Skip to main content
Layer 1
Logo KB Lab
Hoofdnavigatie
Datasets
Tools
Tutorials
News and events
Blogs
About us
Affiliated researchers
Team
Contact
Secondary menu
NL
Open Menu
zoeken
Tool
Dutch Novels 1800-2000
Dataset that contains a corpus of 1346 novels from DBNL.
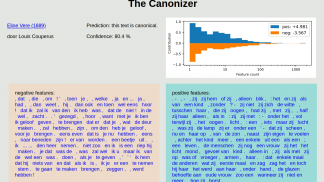
Canonizer
The Canonizer demonstrates how well canonicity can be classified based on the text of a novel.
Accessible e-books and audiobooks
We asked specialists to convert several public domain publications into accessible versions.
Ot & Sien dataset
Data for the development of the automatic visual object recognition tools in children’s books.
Is your OCR good enough?
Comprehensive assessment of the impact of OCR quality in Dutch newspaper, journal and book collections.
Assisted keyword assignment using Annif
Annif can be used to make cataloging more efficient by suggesting authors and keywords.
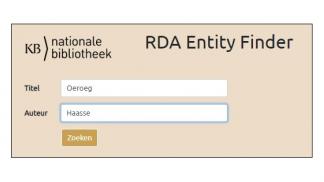
RDA Entity Finder
The RDA Entity Finder enables browsing through several bibliographic entities.
Entangled Histories: Ordinances of the Low Countries
This special collection is made up of 108 books of ordinances published in the Early Modern Era.
CanOT
CanOT shows the canonicity curves of publications related to 21 selected authors or texts/figures.
KB Lab Bot
Facebook Messenger Bot to retrieve cultural heritage masterpieces & code to build your own chatbot.
xportal
A simple search interface on Delpher data used for testing and demonstration.
Frame generator
Tool for extracting topics, keywords and their co-occurence patterns from a Dutch corpus.
Ground-truth IMPACT project
Collection of 99,95% correct OCR of books, newspapers, parliamentary papers and radio bulletins.
Example set
This collection consists of a small selection of our digitised publications from the years 1870-1871.
Python API
Simple API to access KB collections using Python.
Keyword generator
A command-line tool to extract significant keywords from a collection of sample texts.
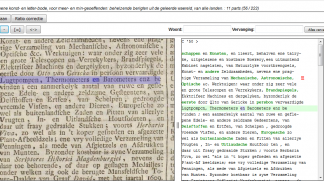
ALTO Edit
ALTO Edit is a simple browser-based post correction tool for ALTO XML files.