.30, 7, 9.15); Luxor 2.30, 4.45, 7, 9.15 Charlie Chaplin Festival.
To structured data:
<city>GRONINGEN</city>
BIOSCOPEN: <bio>Beurs</bio> <tijd>2.30</tijd> <titel>Titanenstrijd</titel>, <tijd>6.30</tijd>, <tijd>9</tijd> <titel>Complot in de Tropen</titel>.
..<bio>Luxor</bio> <tijd>2.30</tijd>. <tijd>4.45</tijd>, <tijd>7</tijd>, <tijd>9.15</tijd> <titel>Charlie Chaplin Festival</titel>.
To ‘teach’ these patterns to the computer, we manually tagged a set of listings, fed those back into the system and gradually trained the algorithm to recognise the structure of the listing. This machine learning process is similar to part-of-speech tagging, a technology that makes the implicit grammatical structure of language explicit by discriminating between verbs, nouns, adjectives in a sentence.
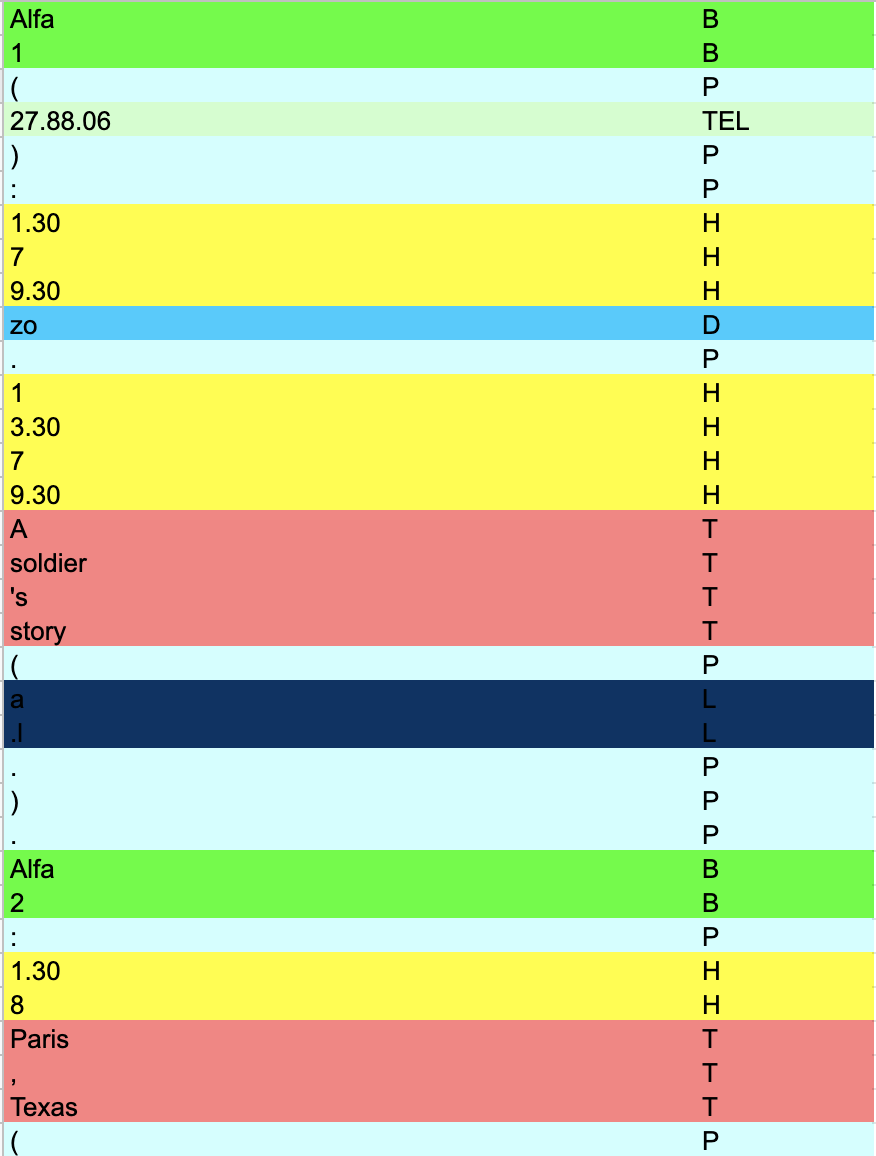
Excerpt of a training document for manual tagging: the codes and colours refer to a specific tag, e.g. B = ‘bioscoop’ (cinema), D = day, T = title, etcetera.
