Introduction
Web archives do not collect and preserve only web content itself but also metadata about this content and how it was collected. It is important to understand what metadata the KB web collection has, how it is structured, and what it means because we can then
- better understand the content and scope of our web collection;
- document the metadata and make it available to end users to help them access and interpret the web collection;
- understand the semantics of the metadata and make logical inferences from it, thus expanding and deepening our knowledge of the collection;
- identify metadata that we may be missing or collecting in ambiguous ways and improve its quality;
- encode it in standardized metadata formats according to existing rules and best practices to ensure interoperability with metadata from other web archives and across domains;
- preserve it along with the archived web content to record its provenance, context, and authenticity for future generations of researchers.
In order to do so, we need to understand what metadata is currently available. Thus, we shall start by describing the data model of WCT, the software used for managing web harvests. Then I will discuss how the metadata relating to web archives can be modeled in the digital asset management and preservation system Rosetta, in a bibliographic context using IFLA's Library Reference Model and the RDA cataloging rules, and finally also in a linked data context using the CIDOC-CRM ontology.
KB Metadata Now
Currently, the only information system containing the complete metadata relating to the collection is the Web Curator Tool (WCT), an internal system for managing web harvests. Detailed documentation of web collections is published as data sets on KB Lab and as articles on Zenodo. Information about which websites are being archived can be found on the KB website in an excel table and as part of the Dutch National Web Archive Register. The archived web content can be viewed using Open Wayback in the reading room. Overall, only a fraction of the metadata the KB actually has is accessible to the public.
The Web Curator Tool is used to manage seeds and harvests. The tool is open source and developed and used by both the web archives of the national libraries of New Zealand and the Netherlands. The WCT is the first place where metadata is created. The metadata consists of some minimal descriptive metadata and curator notes, internal administrative metadata, and relatively detailed technical metadata, such as the settings for the harvest and details on its results. At the moment, it is the only information system containing the complete metadata of the KB web collection.
The structure of the metadata and the objects it relates to is derived from the architecture of the tool itself and from the decisions curators make when using it. Understanding this data model is important both for preserving the archived resources faithfully and for future researchers to correctly interpret the data they are analyzing. The WCT data model is described in the documentation (Web Curator Tool project contributors, ©2020). However, the actual use of WCT by KB differs in some respects.
Here I present a simplified data model derived from WCT but representing only those entities used by KB and relevant for understanding the KB web collection (so omitting purely administrative entities, for example). Conceptually, the most important entities are the Target Record and Target Instance.
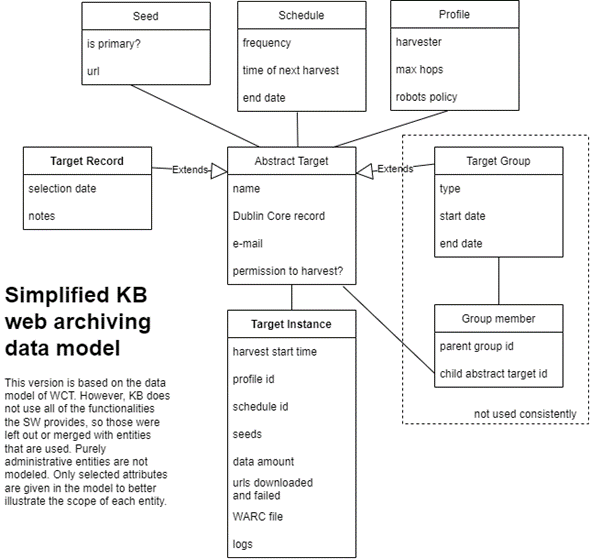
Figure 1: Simplified KB web archiving data model
A Target Record is an extension of an Abstract Target and represents a single website. It has a name and can be annotated with notes. An email is listed so that an opt-out email can be sent to the website administrators. If they do not object to the archiving of the website within four weeks, the status of the target is considered "approved." The target can also be described using Dublin Core, though most fields are left empty. Each record is assigned a subject code from a controlled vocabulary in the Dublin Core type field. A Target Record has at least one primary seed (URL), but more can be provided. This is usually done to include subdomains or, less commonly, to help restrict what is archived if the curators decide to harvest only a subset of a large site, they can then set a small path depth in the profile. The profile is where the technical settings for the harvest are determined. One or more schedules can be linked to a target, determining when the target is to be harvested.
Each harvesting of an Abstract Target leads to the creation of a Target Instance. A copy of the profile, schedule, and seeds at the time of harvest is stored with it, along with technical metadata about the harvest, such as the amount of data captured and number of URLs downloaded, and the number of failed URLs. The harvested files are stored in a WARC file (older ones in ARC files).
An Abstract Target could also represent a group. This would allow for a single schedule and profile to be set for multiple Abstract Targets and for them to be harvested either as a single Target Instance or as one target instance per group member. However, this functionality is not used much. The relationship between targets and collections is therefore not made in the Group Members table but usually as an annotation of a Target Record or in the Dublin Core subject field. Annotations are also used to document various other things such as important context information and internal comments.
Metadata in the Context of Digital Preservation
Web archiving is an attempt to preserve ephemeral digital-born content on the World Wide Web for future generations of researchers and the public. Digital asset management and preservation systems help us do that in a way that ensures the significant properties of the digital objects are unchanged and that the digital objects are preserved along with the necessary context information so that they can be understood in the long term by the designated community, and they document events in the lifecycle of the digital objects and their metadata so that their authenticity is indisputable. For this purpose, KB will be using Rosetta, an off-the-shelf preservation system offered by ExLibris.
