Introduction
The Genre classifier has been developed within the KB Researcher-in-residence project of dr. Frank Harbers, 'Discerning Journalistic Styles' (DJS). The project examines the opportunities, approaches and issues of automatically classifying historical newspaper articles from the Netherlands for ‘genre’ as an expression of the historically and culturally determined conception of journalism.
Context
Genre is defined as conventionalised communicative forms that express a specific set of communicative goals. Examining the generic form of newspaper articles from a historical perspective therefore sheds an interesting light on the way newspaper journalism has developed. However, particularly in our current ‘age of abundance’ with more historical newspaper material than traditional methods can handle, there is a great need for new research approaches. In that respect, automatic forms of content analysis are highly suitable for longitudinal and also comparative historical research into the development of newspapers.
The DJS project
The DJS project aims to examine genre as a mode of expression of newspapers. This is a particularly challenging task as genres are dynamic and can change or fade away over time while new ones can emerge. Moreover, genres are ideal-typical discursive constructs, which means the textual manifestations do not always match the characteristics of these constructs perfectly, nor can they always be clearly delineated from other genres.
To examine this question, we have outlined an approach to automate the classification of genre of historical newspaper articles. This approach builds on an existing set of metadata (compiled during a large-scale project into the historical development of European newspapers: “Reporting at the boundaries of the public sphere. Form, style and strategy of European journalism, 1880-2005”) describing several textual characteristics, such as genre, of a large sample of historical newspaper articles. This metadata was connected to the full text of the corresponding digitised articles in the Dutch newspaper repository of the National Library (KB) to form a labeled training set for an automatic genre classifier.
The articles were cleaned of quoted text by means of regular expressions and preprocessed with the NLP suite Frog. From the resulting annotated text a number of features were calculated for each article, including length, number of adjectives, various types of pronouns and named entities found in the text. These features were used to train several classifiers to choose one of eight possible genres, ranging from news report to opinion article, for each article. A linear SVM classifier yielded the best results with an accuracy of 65%. Since the intercoder agreement for genre in the manual content analysis was around 80%, this is considered a promising first result.
When using the Genre classifier, we request you to cite it as follows:
Lonij, J., Harbers, F. (2016), Genre classifier. KB Lab: The Hague http://lab.kb.nl/tool/genre-classifier
Live demo
Instructions
Online demo
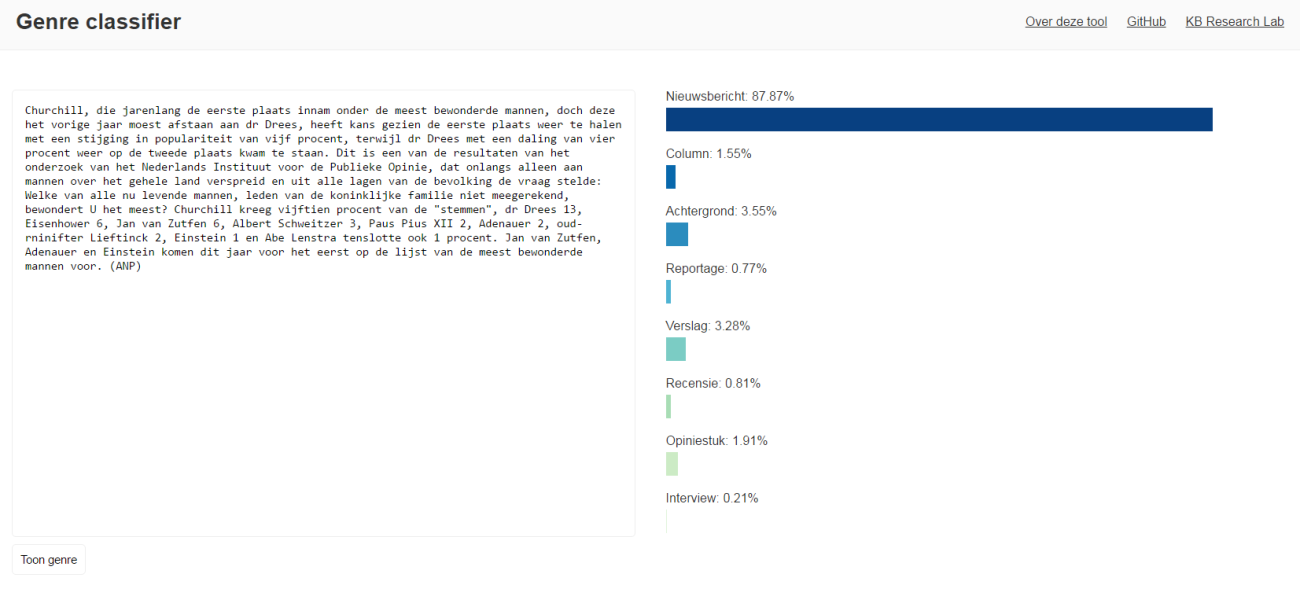
An online demo of the Genre classifier is available under the tab 'Live demo'. An example text appears and is classified when opening the tool. The tool calculates the probabilities of the text being of a certain genre and displays them in the form of a bar chart.
To classify your own text:
- Paste your Dutch (news) text in plain text format into the text field
- Click the 'Toon genre' (show genre) button at the bottom of the screen
- The result appears on the right side of the screen
Genres
The Genre classifier tries to choose one of eight possible genre for each article it examines. These genres are:
- Nieuwsbericht (news item)
- Column (column)
- Achtergrond (background)
- Reportage (reportage)
- Verslag (report)
- Recensie (review)
- Opiniestuk (opinion piece)
- Interview (interview)
Examples
The creators of this approach and tool see opportunities for researchers to study the historical development of newspaper journalism by analyzing big data sets of historical newspaper material for the use of genre. Moreover, the tool can also help to create additional metadata for digital newspaper collections, which can help users navigate through the material.