Matching and linking
The next step was to identify the film titles and link them to established external databases such as the Internet Movie Database, IMDb. We performed ‘fuzzy matches’ between the titles extracted from the listings (that include OCR errors but also unknown title variations) and external databases. The match ratio that signifies the degree of similarity between the listed title and the title from the external database, is a useful indicator to help judge the reliability of the match.
Results
DIGIFIL extracted over 750,000 records of film screenings from the newspapers. This is still messy data, that contains many duplicate records, and errors in matching and linking. Duplicate records, meaning information on a certain screening from more than one source (e.g. listings from various newspaper titles), are useful to establish a threshold of reliability: we can decide how many concurring observations we deem trustworthy. This way, we can select the results with the highest reliability This way, we can filter out the results with the highest reliability.
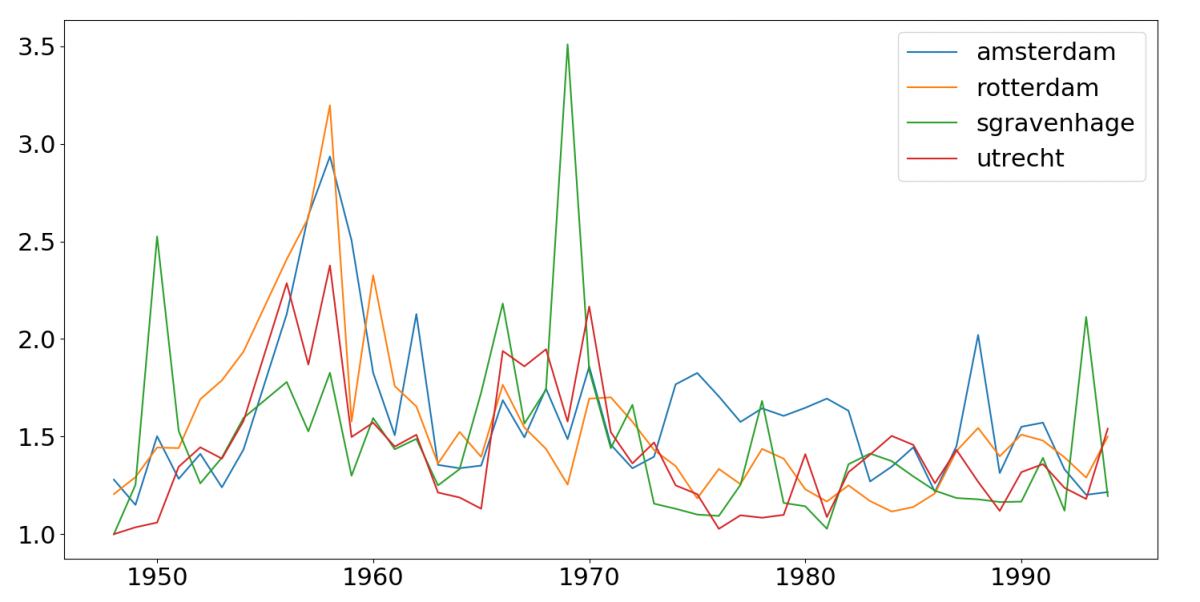
The average number of unique movie listings per day for each city per year.
We also compared the results from the automatic extraction to a sample of programming data that was manually collected. Out of 395 weekly listings for Rotterdam in the period 1951-1953 in the DIGIFIL set, 295 were correctly identified automatically, for the correct cinema in the correct week; 126 films that were screened in Rotterdam were not recognised by the script. Additionally, 296 titles turned out to be false positives, titles that were suggested by the system but not screened – although many of these prove to be relatively easy to correct.