Rosetta is OAIS compatible, implements PREMIS components, and uses the METS profile. Its data model (ExLibris, 2022) is represented in four hierarchical levels: the Intellectual Entity (IE), the Representation, the File, and the Bit-Stream. These can be nested to create more complex hierarchical structures consisting of structural and content IEs. IEs can be grouped using collections and subcollections. Collections were designed primarily for grouping data at the output to users. Collections are described with a slightly different METS file than IEs, and the link between an IE and its collection is realized through an attribute in the IE record. Structural IEs (SIE), on the other hand, are designed for modeling more complex hierarchical relationships between IEs. Instead of containing representations, a structural IE lists the IDs of related IEs and describes the type of relationship and order of the children. However, there is no link from the children to the parent IE. Neither a structural IE nor a collection can have files; those are stored only in content IEs (CIE).
Just as in WCT, descriptive metadata is recorded using Dublin Core. A Dublin Core record is linked to every IE and collection. These records will be populated with metadata in accordance with recommendations of the Web Archiving Metadata working group.
It is important to preserve the data of Target Instances as well as contextual information, especially documentation regarding web archive-wide practices and special collection curation. These are modeled as content IEs, and they are the foundations of the data model representing web archive content in Rosetta. The link between WCT Target Records and Target Instances is modeled by creating a SIE for the Target Record and linking the Target Instance CIE to it with a "has instance" relation. The instances can be ordered chronologically with sequential integers. There are multiple ways web collections can be modeled; the one with the highest semantic link and least duplication of metadata is visualized below in a diagram with examples of resources. Web Collections are also modeled using SIEs and linked with targets belonging to that collection with a 'has part' relationship and to documentation about it with a 'is described by' relationship. All resources relating to the KB web collection are then grouped using a top-level SIE with a differentiated relationship to KB web collections and web archive-wide documentation.
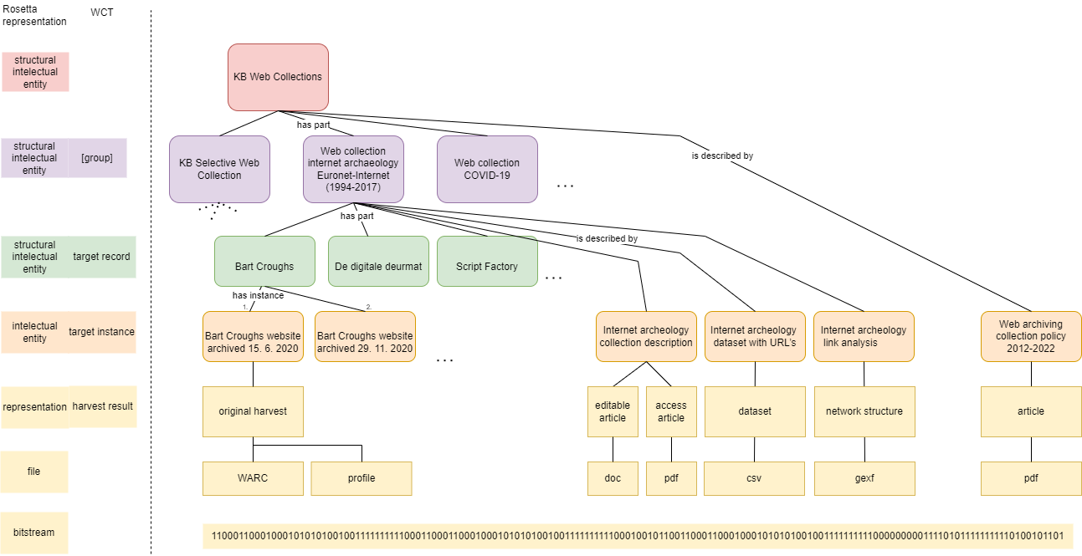
Figure 2: Web collection model
Metadata in a Bibliographic Context
Many national libraries take it upon themselves to preserve publications from and about their nation in an effort to preserve the country's national heritage. As many print resources moved online with the dawn of the World Wide Web, this was extended to websites as well through web archiving initiatives. Archived websites have thus become part of the library's collection and are managed from a bibliographic point of view. But are bibliographic models and standards truly applicable and useful for describing web archive collections? In this section, I apply the IFLA-LRM model using the RDA cataloging rules to see what insight they give us into the complex nature of archived websites and what consequences this has for bibliographic description in library metadata formats, such as MARC 21.
First, we need to understand the IFLA Library Reference Model (Riva, Le Bœuf, & Žumer, 2017). LRM is a high-level conceptual model of the bibliographic universe. The bibliographic universe is conceived broadly to include all resources collected by libraries, including archived websites. However, it was created with books specifically in mind.
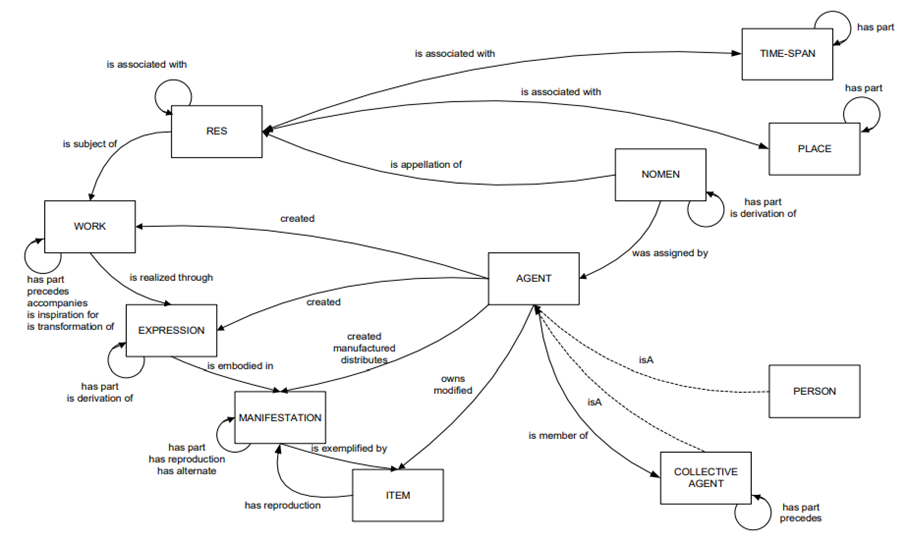
Figure 3: IFLA LRM entities and relationships (Riva, Le Bœuf, & Žumer, 2017)
The top-level LRM entity is Res; it can be used to represent anything. Significant subsets of Res are Works. A Work is an abstract entity relating to a distinct intellectual or artistic creation. It is realized through an Expression, which is characterized by a distinct combination of signs conveying the work. Expressions are embodied in Manifestations, a set of all carriers that share the same characteristics and can be considered mutually interchangeable. A single instance of a Manifestation is an Item. Expressions can be aggregated that is bundled together in a manifestation by an Aggregating Work. Another significant subclass of Res is an Agent, an entity capable of deliberate actions, being granted rights, and being held accountable for its actions. There are two subclasses of Agents, a Person, and a Collective Agent. A Person is any non-fictional human being, while a Collective agent is a gathering or organization of Persons working as a unit under a name. LRM distinguishes three more distinct subclasses of Res, Nomen, Place, and Time-span. A Nomen is a string that refers to a Res. They can arise from use within a cultural context or be assigned formally. Guidelines exist to distinguish between homonyms and for linking synonyms. The Place entity refers to real geographic places; however, the terms themselves are fuzzy. Time-spans can be very short (a single second) or very long (an epoch). They can be written in standardized machine-readable formats and used with Nomens to uniquely define Nomens. LRM also describes some key relationships between entities.
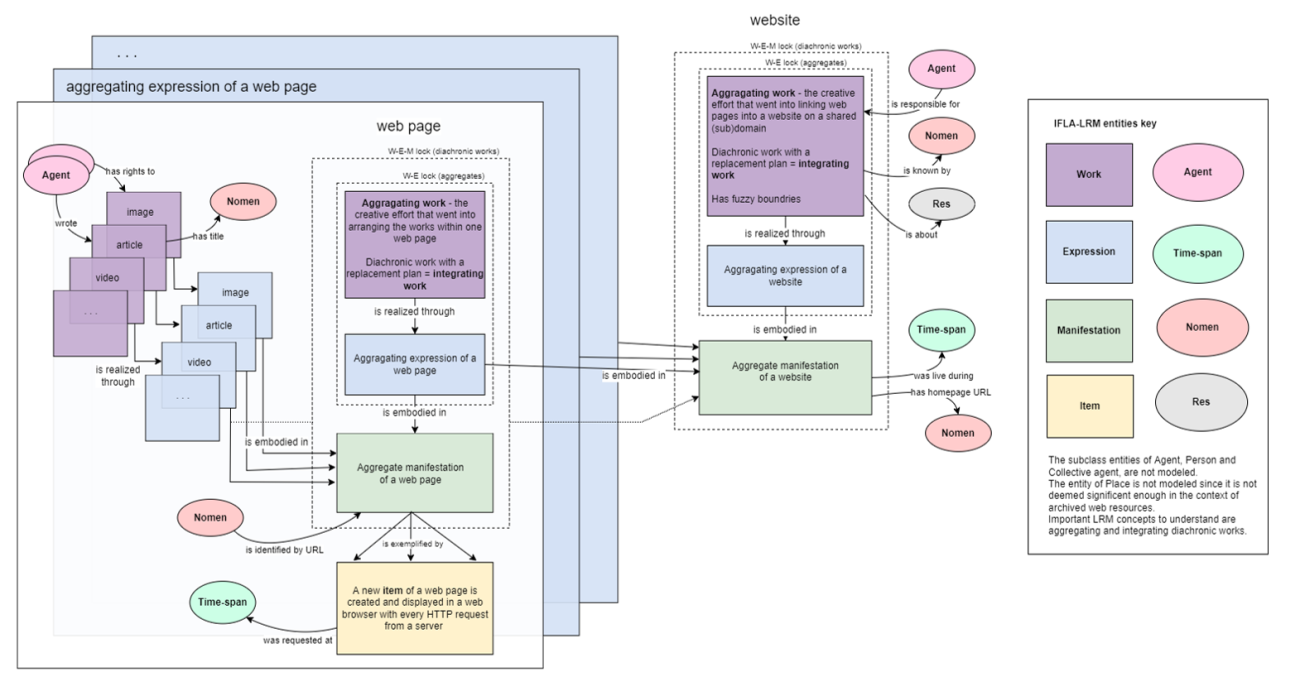
Figure 4: LRM model of live web pages and a live website
In these terms, each website is an aggregating work. Web pages are works aggregated in websites and aggregating any number of works - articles, images, videos, and so on. The aggregating work is the idea and intent to present certain works as a whole; the aggregated works are not part of the aggregating work. Aggregates are subject to a W-E lock. This means aggregating works can be realized through only one expression since the expressions of the selected aggregated works are essential in defining the aggregating work. Moreover, websites and web pages are diachronic works, that is, works planned to be embodied over time rather than in a single act of publication. Since this is realized through replacement rather than accumulation (as with print magazines, for example), we call them integrating works. Past iterations of integrating works are assumed to be inaccessible. Diachronic works are subject to a W-E-M lock; a diachronic work can therefore have only one manifestation. This is because a diachronic work is defined by its extension plan, and these could diverge for parallel expressions and manifestations. All relationships are therefore realized as work-to-work relationships. The aggregating work and aggregated works are embodied in a single aggregate manifestation that changes over time. The aggregate is embodied in a new item in a client's web browser with every HTTP request. Only aggregate web pages have items since an entire website cannot be embodied at once.