To conclude: the project produced a large collection of film programmes that still does need manual correction, but still can save an enormous amount of manual data collection. And the data cleaning works cumulatively: the more data is cleaned, the easier it gets to improve the accuracy of the rest.
Greater ambitions
DIGIFIL focuses on the extraction of one type of micro-events, namely film screenings, but the methods that we developed invite greater ambitions. The tools may also be applied for the extraction of other types of information, including other forms of entertainment (theatre shows, concerts, radio- and television listings), but also other structured information, such as nautical movements (see map below), weather events, or stock exchange reports, etcetera, etcetera. In this sense, DIGIFIL can be a digital humanities instrument used to uncover the history of everyday life.
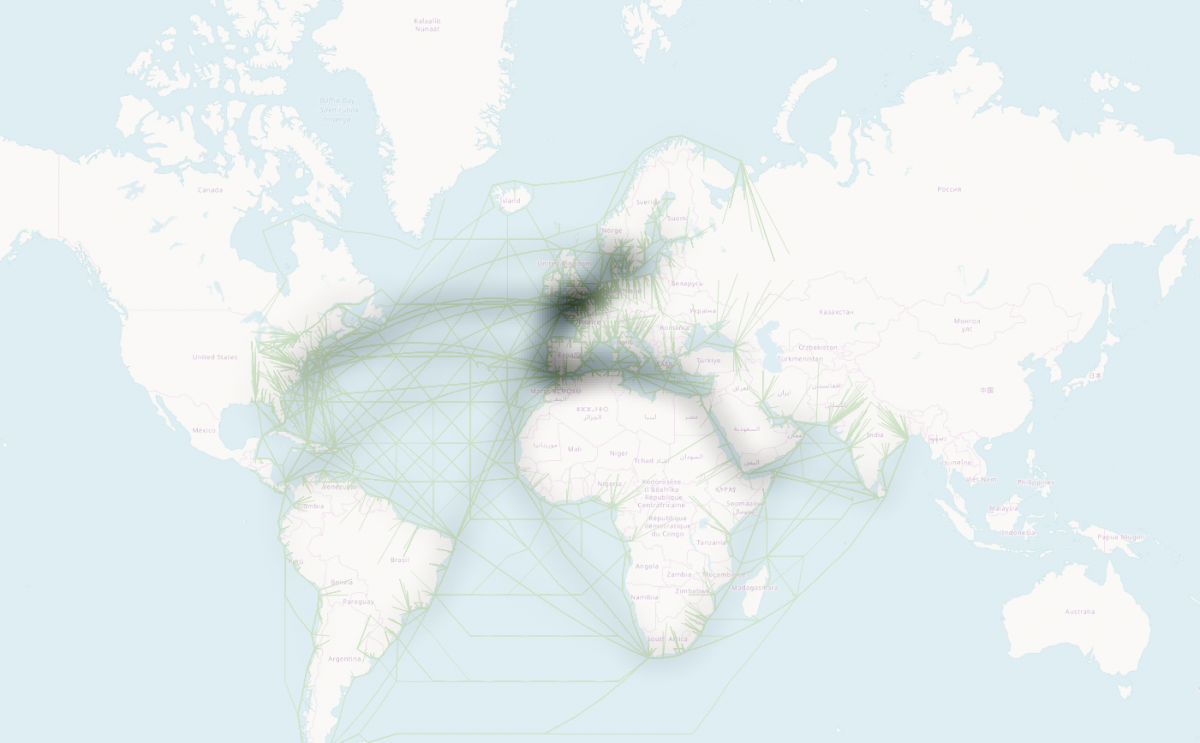
‘Scheepsbewegingen’, information on the departure and arrival of ships, geocoded for the year 1962. This graph is meant as an illustration of other possible applications of the techniques -- the data used for this map was not cleaned and can contain errors.

This guest blog is written by Thunnis van Oort
- The researchers in the DIGIFIL project are: Kaspar Beelen, Ivan Kisjes, Thunnis van Oort, Kathleen Lotze and Julia Noordegraaf
- The scripts can be found on Gitlab: gitlab.com/uvacreate/digifil/
- For more detailed information, see the project’s final report:
- DocumentDIGIFIL Final Report (659.04 KB)