Trond Aalberg, Edward O'Neill, and Maja Žumer (2021) point out how the current LRM model is insufficient for modeling integrating resources, going as far as to say that "Applying the model unmodified to integrating resources is neither practical nor theoretically sound.". They propose the addition of two relationships which would make it possible to model the relationship between expressions and manifestations over time. This adds a great deal more expressive power to the model, especially in relation to web archiving. However, since it is not currently part of LRM, I am not modeling it explicitly. However, I could have done so easily by expanding expressions in time, as illustrated in the diagram below. We will return to this model in a later chapter regarding modeling in CRM.
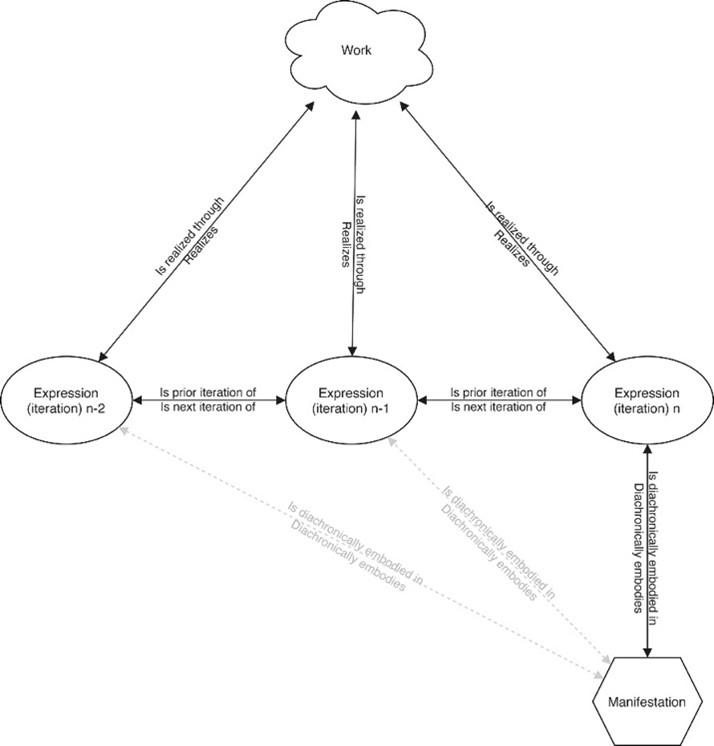
Figure 5: Modelling integrating resources in LRM (Aalberg, Edward, & Maja, 2021)
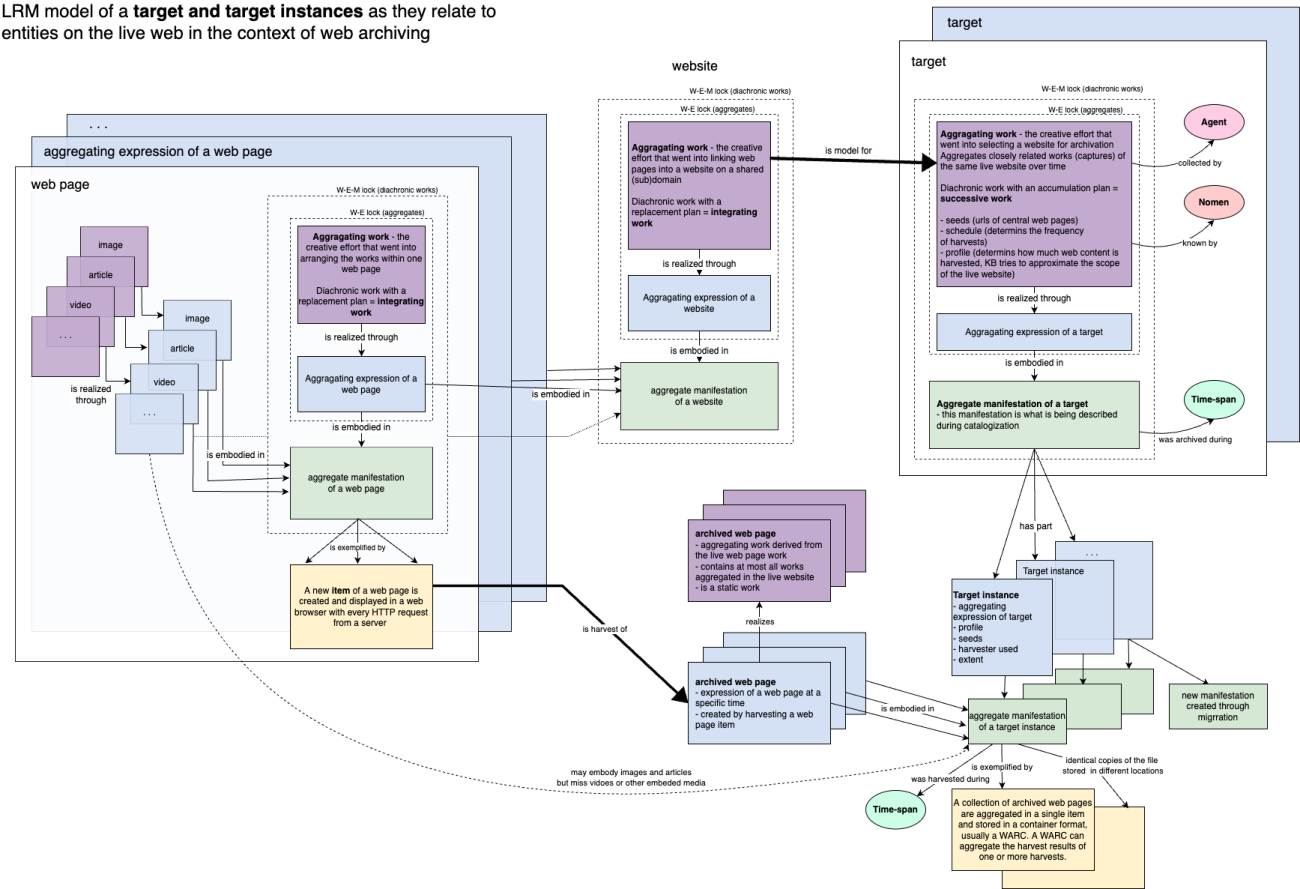
Figure 6: LRM model of a target and target instances
During web archiving, web pages are captured at specific instances. The process is highly transformative and creates a new, closely related work (archived web page). The web page is turned from an integrating resource into a static work containing, in the best case, all the same expressions as the live web page aggregate manifestation, but often just a subset. A collection of archived web pages approximately corresponding to a live website can be called a target and harvested at a set time as a target instance. A target is also a diachronic work, but with a successive plan defined by the harvest schedule and set by the collector. In bibliographic terms, each target instance can thus be thought of as an issue of a target.
To model web collections, we can take an analogous approach as for Rosetta and join targets to collections with a has part relation. Documentation about the collection is then modeled with work-to-work relationships. However, this works only when we conceive of the harvest as a collection of websites. For domain crawls and similar broad harvests, we find it more practical to think only on the level of web pages and by-step the concepts of a website and target entirely. Each harvest of the collection over time would then constitute a new "issue" of the web collection. Here it becomes even more important to understand how the harvest profile is set up. Curator-selected central URLs are called seeds, and the profile determines the depth of the harvest, that is, how many web pages the harvester will recursively harvest by following links.
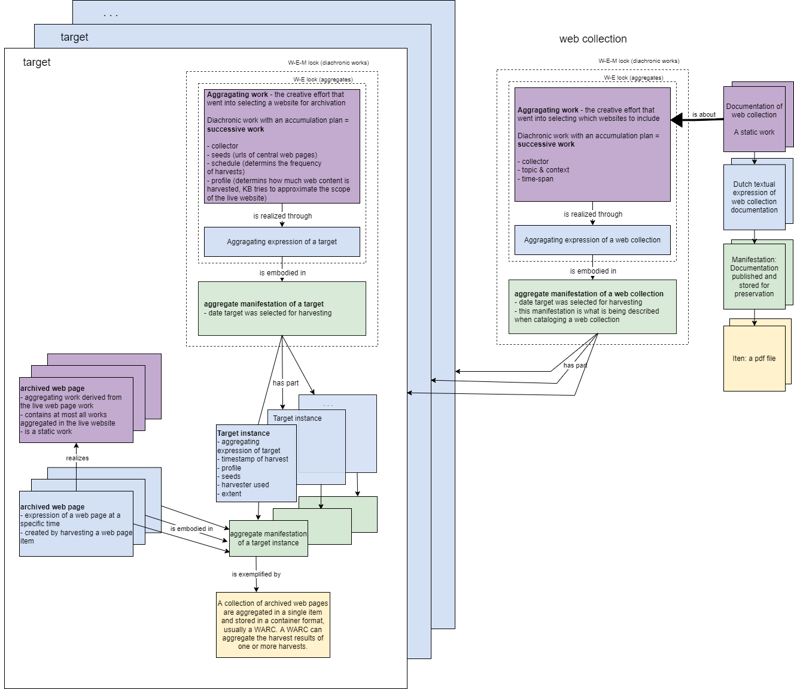
Figure 7: Modeling web collections as a collection of targets in LRM
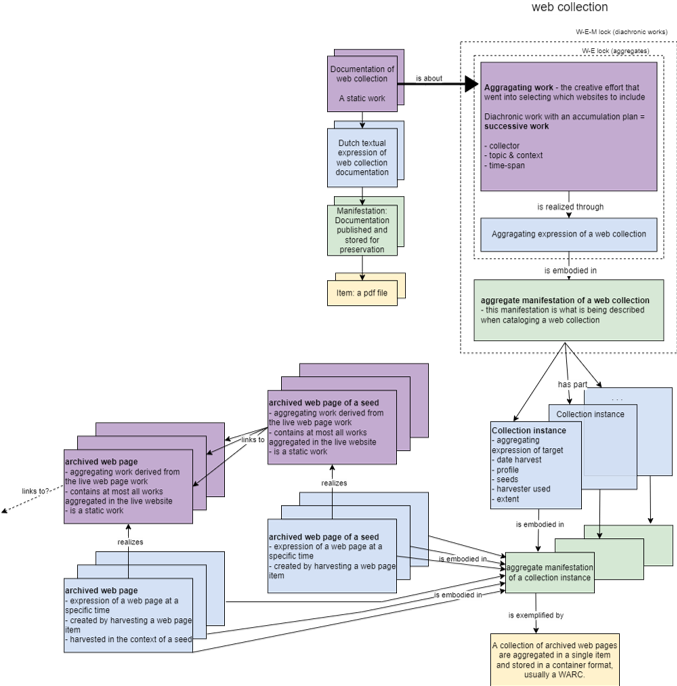
Figure 8: Modeling of web collections as sequences of captures in LRM
Websites, archived websites, and collections can all be modeled faithfully in IFLA-LRM. Doing so does bring some insight, especially to the separation of the live and archived websites, the consequences of website or web page-oriented collecting practices, and the question of what is being described (the website as a whole or the works on the website). RDA terminology also allows us to put the description of archived web pages into the context of other more traditional resources and thus benefit from the detailed cataloging rules developed from experience gained over the years in those communities. Since it was determined that an archived website (target) is a successive work, we will be looking to learn from the continuing resources community. However, specialists on continuing resources have been vocal about LRM not being detailed enough regarding serials. And these limitations apply to the domain of archived websites as well. A consequence of the WEM lock is that the granularity offered by the WEMI structure is lost and, with it, a significant amount of expressive power of the LRM model. It also does not give any insight into questions of how resources change over time, e.g., diverging, converging, ending, being revived, revamped, and passing hands. LRM introduces a lot of complexity making description challenging without introducing concepts that are useful to users.
Moreover, when describing archived websites in MARC 21, a metadata standard supported by Alma, the KB's new integrated library system, a lot of the complexity will inevitably be lost since it is not feasible to manually describe all of the entities identified here. Bibliographic description is typically done at the manifestation level and at least one expression embodied in it needs to be described. This will almost always be the aggregating expression of the web collection or target. The web content itself is, therefore, not described at all. In practice, a pragmatic decision to describe both the target and the live website in one record is often made (Dooley & Bowers, 2018, pp. 8-9), but this can lead to confusion in areas where the two diverge and goes against cataloging best practice.
Linking it All Together: Object Modeling in CIDOC-CRM
Could there be a model that is more expressive than LRM? And one that encompasses digital preservation as well? What if it had a compatible metadata format that could automatically extract entities and relationships from existing descriptive, administrative, and technical metadata? As far-fetched as this sounds, the CIDOC Conceptual Reference Modal may offer just that.
CIDOC-CRM (CIDOC CRM Special Interest Group, 2022) is a conceptual model developed by the international museum community and expressed as an ontology. The objects collected by museums are extremely diverse, and the metadata created about them varies dramatically in depth and scope. Cultural heritage institutions have extensive metadata but need a way to connect it across institutions and domains. Doing so with an entity-relationship approach proved unfeasible since it soon grew so complicated that it was unusable. That is why CIDOC-CRM is an event-centric object-oriented model. The model is extensible, so it can encapsulate any specialized practices and unconventional research questions yet can also coherently semantically connect these various contexts and allow researchers to discover new connections between holdings in cultural heritage (and beyond). Linked data is a major application domain of CRM.
An IFLA-LRM extension is currently being developed (International Working Group on LRM, FRBR and CIDOC CRM Harmonisation, 2021). However, an extension to LRM's predecessor, FRBR, already exists – FRBRoo (International Working Group on FRBR and CIDOC CRM Harmonisation, 2017). We can, therefore, reasonably assume that CRM does or will support the LRM mapping from earlier. Since it is likely users shall wish to look at archived websites not only as publications but also as complex cultural artifacts, the features offered by CIDOC-CRM on top of IFLA-LRM could be invaluable to users from different domains. A CRM-compatible model would also make it easy to interconnect the websites with a wide variety of different cultural artifacts outside of the library context. Moreover, the LRM analysis led us to the insight that archived websites are successive continuing resources, and an extension of CRM and FRBRoo specifically for them already exists, PRESSoo (PRESSoo Review Group, 2016). The main power that PRESSoo gives us that LRM does not have is the ability to model how serials transform over time since it sees statements about the past and assumptions about the future to be at the heart of serial works.
However, the biggest advantage of CRM is that it allows for the representation and integration of information with vastly different levels of specificity of description in a well-defined way.
Much of the work of extending the model to semantically represent websites has supposedly already been done. The aim of this chapter is to test this theory by representing archived websites as collected by KB in PRESSoo and identify whether extensions are necessary, and, if so, formulate the need for further research into these extensions. This is somewhat complicated by the models being under active development. Already from the currently published draft of LRMoo, it is clear that a number of classes were deprecated to simplify the model, some of which PRSSoo relies on. The team working on PRESSoo will be integrating these changes, but it is currently unclear precisely how. Overall, the trend is toward as much simplicity and flexibility as possible. Therefore, I will try to rely on as general concepts as possible while modeling archived websites and extend the models as little as possible.
CRM is an object-oriented model. It identifies classes, subclasses, and properties that link them. Subclasses inherit from parent classes. Properties are defined for classes in a given domain and range. Class properties are time neutral, and changes are represented as events. Top-level classes are quite abstract; some only exist because they are functionally required rather than being directly used. This abstractness allows for great expressive power.
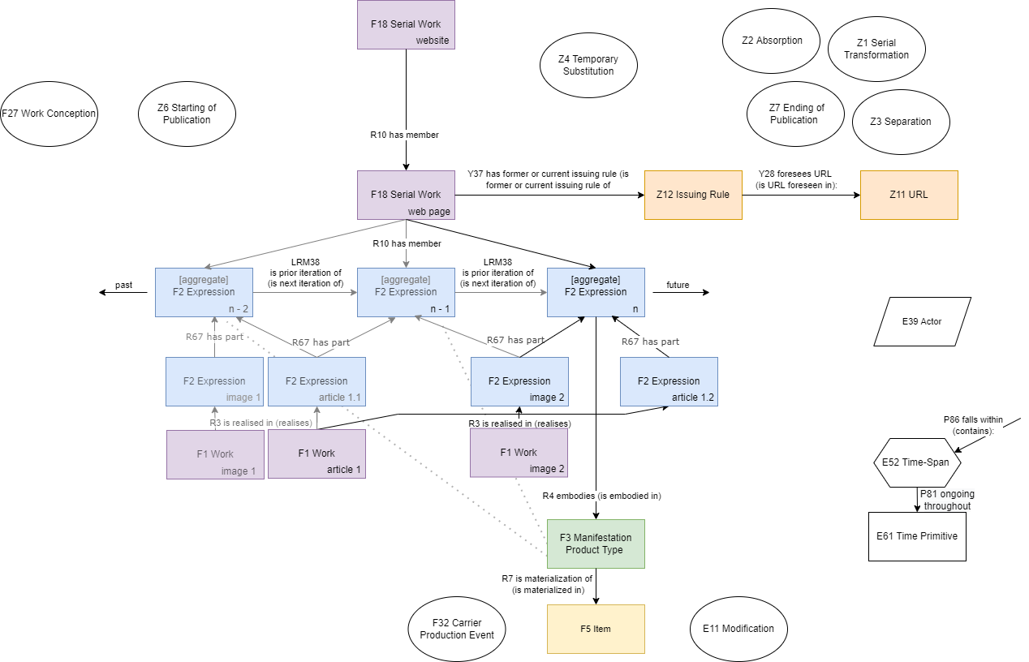
Figure 9: Extended CRM model of the live web
I would suggest modeling live websites as an instance of F18 Serial work. The scope note is broad enough to incorporate all continuing resources, not just serials. Websites have an R10 has member relationship to all web pages that have ever been part of it. The boundaries of websites can sometimes be unclear, but we usually include web pages that share a domain, subject, and publishing intent. Each web page is also modeled as an instance of F18 Serial work. Via the Z12 Issuing rule, it is linked to a Z11 URL. A web page also has an R10 has member relationship to all F2 Expressions that the web page has ever had. The first expression is theoretically created the moment the idea of the web page is conceived but is embodied only in the head of its creator. Z6 Starting of Publication marks the moment a web page goes live. Each update of a website causes the creation of a new expression. An F3 Manifestation product type exists only for the latest expression of a web page. An HTTP request is an instance of an F32 Carrier production event and results in the creation of an F5 Item on a user's computer. It may differ from the manifestation product type based on screen size, device and web browser used, whether the user blocks ads, and so on. An expression has an R67 has part relationship to the F2 expressions of F1 works that it aggregates. In PRESSoo, this would be modeled using Publication works, though I chose to follow the suggestions of Aalberg et al. instead and map directly to expressions.
We also need a class to represent an update. The E11 Modification class could be used, but that has a domain and range E24 Physical Human-Made Thing, which expressions do not inherit from, and it is impractical to model updating as a modification of items. This is why I use the property LRM38 is prior iteration of proposed by Aalberg et al. instead to link two successive web page expressions. This is just a shortcut for saying the server source code (an item that is a materialization of the manifestation which embodies expression one) was transformed by an actor, thus creating expression two while also replacing the manifestation.
A number of properties useful for modeling the evolution of continuing resources over time are available in the range of F18 Serial Work, namely F27 Work conception, Z6 Starting of publication, Z4 Temporary substitution (e.g., website outage), Z7 Ending of publication, Z2 Absorption, Z3 Separation, Z1 Serial Transformation. Even though designed for printed serials, I consider these classes sufficient for describing complex transformations websites and web pages undergo over time.
Web archiving is an inherently transformative process during which new objects are created from ones on the live web. It is important to represent the semantic relationship between the two but also their differences and the context in which they were archived. Thankfully we do have this information in crawl log files from Heritrix. If we could identify entities in them and the relationships between them in a widely used and understood ontology like CRM, we could automatically publish detailed and rich linked metadata about the collection in RDF. Users could then ask questions about content embedded in web pages, and our tools could make inferences about the evolution of entities on the live web. Not only is this approach more useful, but it is also more interoperable because it does not rely on higher-level conceptualizations that vary dramatically between archiving institutions.
To do so, we need to model the archived web content in much more granularity than in previous models, all the way down to individual archived files embedded in web pages. These are grouped with an as part relationship to a web page, and those have a semantic link to other web pages that link to it, all the way to the top of the tree hierarchy, to the seed. One or more related seeds are often grouped and assigned descriptive metadata, and these too can be mapped to RDF and allow us to enrich the structure with a bit more meaning and context. Once done, these mappings can be expanded with relative ease to web collections of other institutions, adding even more value. Given a good user interface, researchers could explore the open-linked data with more ease and even enrich it further with their domain knowledge.
Events play a crucial role in the model. They link classes together and provide context. We distinguish between a web archiving job and the harvests of individual web pages within it. We can expand an instance of the D7 Digital Machine Event from CRMdig, a CRM extension for provenance metadata and digitalization. This class inherits from Creation and Modification since it creates a new digital object and modifies a physical carrier to store the file. It has most of what is needed for representing web archiving but is missing some specialized properties to express the entire event. It has a seed list on the input, and one or more targets contribute seeds to it. A web harvesting event is restrained in time and consists of smaller Web Page Harvest Events. These are a subclass of creation. There is a URL on the input that requests a web page and harvests it and its embedded content, thus creating a digital object of a harvested web page with each harvested file being part of it. These are stored in a WARC file.
A target here is general and makes no assumption about what portion of the web it tries to approximate, which is specified in its metadata. It could be a target record approximating a website or a broad web collection. A target is represented by a serials class. This gives us the ability to represent events in its life cycle and changes in issuing rules. A new property is needed to differentiate between an access URL and a seed URL. Each harvest of a target creates a new member of the target resource, a target instance. A target instance item is materialized in a WARC file.
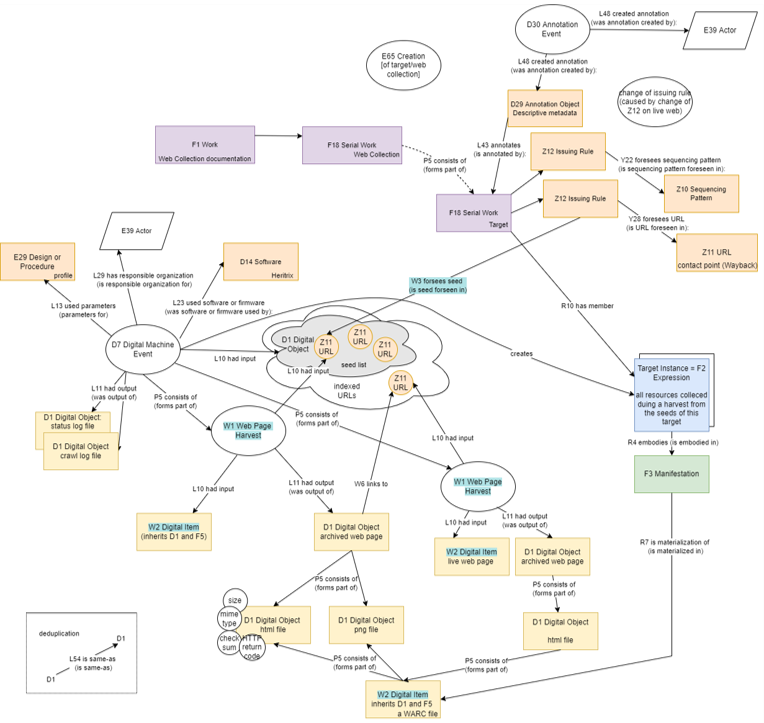
Figure 10: Extended CRM model of the archived web
The precise classes and properties used here are not final, and some still conflict with each other, e.g., E29 Design or Procedure cannot be the range of L13 used parameters. I tried to minimize the need for new properties and classes, but functional requirements may still require the definition of more. However, the aim of this section was not to formally define a CRM extension for web archiving but rather to identify the concepts that would need to be defined and consider the benefits and drawbacks of such an approach for web archive metadata. And in that, I think we were successful. Web archiving can be modeled in extended CRM with extraordinary detail with relatively minor additions. While somewhat more complicated to implement since it is a new approach to web archive metadata, a CRM-based open-linked data service is more flexible, scalable, automatable, and expressive than other approaches discussed. Thus, I would recommend looking into this option more in the future - consulting the mapping to the ontology with CRM experts, testing exports to RDF, and investigating developing a specialized information system on top of this data model to make it more user-friendly.
Conclusion
Thinking about web archive metadata in the context of high-level conceptual models from various fields helps us understand and visualize how we, as a web archiving community, conceive of the structure of the web, and this is present in the resources we collect and preserve. Understanding this is invaluable for safely preserving the work we have already done, understanding the confusion that arises from confusing entities with each other, and designing new and better services for our users. While this work is abstract and theoretical and less tangible than other approaches in the field, such as full-text search, I firmly believe it is an equally important and complementary effort. After all, more robust open and linked metadata formats would allow us to record and structure the insight gained from research into the archived web content itself.
References
Aalberg, T., Edward, O., & Maja, Ž. (2021). Extending the LRM Model to Integrating Resources. Cataloging & Classification Quarterly, 59(1), 11-27. doi:10.1080/01639374.2021.1876802
CIDOC CRM Special Interest Group. (2022, June). Definition of the CIDOC Conceptual Reference Model (Version 7.2.1.). Retrieved from CIDOC CRM: https://www.cidoc-crm.org/sites/default/files/cidoc_crm_version_7.2.1.p…
Dooley, J., & Bowers, K. (2018). Descriptive Metadata for Web Archiving: Recommendations of the OCLC Research Library Partnership Web Archiving Metadata Working Group. Retrieved from https://doi.org/10.25333/C3005C
ExLibris. (2022, June). Rosetta AIP Data Model (Version 7.3). Retrieved from ExLibris Knowledge Center: https://knowledge.exlibrisgroup.com/Rosetta/Product_Documentation/960_V…
International Working Group on FRBR and CIDOC CRM Harmonisation. (2017, September). FRBR object-oriented definition and mapping from FRBRer, FRAD and FRSAD (version 3.0.). Retrieved from CIDOC CRM: https://www.cidoc-crm.org/frbroo/sites/default/files/FRBRoo_V3.0.pdf
International Working Group on LRM, FRBR and CIDOC CRM Harmonisation. (2021, June). LRMoo (formerly FRBRoo) object-oriented definition and mapping from IFLA LRM (version 0.7). Retrieved from CIDOC CRM: https://www.cidoc-crm.org/frbroo/sites/default/files/LRMoo_V0.7%28draft…
PRESSoo Review Group. (2016, August). Definition of PRESSoo: A conceptual model for Bibliographic Information Pertaining to Serials and Other Continuing Resources (Version 1.3.). Retrieved from IFLA: https://www.ifla.org/wp-content/uploads/2019/05/assets/cataloguing/PRES…
Riva, P., Le Bœuf, P., & Žumer, M. (2017). IFLA Library Reference Model: A Conceptual Model for Bibliographic Information. IFLA. Retrieved from https://www.ifla.org/wp-content/uploads/2019/05/assets/cataloguing/frbr…
Web Curator Tool project contributors. (©2020). Data Dictionary. Retrieved from Web Curator Tool Documentation: https://webcuratortool.readthedocs.io/en/latest/guides/data-dictionary…

Author: Illyria Brejchova, under the supervision of Daniel Steinmeier
Date: 31. 8. 2022
Acknowledgments
This article was written as part of a two-month internship of Illyria Brejchova at KB in the summer of 2022, and it is an abridged version of her final report. Illyria is a master's student of Library and Information Science at Masaryk University, Czech Republic. She has prior experience from the web archive of the National Library Czech Republic and is currently writing her thesis on a related topic under the supervision of Michal Lorenz. At the KB, she was supervised by Daniel Steinmeier, a Koninklijke Bibliotheek (KB) specialist on digital preservation and metadata. During her internship, she consulted with many KB experts on web archiving, metadata management, digital preservation, and linked data, including but not limited to Iris Geldermans, René Voorburg, Meta van der Waal-Gentenaar and Kees Teszelszky.